1
Anatomía de la información digital
El escritorio que vemos al encender el ordenador contiene metáforas en su interfaz. Se trata del símil de situaciones y objetos que son propios del mundo real, más que del virtual. Conceptos como carpeta, documento y papelera ayudan a formarnos modelos mentales del funcionamiento del sistema a partir de objetos que ya nos son familiares y de los que conocemos el comportamiento. Incluso el mismo escritorio del ordenador es en sí mismo un símil de una mesa de trabajo.
Las interfaces gráficas que usamos actualmente, con su metáfora de escritorio, son herederas del sistema Star, concebido por Xerox en la década de 1970, cuya aportación principal fue relacionar representaciones abstractas digitales, tales como ficheros, subdirectorios e instrucciones de ordenador, con objetos del mundo real, tales como documentos, carpetas y acciones cotidianas. Así, la experiencia de trabajar en un escritorio real ayuda a familiarizarse con el modelo funcional de un ordenador, del que será fácil predecir el comportamiento.
Ahora, el concepto de formato digital puede entenderse igualmente por la vía de la metáfora mediante el símil de un envase. Sabemos que un envase es un recipiente que envuelve y contiene productos de consumo para conservarlos, transportarlos y consumirlos adecuadamente. De forma análoga, un formato digital es un contenedor de información que facilita su almacenamiento en una memoria digital, su transmisión a través de una red de telecomunicaciones y su uso en un sistema informático (por ejemplo, un ordenador o un teléfono móvil).
Así como los envases pueden ser de materiales distintos, tales como el cartón, el plástico, el vidrio, el metal o la madera, para poder manipular, usar, proteger y transportar convenientemente su contenido, existen distintos formatos digitales que codifican de diferente modo los diversos tipos de información para que esta se pueda tratar, transmitir y preservar de manera correcta. El diseño físico de los envases es, pues, una elocuente analogía de la estructura lógica de los ficheros.
Y aún hay más. Igual que los envases pueden proteger el contenido de forma que no pueda consumirse ni modificarse sin abrir o modificar el recipiente, algunos formatos disponen de métodos técnicos de protección, tales como los certificados digitales, la gestión de derechos digitales (DRM) o la restricción mediante contraseña para limitar ciertas acciones como la lectura, la copia, la modificación o la impresión.
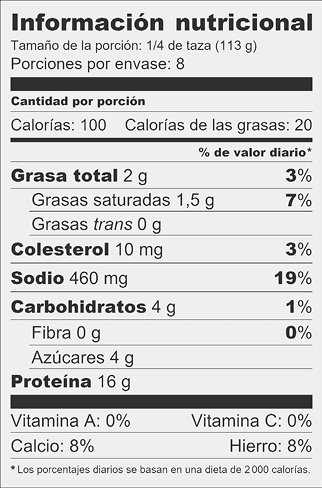
De igual forma, si consideramos que los envases no solo sirven para proteger y transportar el contenido, sino también para identificar el producto y controlar la cadena de trazabilidad, estas son igualmente funciones de los formatos digitales, que suelen contar con mecanismos para conocer la procedencia, las características y la ubicación de un fichero. Los alimentos envasados suelen incorporar en su envoltorio una serie de informaciones sobre su procedencia, sus ingredientes y su valor nutricional (figura 1). De manera equivalente, los ficheros digitales se apoyan en los metadatos para representar de forma sencilla ciertas propiedades sobre su contenido, por complejo que este sea.
Figura 1. La etiqueta de información nutricional de un alimento envasado
es un símil de los metadatos que describen propiedades de un fichero digital
Fuente: Jorge Franganillo
Los envases tienen varias formas y tamaños para adaptarse a distintas maneras de almacenar, transportar y consumir el contenido. Una garrafa puede ser un recipiente adecuado para almacenar agua en un hogar, pero no resulta apto para una excursión por la montaña, donde tendría más sentido llevar una botella pequeña o mediana, que además se puede guardar en una nevera. Lo mismo ocurre con los formatos digitales: los hay adecuados para determinadas situaciones de uso, y para cada situación hay, entonces, un formato adecuado.
El modo de distribución también presenta una analogía con los formatos digitales. Así como el agua es un recurso que se puede distribuir envasado o a través de una canalización, en una red de telecomunicaciones los contenidos audiovisuales se pueden obtener mediante descarga o mediante la reproducción en tiempo real (streaming). Ocurre lo mismo con la energía. La electricidad puede suministrarse a través de la red eléctrica o bien empaquetada en pilas o baterías.
Y esta diversidad de contenedores y de formas de distribución y consumo permite, además, diferenciar los sistemas de tarificación. Tal como se puede establecer el precio de los recursos físicos o energéticos según la forma como se entregan, lo mismo es aplicable para los recursos digitales.
Así pues, aunque los formatos digitales parezcan un concepto abstracto, tienen usos y propiedades similares a las de objetos y recursos cotidianos. Sabido esto, no resultará difícil comprender por qué la información digital se articula en una miríada de formatos y por qué cada uno de ellos contempla unas funcionalidades concretas: igual que en la vida cotidiana no hay un envase universal, en el ámbito digital tampoco hay un formato polivalente. Cada situación de uso condiciona qué características debe reunir el formato para que la información se pueda almacenar, transportar y utilizar de manera adecuada, fiable y segura.
1. Todo comienza con el bit
Un ordenador es, en esencia, un sistema de tratamiento de información, es decir, una máquina cuya función es tomar una información de entrada, procesarla y generar una información de salida. Para que pueda desempeñar su labor, la información que se le quiera suministrar debe traducirse a un «idioma» que el sistema pueda entender, y este es el lenguaje binario.
Los ordenadores son dispositivos digitales, es decir, están diseñados y construidos para operar internamente con toda la información codificada en dígitos binarios. La razón es que resulta relativamente sencillo construir circuitos electrónicos que generen solo dos niveles distintos de voltaje. Los transistores, los condensadores y la memoria, tres de los componentes fundamentales de los ordenadores, solo admiten dos estados: encendido y apagado.
Sobre este diseño biestable, la unidad más básica de representación de información que maneja cualquier dispositivo digital es el bit, representado con el símbolo b. Esta unidad puede adoptar un valor que representa una elección entre dos estados alternativos, como verdadero o falso, abierto o cerrado, encendido o apagado, blanco o negro (figura 2), aunque, por convención y por razones prácticas, a uno de estos estados se le ha asignado el símbolo 1, y al otro, el 0.
Los medios digitales utilizan combinaciones de bits para representar cualquier tipo de información. En un ordenador, un conjunto de bits tanto puede representar un texto, una fotografía, una grabación sonora o audiovisual, o una página web. Cualquier tipo de información, pues, está representado por bits, aunque en cada morfología los bits representan aspectos distintos. En un texto una serie de unos pocos bits puede representar un carácter (letra, cifra, signo de puntuación, etc.), mientras que en una fotografía puede indicar de qué color es un punto de la imagen.
A diferencia de un ordenador, los seres humanos percibimos el mundo por medio de señales que varían de manera continua en el tiempo. La luz, el sonido y la temperatura, por ejemplo, son señales analógicas. Pero los ordenadores solo contemplan dos estados de corriente, de modo que cualquier información que se quiera procesar en un ordenador deberá traducirse a una señal digital. Esa señal será una aproximación a la realidad; no será una representación tan exacta como la analógica.
Pero la digitalización tiene varias ventajas: la señal digital se puede tratar y manipular con más facilidad que una señal analógica, se puede reproducir y actualizar con relativa facilidad y, aparte, no deteriora la información con el tiempo, como sí lo hace una señal analógica, que además resulta difícil de reconstruir. En suma, pues, las señales digitales proporcionan una mayor capacidad para transmitir y procesar información.
Figura 2. Un código QR es una matriz de puntos blancos y negros que almacena datos codificados en lenguaje binario

Fuente: QR Code Generator
Un pequeño conjunto de bits puede representar ya un fragmento de información. La cantidad de bits que se utilice determinará la fidelidad de la representación. Las combinaciones que pueden hacerse con una serie de bits son el resultado de calcular la potencia de 2 elevado al número de bits (por ejemplo: 28 = 256; 224 = 16.777.216). Este cálculo es útil porque ayuda a comprender ciertas capacidades de un formato. Si sabemos que una imagen GIF se codifica con una profundidad de color de 8 bits/píxel, podemos deducir que cada punto de la imagen lo representan 8 bits y, por lo tanto, que el formato solo es capaz de representar hasta 256 colores distintos (el resultado de 28).
1.1. Unidades de medida de la información digital
Aunque el bit es la unidad básica de información, en las memorias informáticas (discos duros, discos ópticos, memoria RAM, memorias flash) la información se almacena en grupos de 8 bits denominados bytes, representados con el símbolo B (en mayúscula, para diferenciarlo de la b minúscula del bit). Históricamente, el byte era la cantidad de bits empleados para codificar un solo carácter de texto en un ordenador. De ahí que el byte sea hoy, en muchas arquitecturas informáticas, la unidad de memoria más pequeña a la que se puede asignar una dirección específica.
Dado que muchas situaciones implican enormes volúmenes de bytes, existen múltiplos de esta unidad para medir la información digital. Para ello se suelen usar los prefijos del Sistema Internacional, aunque con una equivalencia diferente de la estándar: se utilizan múltiplos de 1.024, en lugar de múltiplos del 1.000. La razón es que las memorias informáticas tienen una arquitectura binaria en la que los múltiplos se expresan como potencias de 2, y no como potencias de 10.
Tabla 1. Múltiplos del byte y su equivalencia decimal (Sistema Internacional) y binaria (IEC 80000-13)
|
Nombre |
Símbolo |
Equivalencia decimal |
Equivalencia binaria |
|
Kilobyte |
kB |
103 = 1.000 bytes |
210 = 1.024 bytes |
|
Megabyte |
MB |
106 = 1.000.000 |
220 = 1.048.576 |
|
Gigabyte |
GB |
109 = 1.000.000.000 |
230 = 1.073.741.824 |
|
Terabyte |
TB |
1012 = 1 billón |
240 = 1,1 billones |
|
Petabyte |
PB |
1015 = 1.000 billones |
250 = 1.126 billones |
|
Exabyte |
EB |
1018 = 1 trillón |
260 = 1,15 trillones |
|
Zettabyte |
ZB |
1021 = 1.000 trillones |
270 = 1.181 trillones |
|
Yottabyte |
YB |
1024 = 1 cuatrillón |
280 = 1,21 cuatrillones |
Ante esta dualidad de magnitudes, algunos fabricantes de dispositivos de almacenamiento digital y proveedores de servicios en nube se han adherido al sistema decimal porque les permite cuantificar la capacidad de sus productos con cifras más elevadas y, por lo tanto, más atractivas comercialmente, lo que provoca cierta confusión. Para normalizar la situación, la Comisión Electrónica Internacional aprobó en 1998 una nueva propuesta: los prefijos binarios (IEC 80000-13). Su uso no está aún muy extendido, pero gana popularidad con rapidez y cuenta con el apoyo de numerosos organismos de normalización.
Tabla 2. Propuesta de múltiplos del IEC 80000-13
|
Nombre |
Símbolo |
Factor |
|
Kibibyte |
KiB |
210 = 1.024 bytes |
|
Mebibyte |
MiB |
220 = 1.048.576 |
|
Gibibyte |
GiB |
230 = 1.073.741.824 |
|
Tebibyte |
TiB |
240 = 1,1 billones |
|
Pebibyte |
PiB |
250 = 1.126 billones |
|
Exbibyte |
EiB |
260 = 1,15 trillones |
|
Zebibyte |
ZiB |
270 = 1.181 trillones |
|
Yobibyte |
YiB |
280 = 1,21 cuatrillones |
Ciertamente, los medios digitales pueden representar cualquier cuerpo de información, y en cualquier morfología: texto, datos, imagen, sonido, vídeo, y formas derivadas o combinadas como, por ejemplo, páginas web, animaciones, modelos tridimensionales o vídeo con subtítulos. Para que pueda cumplir con sus objetivos, la información digital se almacena y se transmite en una amplia variedad de formatos. Cada formato es una convención y, al mismo tiempo, un contenedor que permite estructurar y encapsular información digital de cualquier tipo.
2. Fichero, documento, firma digital, formato y aplicación
En el contexto de un sistema informático, entre los componentes físicos (placas, circuitos, pantallas, conectores, etc.) que constituyen el hardware y la persona que usa el sistema, hay un conjunto de elementos intangibles que resultan esenciales para que el sistema tenga un propósito. Tales elementos son el software y conforman los componentes lógicos necesarios para realizar tareas específicas.
Para una adecuada gestión de los formatos digitales, es vital comprender las nociones de fichero, documento, firma digital, formato y aplicación, como también lo es conocer las estrategias y herramientas disponibles para identificar formatos.
2.1. Fichero
Para que un conjunto de bits se pueda procesar como un cuerpo de información, debe encapsularse en un fichero. Un fichero es una entidad lógica compuesta por una secuencia de bits empaquetada y almacenada en un dispositivo duradero (disco duro, disco extraíble, memoria USB, tarjeta de memoria, etc.) o en una memoria volátil, o bien transmitida como un flujo de datos en una red de telecomunicaciones.
Dado que los dígitos binarios pueden representar cualquier información, el sistema operativo y cada aplicación se ocupan de entender el esquema interno y el significado de la información contenida en el fichero, y de presentarla como lo que es (texto, datos, imagen, sonido, vídeo o partes ejecutables de un programa), de forma que tenga significado.
Los ficheros se identifican con un nombre y una extensión (esta no necesariamente visible para el usuario) y tienen atributos, es decir, propiedades como, por ejemplo, la fecha de creación, los permisos (modificable, oculto, etc.), o el peso.
2.2. Documento
De acuerdo con la Ley 16/1985 de Patrimonio Histórico Español (artículo 49.1), un documento es «toda expresión en lenguaje natural o convencional y cualquier otra expresión gráfica, sonora o en imagen recogidas en cualquier tipo de soporte material, incluso los soportes informáticos». Según esta definición, un documento digital puede entenderse como la representación digital de un cuerpo de información diseñado con la capacidad y la intención de comunicar.
En el ámbito informático, un documento es un fichero que alberga contenido creado por un usuario mediante un programa de ordenador o una aplicación móvil. Son varios los tipos de fichero que se manejan en un ordenador (ficheros ejecutables, ficheros de sistema, etc.), pero se consideran documentos solo aquellos que contienen información directamente utilizable y manipulable por una persona si dispone del software adecuado.
En el ámbito de la preservación digital se emplea el término objeto como una forma genérica de denominar cualquier documento o dato en formato digital. Los objetos digitales se conciben, pues, como algo con lo que se interactúa cotidianamente, por lo que es necesario pensarlos como extensiones de la idea clásica de objetos naturales (Hui, 2012).
Según establece la Ley 11/2007 de Acceso Electrónico de los Ciudadanos a los Servicios Públicos, las administraciones públicas pueden emitir documentos administrativos válidos en formato digital siempre que incorporen una o varias firmas electrónicas e incluyan una referencia temporal (sellado de tiempo o marca de hora).
2.3. Firma digital
En el ámbito informático, la firma digital sustituye la manuscrita y proporciona mecanismos criptográficos para certificar la autenticidad e integridad de un mensaje o documento digital. Se trata, pues, de un mecanismo de cifrado que acredita quién es el verdadero emisor de un documento (autenticación) y que el mensaje no ha sido alterado desde su emisión (integridad). Tras este mecanismo hay un certificado u organismo que valida la firma y la identidad de la persona que la realiza.
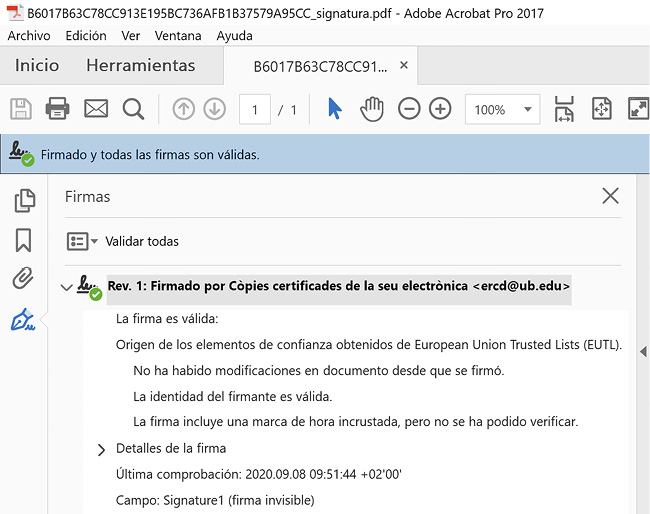
Todas las firmas digitales son electrónicas, pero no todas las firmas electrónicas son digitales. La firma electrónica es un concepto jurídico relativo a la identificación de una firma manuscrita, como la que se rubrica con un lápiz electrónico sobre una tableta digitalizadora. La firma digital, en cambio, consiste en una breve cadena de bits que se anexa a un mensaje o documento digital para demostrar su validez. El contenido de esa cadena binaria lo determina un algoritmo matemático conocido como función hash o función resumen. Mediante este algoritmo, el contenido del documento se convierte en una huella digital única y distintiva, de modo que la más mínima variación en el contenido frustraría su correspondencia con la cadena resumen y revelaría, en consecuencia, el intento de manipulación. Así pues, al apoyarse en sistemas criptográficos, la firma digital constituye un sistema robusto, seguro y confiable, capaz de certificar que un documento no ha sido modificado respecto del original (figura 3).
Figura 3. Una firma digital acredita la autenticidad e integridad de un documento
Fuente: captura de pantalla de Adobe Acrobat Pro
En el territorio de la Unión Europea la firma electrónica la regula el Reglamento (UE) n.º 910/2014 del Parlamento Europeo y del Consejo, que contempla varios tipos de firma y, por lo tanto, varios niveles de confianza, según si la firma cuenta con algún tipo de certificado y, en caso afirmativo, según si el certificado está cualificado, es decir, alojado en una tarjeta criptográfica (por ejemplo, el DNI electrónico) o generado por un servidor seguro.
Para demostrar que un documento o una serie de datos existen y no se han alterado desde un momento dado, se utiliza el sellado de tiempo, un servicio esencial de apoyo a la firma digital. Lo otorga una autoridad de sellado de tiempo, un prestador de servicios de certificación que proporciona esa certeza como tercera parte de confianza.
Con los años, la firma digital ha incorporado nuevas funcionalidades. Ello explica que hoy existan muchos formatos de firma (por ejemplo, CAdES, XAdES y PAdES) que se diferencian entre sí por la forma de generar, estructurar y guardar la información de firma. Aunque hay muchos tipos de firma, interesa distinguir, sobre todo, entre dos: la firma nativa y la no nativa.
La firma nativa consiste en realizar el proceso de firma con el mismo programa o aplicación con el que se creó el documento. Como la firma se incrusta en el mismo documento, presenta una ventaja: es un formato cómodo de almacenar. Pero es un método que solo admiten unos pocos formatos de documento, siendo los más comunes PDF, XML, FacturaE y las familias Office Open XML (Microsoft Office) y ODF (OpenOffice).
La solución para firmar cualquier formato de documento es usar una firma no nativa (firma despegada, envuelta o envolvente). El proceso de firma, en este caso, genera un fichero nuevo, en un formato específico del programa de firma empleado, que contiene el documento original y además la firma digital. Un ejemplo de este método se encuentra en la aplicación AutoFirma, del Ministerio de Industria, Comercio y Turismo, que permite generar un fichero de firma (con extensión .xsig) sobre cualquier tipo de documento.
El portal CEF Digital, por su parte, ofrece una demo denominada DSS1 desde la que es posible validar firmas digitales. La Comisión Europea proporciona esta biblioteca de software de código abierto a fin de garantizar que las firmas se generen y se verifiquen de acuerdo con las leyes y los estándares europeos.
2.4. Formato
Como las memorias informáticas solo pueden almacenar bits, los ordenadores han de poder convertir la información en dígitos binarios, y viceversa, para poder guardarla y transmitirla manteniendo todo su sentido. Se necesita, pues, un acuerdo sobre cómo se debe convertir una morfología cualquiera (texto, datos, imagen, sonido o vídeo) en bits, y a la inversa. Esta función la desempeñan los formatos.
Un formato es una convención que establece una codificación estructurada de datos para su gestión y representación por medio de un programa informático. Así, cada formato es una manera particular de codificar y estructurar la información para poder almacenarla en una memoria digital o transmitirla en una red de telecomunicaciones.
Información de representación
Dado que los objetos digitales se almacenan como flujos de bits, no son comprensibles para los seres humanos si no se dispone del conocimiento necesario para interpretarlos. Aquello que convierte los bits en un contenido con significado es lo que se denomina información de representación, y abarca información estructural y semántica explicada en la especificación del formato (Giaretta et al., 2005; CCSDS, 2012).
El contenido de un libro impreso, por ejemplo, se expresa por medio de los caracteres observables (los datos) que, al combinarse con el dominio del idioma utilizado (la base de conocimiento), se convierte en información significativa. Si el texto está escrito en alemán, pero el destinatario desconoce el idioma, entonces el texto en alemán (los datos) requerirá de una gramática alemana y de un diccionario de alemán (o sea, la información de representación) para convertir el texto en una forma que sea comprensible para el destinatario utilizando su base de conocimiento.
Los datos binarios se convierten así en contenido significativo y utilizable mediante la información de representación. Esta no debe confundirse con los metadatos, cuya función es describir el contenido y las propiedades técnicas y administrativas de un fichero.
Identificadores de formatos
Existen varios esquemas destinados a identificar cada formato de forma inequívoca. Según el contexto, se emplea un esquema u otro, cada uno diseñado para cumplir con una función específica. Dos de los más extendidos, aplicados en entornos distintos, son los tipos MIME y los identificadores PRONOM.
Tipos MIME
Este esquema, hoy alimentado por la IANA (Internet Assigned Numbers Authority), deriva del estándar MIME (Multi-purpose Internet Mail Extensions), una serie de convenciones para el intercambio de ficheros a través de Internet. Incluye una nomenclatura de tipos de contenido que identifica cada formato según su naturaleza y ayuda a que los ficheros, marcados con el correspondiente identificador de formato, se abran con la aplicación adecuada.
Cada identificador es un binomio que señala el tipo y subtipo de contenido (text/html, image/png, audio/ogg, video/H264, etc.). El tipo no es más que una categoría de alto nivel que representa una agrupación lógica (text, image, audio, video, etc.). El subtipo es más específico (html, png, ogg, H264, etc.) e identifica el formato, aunque de manera genérica; este método no distingue subformatos y, por ejemplo, todos los documentos PDF, con independencia de si son PDF 1.x, PDF/X o PDF/A, tienen asignado el mismo identificador: application/pdf.
PRONOM Persistent Unique Identifier (PUID)
Esta nomenclatura es un esquema extensible de identificadores para registros del PRONOM Technical Registry, el registro de formatos creado por los Archivos Nacionales del Reino Unido para identificar el formato en que está codificado un objeto digital y respaldar así los servicios de preservación digital. Con este objetivo, esta nomenclatura fue adoptada como esquema recomendado en el e-Government Metadata Standard británico y se emplea, por ejemplo, en la aplicación DROID para identificar formatos dentro de un lote de ficheros.
Como este esquema está orientado a la preservación a largo plazo, es más específico que los tipos MIME y suele distinguir entre las distintas versiones de un mismo formato. Solo del formato PDF, por ejemplo, hay cerca de cuarenta identificadores, uno para cada subformato: fmt/14 (PDF 1.0), fmt/15 (PDF 1.1), fmt/16 (PDF 1.2), etc.
Tipos de formatos
Han surgido diversos proyectos de clasificación con el propósito de favorecer la correcta identificación de todos los formatos existentes. Los registros de formatos cumplen una función importante en el contexto de las colecciones digitales porque, de cada formato existente, proporcionan la información autoritativa que permite leerlo, convertirlo o emularlo.
A pesar de esta disparidad de proyectos, se pueden identificar varias tipologías básicas, o comúnmente empleadas, de formatos.
Según la codificación del contenido, se puede hacer una primera distinción entre formatos de texto llano y formatos binarios.
Un formato de texto llano está estructurado como una secuencia de líneas de texto y legibles de forma transparente desde cualquier editor de texto llano. Entran en esta categoría los ficheros de texto estructurado (por ejemplo, RTF, CSV, y XML y todos sus derivados), cuyas marcas estructurales se escriben con caracteres imprimibles y son fácilmente interpretables.
Aunque, por definición, todos los formatos digitales son binarios, pues todos los ficheros son una secuencia de bits, se denominan binarios los formatos cuyo contenido incluye cadenas de bits que no representan texto llano. En general, los ficheros en formatos binarios solo son legibles o reproducibles en el programa que los creó o mediante programas similares. PSD, por ejemplo, es un formato nativo de Adobe Photoshop, pero también pueden leerlo otros programas de retoque fotográfico.
Según la propiedad, hay formatos propietarios, que están protegidos por una patente de software, y también formatos abiertos, que se pueden generar, distribuir y usar sin restricción alguna.
Los formatos propietarios están definidos y controlados por intereses privados. No cuentan con una especificación pública que explique cómo está estructurado el formato. Nadie puede desarrollar aplicaciones que permitan leerlo y manipularlo sin la autorización del desarrollador o sin pagarle unos royalties. Por esta razón suelen ser formatos binarios, legibles solo por máquinas: para prevenir la ingeniería inversa y evitar que se pueda deducir la estructura del formato con un simple análisis de su contenido.
A estos formatos se los denomina también privativos porque privan de ciertas libertades. Una persona puede «poseer» la información contenida en un fichero, pero solo puede extraerla con el software controlado por el proveedor, lo que, en la práctica, le da al proveedor el control de esa información y al usuario le genera una dependencia denominada confinamiento propietario. Esta situación resulta problemática porque compromete el acceso al contenido de los ficheros. Si el fabricante del software decide interrumpir su desarrollo, el usuario puede perder su información por el hecho de que el único programa capaz de extraerla deja de estar disponible o se vuelve incompatible.
Los formatos abiertos, en cambio, cuentan con especificaciones publicadas por alguna organización de estándares abiertos y están libres de restricciones legales de uso. Precisamente para facilitar su adopción, a menudo son formatos de texto llano porque así resultan más transparentes. El objetivo de los formatos abiertos es garantizar el acceso a largo plazo a los datos sin la incertidumbre provocada por las patentes del software de acceso y por la incierta disponibilidad futura de esa tecnología.
En línea con esta filosofía, un objetivo secundario de los formatos abiertos es impedir que una sola organización controle el formato y dificulte el uso de los productos de la competencia. Por estos motivos, los gobiernos y las empresas privadas apuestan cada vez más por el uso y el desarrollo de formatos abiertos. Pero aquí no debe confundirse la noción de formato abierto con el hecho de que el software sea gratuito; no hay una relación directa. Adobe Acrobat y los programas incluidos en Microsoft Office son ejemplos de aplicaciones propietarias que manejan formatos abiertos.
Según la morfología de la información se pueden agrupar los tipos de formato en:
• Datos: por ejemplo, CSV, XML, Microsoft Excel (XSLX), Microsoft Access (ACCDB).
• Texto (llano o con formato): por ejemplo, TXT, RTF, Microsoft Word (DOCX), Open Document (ODT), PDF, HTML.
• Imagen: por ejemplo, GIF, PNG, JPEG, TIFF, WebP, SVG, Adobe Illustrator (AI).
• Sonido: por ejemplo, WAV, MPEG-3 (MP3), Windows Media Audio (WMA), Advanced Audio Coding (AAC), FLAC, Ogg, MIDI.
• Vídeo: por ejemplo, MPEG-4 (MP4), QuickTime (MOV), Matroska (MKV).
Existen otras agrupaciones de formatos, como, por ejemplo, la clasificación por propósito, sugerida por el proyecto DELOS y la Digital Preservation Coalition (Guercio y Cappiello, 2004), o la tipología por la gestión a largo plazo, diseñada por el United Kingdom Data Archive, que además proporciona recomendaciones sobre los formatos y el software más adecuados (Van den Eynden et al., 2011).
Formatos de proyecto
En el ámbito multimedia también son comunes los denominados formatos de proyecto, que almacenan la estructura del proyecto y referencias a los materiales que lo componen. Este tipo de formatos sustentan el flujo de trabajo de la aplicación específica que los genera, especialmente en las fases de producción y posproducción, y no suelen ser compatibles con ningún otro programa. Para que el fruto de un proyecto pueda utilizarse en otros contextos, esto es, fuera del programa en el que se produce, debe exportarse a un formato gráfico, sonoro o audiovisual apto para la difusión. A este efecto, las aplicaciones suelen proporcionar varias opciones de exportación.
Cada aplicación multimedia determina qué elementos guarda en sus ficheros de proyecto y cómo los estructura. El editor de audio Audacity, por ejemplo, almacena cada proyecto en un fichero .aup3, que aloja los materiales sonoros empleados, junto con la información estructural de pistas, clips, etiquetas, puntos de envolvente y otros datos del proyecto. El editor de vídeo DaVinci Resolve, en cambio, no guarda cada trabajo en un fichero separado, sino que los almacena todos en una base de datos local (un fichero .db). De cada proyecto, la base de datos aloja todas las decisiones de edición (cortes, fundidos, correcciones de color, etc.), pero no los materiales audiovisuales, de los que solo se consigna una referencia, ya que suelen ser ficheros pesados.
Estrategias para identificar formatos
Los diversos tipos de formatos digitales se pueden reconocer mediante tres mecanismos: extensión del fichero, estructura interna y registros de formatos.
Extensión del fichero
El mecanismo de identificación más sencillo y común consiste en observar la extensión del fichero, un sufijo añadido tras el nombre del fichero y precedido de un punto (por ejemplo, .docx, .html, .mp4). Este elemento permite a los sistemas operativos identificar rápidamente el tipo de fichero y procesarlo de manera adecuada.
Como mecanismo de identificación, este es rápido y portátil. Pero resulta poco fiable porque es fácil cambiar la extensión de un fichero, que además puede ser ambigua (por ejemplo, .bin, .dat y .nfo están asociadas a más de un tipo de información). Y es también poco informativo, ya que no distingue entre las posibles versiones o aplicaciones de un mismo formato (por ejemplo, .xml, por sí sola, no revela qué aplicación concreta de XML articula la información).
Estructura interna
Los tipos de fichero más complejos suelen tener asociada una especificación rigurosa del formato. Los formatos binarios a menudo incluyen en el encabezado de los ficheros una cadena exacta de bits que ayuda a identificar o verificar el formato de un fichero. Esos valores binarios fijos se conocen como números mágicos y actúan a modo de firmas distintivas capaces de informar incluso de aspectos específicos como, por ejemplo, el tamaño del fichero o el método de codificación.
Los números mágicos son frecuentes en el ámbito del multimedia, donde es habitual el código FourCC, una secuencia de cuatro bytes que identifica el formato o el códec de un fichero. Entre los formatos de vídeo es habitual encontrar identificadores de cuatro caracteres como, por ejemplo, «DIVX» o «H264», que informan del método de descompresión de datos que debe utilizarse para reproducir el contenido.
Registros de formatos
Por último, existen bases de datos que reúnen todas las especificaciones de formato que actualmente se conocen. La tarea de identificar y validar formatos está expuesta al hecho de que los nuevos formatos evolucionan continuamente mientras que los antiguos se abandonan. De ahí que un registro de formatos, con información útil sobre las relaciones entre distintos formatos, sobre diferentes versiones de formato y con información de migración específica, sea de gran utilidad para la preservación de material digital (Roberts, 2011).
Con este propósito se han establecido algunas iniciativas destacables, aunque no todas ellas siguen vigentes:
• Global Digital Format Registry (GDFR): una propuesta conjunta de las Harvard Libraries (2005), OCLC y la Mellon Foundation (abandonada).
• PRONOM: el registro de formatos creado por los Archivos Nacionales del Reino Unido (The National Archives, 2006).
• Unified Digital Format Registry (UDFR): un intento del University of California Curation Center (2012) de unificar GDFR y PRONOM (abandonado).
• Representation Information Registry Repository: del Digital Curation Centre (2007) británico (abandonado).
• Sustainability of digital formats: un sitio web de la Library of Congress (2021) sobre formatos digitales.
Herramientas para identificar formatos
Existen varias aplicaciones informáticas destinadas a identificar y validar formatos:
• DROID: desarrollada por los Archivos Nacionales del Reino Unido, es una herramienta de software para ejecutar identificaciones de formatos por lotes, utilizando como referencia el registro PRONOM, descrito antes.
• Metadata Extraction Tool: desarrollada por la Biblioteca Nacional de Nueva Zelanda, actúa de forma similar y además examina la cabecera de los ficheros para extraer sus metadatos.
• JHOVE: desarrollada por la Biblioteca de la Universidad de Harvard y la biblioteca digital JSTOR, es capaz de identificar tipos de fichero y además ejecutar una validación completa.
• FOCA: desarrollada por ElevenPaths, es una herramienta destinada a extraer metadatos de documentos, principalmente de tipo ofimático, almacenados de forma local o remota.
Como complemento a estos programas, existen también listas de extensiones destinadas a resumir las características técnicas de cualquier formato. De cada uno suelen indicar quién es el creador, en qué estándares se basa, cómo estructura la información, a qué usos se destina y qué aplicaciones móviles o de escritorio pueden abrirlo. Son ejemplos de ello los sitios FileInfo,2 FILExt3 y FileFormat.4
2.5. Aplicaciones
Para que los ficheros cumplan con su objetivo, se han de poder crear, leer, visualizar o modificar de algún modo. Para todo ello se emplean aplicaciones informáticas, programas de ordenador diseñados para realizar una tarea específica o un conjunto de tareas. Son ejemplos de aplicaciones un procesador de texto, un gestor de bases de datos, un reproductor de medios o un navegador web.
Cada aplicación suele estar especializada en un tipo de información y puede tratar varios formatos. Un programa de retoque fotográfico está especializado en la manipulación de imágenes y, en línea con este propósito, puede manejar docenas de formatos gráficos. Y un reproductor, destinado a mostrar contenidos audiovisuales, es capaz de reproducir numerosos formatos de imagen, sonido y vídeo.
Aunque hay aplicaciones de varios tipos, conviene distinguir, sobre todo, entre las que sirven para ver contenido (lectores de documentos, navegadores web y reproductores de medios) y las que sirven, además, para crearlo y modificarlo. Las aplicaciones lectoras suelen ser programas gratuitos y a menudo incluyen la posibilidad de comentar o imprimir contenido.
3. Modelo de referencia OAIS
Recursos valiosos, como las estadísticas y los informes, entre muchos otros, son resultado de la actividad diaria de las personas y del conocimiento que de ello se deriva. Con cada vez más frecuencia, estos recursos son digitales en origen, es decir, ya nacen en un formato digital. Cabe preguntarse si deben ser conservados y, si fuera así, de qué modo y durante cuánto tiempo. Pueden ser recursos de carácter cultural o educativo, pueden englobar información de diversas áreas del conocimiento, y pueden ser de naturaleza técnica, artística o administrativa. En cualquier caso, al ser productos de origen digital y no contar necesariamente con un soporte físico, como el papel, requieren de medidas específicas de preservación.
La preservación digital se define como el conjunto de prácticas y acciones concretas de naturaleza política y estratégica destinadas a garantizar el acceso a los objetos digitales a largo plazo. Pero es necesario preguntarse si realmente hay que conservarlo todo. La respuesta que ofrece la Unesco (2003) es que no todo merece ser preservado. Según sostiene en sus Directrices para la preservación del patrimonio digital (artículo 5.2.1), «el patrimonio digital está constituido únicamente por aquellos [objetos digitales] que se considera que tienen un valor permanente». El primer punto de un plan de preservación consiste entonces en definir qué se debe preservar y por cuánto tiempo, y esta decisión debe ser fundamentada, coherente y responsable.
Pero esto plantea al menos dos interrogantes. Primero: ¿cómo se puede asegurar el acceso en un entorno tecnológico tan cambiante? Es necesario contar con repositorios digitales que permitan custodiar y recuperar a largo plazo los documentos que generan en soporte digital. Y segundo: ¿qué características debe reunir un sistema de preservación digital y qué funciones debe cumplir?
Las respuestas llegaron de la NASA, un organismo cuya actividad se apoya en la reutilización de datos conservados del pasado. Tras algunos errores en su custodia, esta agencia tomó conciencia de la necesidad de replantear la preservación de datos a largo plazo y desarrolló un modelo teórico que integraría las funciones que debería cumplir cualquier depósito digital destinado a la preservación a largo plazo. El modelo se discutió y se aprobó en el seno del Consultative Committee for Space Data Systems (CCSDS, 2012), un organismo de discusión y desarrollo de estándares para sistemas de información y datos espaciales, y adoptó el nombre de Reference Model for an Open Archival Information System (OAIS, modelo de referencia para un sistema abierto de información de archivo).
Publicado en 2003 y sometido después a una revisión menor, OAIS se estandarizó como una norma ISO (14721:2012).5 OAIS es un modelo teórico que indica qué funciones han de sustentar los sistemas de preservación digital, sin importar qué tipo de datos custodian ni a qué tipo de actividad u organización dan apoyo (Térmens, 2013). En términos generales, el modelo OAIS proporciona:
• un marco para la concienciación y la comprensión de los conceptos de archivo necesarios para la preservación y el acceso a la información digital a largo plazo;
• los conceptos que las instituciones no archivísticas necesitan para participar de forma efectiva en el proceso de preservación;
• un marco para describir y comparar diferentes estrategias y técnicas de preservación a largo plazo; y
• una base para entender los modelos de datos de información digital y cómo estos, y la información subyacente, pueden cambiar con el tiempo.
El modelo OAIS ofrece, pues, una visión amplia de los requisitos necesarios para conservar los documentos digitales a largo plazo. Este modelo garantiza que un documento sea auténtico, veraz e íntegro a lo largo del tiempo, y que el depósito en el que se aloja permita, a su vez, su accesibilidad, fiabilidad y utilización. Para lograrlo, se debe contar con metadatos.
Aunque el modelo OAIS fue creado para la industria aeroespacial, se ha experimentado con él en otros campos, como las matemáticas, la aeronáutica, la astronomía y la archivística, y se puede aplicar a la informática en nube. Actualmente, buena parte de los archivos que custodian documentos digitales se fundamentan en el estándar OAIS, aunque con adaptaciones según el contexto y las necesidades particulares de cada caso.
De acuerdo con el modelo OAIS, un archivo digital se compone de seis bloques de procesos básicos que caracterizan el ciclo de vida digital:
1. Captura (ingest). Los documentos se preparan para la incorporación al depósito. Se les aplican controles que permiten su ingreso en el sistema de preservación: control de procedencia, antivirus y formatos, y extracción de metadatos.
2. Almacenamiento (archival storage). Los ficheros se almacenan en un soporte físico. Se proporcionan los servicios necesarios para el almacenamiento, el mantenimiento y la recuperación para garantizar el acceso de la información a través del tiempo.
3. Gestión de datos (data management). Se gestionan los metadatos de los ficheros: los originales, los generadas en el proceso de captura y los que se irán incorporando a lo largo de su ciclo de vida.
4. Preservación (preservation planning). Se determinan las políticas y los responsables, los que monitorearán el entorno y vigilarán los cambios tecnológicos para revisar los formatos, el hardware y el software, y detectar cuando se vuelven obsoletos.
5. Acceso/difusión (access/dissemination). Se da soporte a los consumidores para posibilitar la recuperación y la consulta a la información preservada.
6. Administración (archive administration). Integra las funciones, los responsables y la tecnología que interviene en la operación global de preservación.
Estas funciones operan sobre lo que el mismo modelo OAIS denomina paquetes de información, un concepto que engloba el contenido del mismo objeto digital y sus correspondientes metadatos, elementos que pueden hallarse disgregados en el sistema o bien subsumidos en un único objeto digital (International Association of Sound and Audiovisual Archives, IASA, 2011).
En resumen, el modelo OAIS es un modelo capaz de enmarcar la organización estructural de un depósito de información. Al tratarse de un marco conceptual, sirve bien como modelo de referencia independiente de la comunidad de usuarios y de la tecnología. Pese a estas ventajas, su puesta en práctica ha producido cierta controversia científica.
Aunque este marco de referencia ha sido aceptado por buena parte de la comunidad implicada en la preservación digital, cabe señalar que no presenta una arquitectura de aplicación, sino un conjunto de requisitos que necesitan traducirse, interpretarse y concretarse para aplicarlos. Por lo tanto, no faltan voces que ponen en duda su capacidad de adaptarse a escenarios diversos, lo que ha llevado a algunos expertos a cuestionar su utilidad (Schumann y Recker, 2013; Cruz y Díez, 2016).
4. Metadatos
Los metadatos son un elemento omnipresente en los sistemas de información, donde se presentan en numerosas formas. La mayoría de paquetes de software de uso cotidiano apoya sus procesos en varios tipos de metadatos. La música que se escucha en Spotify, las fotos y los vídeos que se publican en medios sociales, los mensajes que se intercambian mediante el correo electrónico y muchas otras piezas de información van acompañadas de metadatos que transportan información sobre el creador, el contenido, ciertas propiedades técnicas y otros aspectos relevantes. Por el valor añadido que aportan a la información, los metadatos resultan esenciales para asegurar la funcionalidad de los sistemas y para facilitar la posibilidad de encontrar documentos relevantes e identificar su contenido (Riley, 2017).
Los metadatos son declaraciones estructuradas sobre los datos. Con mayor o menor grado de detalle, describen el contenido de un documento, proporcionan información administrativa, técnica y estructural, e informan acerca de los derechos sobre la propiedad intelectual. Toda esa información, cuando existe, facilita un triple propósito: identificar el contenido de los documentos digitales, facilitar su localización y mejorar la gestión de las colecciones digitales.
Aunque la noción actual de metadato fue conceptualizada hace aproximadamente medio siglo, en rigor de verdad los metadatos existen desde mucho antes de que se inventara la informática y el ordenador. En efecto, durante siglos, la profesión bibliotecaria ha producido metadatos al enumerar y catalogar colecciones de documentos. El concepto de metadatos se adapta fácilmente al modo en que funciona una biblioteca: si los «datos» los forman los fondos que aloja, los «metadatos» son los catálogos bibliográficos que emplea para describirlos. Y dado que la creación de metadatos ha sido siempre una tarea bibliotecaria fundamental, no sorprende que muchas innovaciones relacionadas con los metadatos tengan su origen en las bibliotecas (Gartner, 2016).
4.1. Tipos de metadatos
Los metadatos sirven a una enorme variedad de propósitos, si bien la mayoría de ellos se dividen en cuatro categorías principales: hay metadatos descriptivos, administrativos, estructurales y de uso (tabla 3).
Los denominados metadatos descriptivos son los que ayudan a descubrir y localizar la información a la que hacen referencia. Por esta razón se los conoce también como metadatos de búsqueda. Describen el contenido de un documento y abarcan el título, un resumen, palabras clave y cualquier referencia a personas, ubicaciones, entidades o productos mencionados o mostrados en él. Esta información se puede consignar usando texto libre o mediante términos o códigos de un vocabulario controlado.
Los metadatos administrativos, por su parte, ayudan a mantener en funcionamiento el sistema de información. En esta categoría entran aspectos como la fecha de creación y la ubicación geográfica, entre muchos otros. Una parte de esos metadatos la forman detalles técnicos que resultan necesarios para entregar la información digital de forma utilizable. Esa subcategoría es lo que se conoce como metadatos técnicos y abarca todo lo que un sistema necesita saber sobre un objeto digital para entregarlo y representarlo correctamente (Lubas, Jackson y Schneider, 2013). En una imagen digital, por ejemplo, estos metadatos pueden detallar su tamaño en píxeles, el tamaño de la paleta de colores potenciales que puede usar cada píxel y el algoritmo de compresión empleado para reducir su tamaño, entre otros muchos aspectos. Pero lo que necesita una imagen fija difiere de lo que se requiere en un vídeo, un texto o una grabación sonora, por lo que cada morfología de información suele implicar distintos tipos de metadatos técnicos. Estos metadatos tienden a generarse automáticamente y no suelen ser visibles de forma directa.
Otro tipo de metadatos administrativos son los metadatos de derechos, destinados a hacer valer los derechos de propiedad intelectual. En un documento, estos metadatos pueden detallar quién es el creador, quién posee los derechos de propiedad intelectual, bajo qué leyes o contratos se aplican tales derechos y qué derechos otorgan a los usuarios de la información. Algunos periódicos en línea (por ejemplo, los que cobran por leer más de diez artículos al mes) se basan en estos metadatos para hacer cumplir sus mecanismos de pago. También es un ejemplo de metadato de derechos una licencia Creative Commons que determina qué usos puede hacer el usuario de un contenido digital.
Una tercera clase de metadatos administrativos la constituyen los metadatos de preservación, que aportan la información necesaria para garantizar que el contenido del documento será accesible y utilizable en el futuro. Son metadatos complejos porque los procesos implicados en la preservación digital también lo son, dado que el software y el hardware que utilizamos hoy tienen una vida útil más corta que nuestro patrimonio digital. Garantizar el futuro acceso a ese patrimonio requiere grandes cantidades de metadatos que documenten cómo se puede acceder a la información sin depender de los creadores originales del formato.
Otro tipo de metadatos son los que construyen vínculos entre pequeños fragmentos de datos para ensamblarlos en un objeto más complejo. Son los denominados metadatos estructurales. Definen estructuras que unen componentes simples que forman un cuerpo mayor y más complejo de información con significado. En los libros físicos, la estructura la forma la paginación, unida al orden en que las hojas se pegan al lomo. En el ámbito digital, la estructura de un objeto, si tiene cierta complejidad, como en el caso de un libro digital, debe registrarse de forma más explícita (Gartner, 2016).
Por último, los metadatos de uso proporcionan información sobre cómo se ha usado un objeto. Una editorial, por ejemplo, puede rastrear cuántas descargas ha recibido un determinado libro, en qué fechas y qué perfil tienen las personas que lo descargaron (Pomerantz, 2015). Y lo mismo hacen plataformas multimedia y de entretenimiento con las reproducciones que genera cada ítem de su catálogo, lo que además alimenta su sistema de recomendaciones y fija la retribución que corresponde a los autores del contenido.
Tabla 3. Tipos de metadatos
|
Tipo de metadatos |
Función |
Ejemplo |
Usos |
|
Descriptivos |
|||
|
Ayudan a encontrar o comprender un fichero |
Título Autor Tema Género Fecha de publicación |
Descubrimiento Presentación Interoperabilidad |
|
|
Administrativos |
|||
|
Técnicos |
Sirven para descodificar y representar un fichero |
Formato del fichero Tamaño del fichero Fecha y hora de creación Método de compresión |
Interoperabilidad Gestión Preservación |
|
De preservación |
Contribuyen a la preservación a largo plazo |
Suma de comprobación Eventos de preservación |
Interoperabilidad Gestión Preservación |
|
De derechos |
Informan de los derechos de propiedad intelectual vinculados al contenido |
Copyright Términos de la licencia Titular de los derechos |
Interoperabilidad Gestión |
|
Estructurales |
|||
|
Relaciona entre sí las diversas partes de un recurso |
Secuencia Lugar en la jerarquía |
Navegación |
|
|
De uso |
|||
|
Indican el nivel y el tipo de uso de un recurso |
Número de accesos Seguimiento de usos y usuarios Información sobre versiones |
Gestión Evaluación |
|
Para facilitar su triple propósito de identificar, localizar y gestionar correctamente los objetos digitales, los metadatos han de ser abundantes. El valor de un objeto digital aumenta cuantos más metadatos se consignan, puesto que así permiten operaciones masivas de búsqueda, selección y organización. Las lagunas en los conjuntos de metadatos, en cambio, menoscaban esta capacidad.
Se debe observar una limitación técnica: los metadatos no se pueden bloquear. Es fácil modificarlos y también, por lo tanto, consignarlos con errores o incluso falsearlos, por lo que su fiabilidad no está garantizada. Aunque procuran informar de aspectos críticos como el copyright, no sirven para protegerlo.
4.2. Ubicación de los metadatos
Los metadatos se pueden almacenar en uno de dos lugares: dentro del objeto o fuera de él. Pueden estar incrustados en el fichero que describen o bien pueden estar ubicados aparte, de forma separada. La conveniencia de emplear una ubicación u otra depende de la situación de uso.
La mayor parte de los metadatos almacenados dentro del objeto se suelen generar en el mismo momento de su creación. Son un ejemplo conocido las declaraciones de metadatos incluidas en el código fuente de las páginas web. Los usuarios suelen ignorarlas cuando acceden a un sitio web, pero son accesibles de forma pública y se pueden consultar al examinar el código fuente (Zeng y Qin, 2016).
Los metadatos externos se suelen almacenar en un fichero sidecar (o fichero conectado), o bien en una base de datos, como ocurre en las bases de datos bibliográficas. La ventaja de los metadatos externos es que pueden personalizarse para usos específicos. El registro creado para una base de datos comercial de bibliografía académica, por ejemplo, puede ser distinto del que se crea para Google Académico o para un gestor de citas porque también es distinto el propósito al que está destinado cada recurso (Pomerantz, 2015).
Cuando los metadatos se almacenan de forma interna, es evidente que describen el objeto en el que se alojan. Pero si un registro de metadatos es externo al objeto que describe, ¿cómo se conectan ambas entidades entre sí para que se pueda localizar el registro de metadatos que corresponde a ese objeto en concreto?
En los ficheros sidecar, aquello que establece la relación entre el fichero de origen y el conectado es, en la mayoría de los casos, el nombre de fichero. Para vincular ambos ficheros suele bastar con almacenarlos con el mismo nombre; solo varía la extensión, que permite distinguir el contenido de cada fichero.
En los recursos en línea, la relación se señala por medio de más metadatos y, en particular, con la ayuda de un identificador uniforme de recursos (URI, uniform resource identifier), que identifica de forma unívoca un recurso de la red. Un identificador típico es un URL (uniform resource locator), una referencia web que actúa como una dirección única donde solo puede existir un recurso. Un URI actúa entonces en Internet igual que una dirección postal en el mundo físico: especifica de forma inequívoca un objeto único.
4.3. Esquemas de metadatos
Dado que existen numerosos estándares de metadatos, cada uno ideado para un escenario concreto de uso, se reseñan a continuación, a modo de muestra, aquellos desarrollos notables que gozan hoy de un uso generalizado o que vertebran la dimensión digital del patrimonio cultural (bibliotecas, archivos y museos).
Dublin Core
Establecido en 1995 por un grupo de bibliotecarios, especialistas en información y especialistas temáticos, el modelo de metadatos de Dublin Core es un conjunto de quince elementos de información con los que se puede describir una amplia variedad de recursos en Internet. Tales elementos son: contributor, coverage, creator, date, description, format, identifier, language, publisher, relations, rights, source, subject, title y type (Dublin Core Metadata Initiative, 2020). Los elementos son opcionales y repetibles, y admiten el uso de calificadores para aumentar la especificidad y la precisión de los metadatos. El elemento date, por ejemplo, se puede refinar con los calificadores created, valid, available, issued y modified para concretar qué expresa una fecha, o varias, asociada a un recurso.
Exif, IPTC y XMP
En el ámbito de la imagen, existen tres estándares de metadatos capaces de explicar cómo, dónde y cuándo se creó una fotografía, qué contiene, quién la tomó e incluso qué ajustes se le han aplicado en la fase de procesado.
Exif (exchangeable image file format) es un estándar creado para almacenar metadatos técnicos de las fotografías tomadas con cámaras digitales. Consignan información relativa a la cámara con la que se ha hecho la toma (marca y modelo), los parámetros del disparo (distancia focal, apertura de diafragma, sensibilidad, ajuste de blancos) y el modo de disparo (automático, manual, uso del flash, medición de luz), entre otros datos.
A estos metadatos se suelen sumar los definidos por el Consejo Internacional de Telecomunicaciones de Prensa (IPTC, por sus siglas en inglés), un consorcio de agencias de noticias de todo el mundo, uno de cuyos objetivos es desarrollar y mantener estándares técnicos. Para dotar las imágenes de la información necesaria en la creación, transmisión y publicación de noticias, este consorcio concibió un conjunto de metadatos descriptivos y administrativos que es hoy el estándar más utilizado para describir el contenido de las fotografías y señalar su autoría. Dada la naturaleza de la información que permiten registrar –título, descripción, palabras clave, ubicación y autoría–, los metadatos IPTC suelen añadirse a la imagen en el procesado.
Por último, XMP (extensible metadata platform) es una especificación abierta de metadatos genéricos destinada a representar metadatos en formatos de texto, imagen, audio y vídeo, tales como PDF, JPEG, WMA o QuickTime. Aunque estos metadatos se pueden almacenar de forma externa, en un fichero sidecar (homónimo, pero con la extensión .xmp), suelen hospedarse internamente por razones prácticas. Los metadatos se articulan en lenguaje XML y no son un conjunto cerrado, sino ampliable. Esta posibilidad facilita que los conjuntos de metadatos Exif e IPTC se puedan encapsular en un superconjunto XMP.
Schema.org
Lanzado por Google, Microsoft, Yahoo y Yandex en 2011, Schema.org es un vocabulario que permite marcar la semántica de las páginas web a fin de mejorar la capacidad de los buscadores de relacionar contenido y presentarlo de forma más rica (Guha, Brickley y Macbeth, 2016).
Define centenares de tipos de información, de los cuales los más utilizados representan datos relativos a obras de creación (CreativeWork), eventos (Event), lugares (Place), organizaciones (Organization), personas (Person), productos (Product), recetas (Recipe) y reseñas (Review). Cada una de estas categorías principales incluye subcategorías detalladas, por lo que es posible describir tipos específicos de obras de creación (por ejemplo, un artículo académico, por medio del tipo ScholarlyArticle) o de lugares (por ejemplo, un negocio local, con LocalBusiness, o un ayuntamiento, mediante CityHall), entre otras posibilidades. Los datos se pueden marcar de tres formas: mediante RDFa, microdatos o JSON-LD, siendo esta última la opción recomendada por Google porque simplifica el desarrollo.
El web del proyecto Schema.org manifestaba a finales de 2021 que este vocabulario se emplea en más de diez millones de sitios, pero es un dato desfasado. Ya en 2016 mencionaba este mismo número, que ha crecido enormemente (Sentance, 2017; Van Berkel, 2021), dados los beneficios que el marcado semántico aporta al posicionamiento en buscadores: los datos estructurados generan resultados enriquecidos, apoyan la búsqueda semántica y favorecen la entrada a la base de conocimiento de Google conocida como Knowledge Graph (Pecánek, 2020).
MPEG-7
Mientras que MPEG-1, MPEG-2 y MPEG-4, los primeros estándares desarrollados por el comité de expertos MPEG (Moving Picture Experts Group), abordan la compresión y transmisión de contenido audiovisual, MPEG-7 es el primer estándar que se centra en los metadatos, en la descripción del contenido. Surgió de la necesidad de facilitar la creación, el intercambio, la recuperación y la reutilización de contenido multimedia ante el nuevo rol, más activo, de los consumidores de contenido (Agius, 2008).
MPEG-7 define un conjunto de metadatos destinados a describir contenido sonoro, gráfico y audiovisual, y se articula en XML, si bien existe también una representación binaria (BiM) que favorece una transmisión más eficiente. En conjunto, es un estándar complejo, formado por diecisiete partes con distinto grado de adopción.
MARC
El lenguaje de metadatos más utilizado en la comunidad de bibliotecas es anterior a los formatos modernos de metadatos. La catalogación legible por máquina (MARC, por sus siglas en inglés) surgió en 1968 de un proyecto piloto en la Library of Congress para experimentar con la distribución informatizada de tarjetas de catálogo. Desde entonces se ha consolidado como el formato de metadatos subyacente a los catálogos de bibliotecas en línea (Riley, 2017). La base de datos WorldCat, de la cooperativa OCLC, utilizada para encontrar documentos en numerosas instituciones y compartir registros entre bibliotecas, contenía en julio de 2021 más de 500 millones de registros bibliográficos MARC.
Más que un formato, MARC constituye una familia de formatos con diversas implementaciones en varios países y entornos. En España, durante la década del 2000, por recomendación de la Comisión Técnica de la Biblioteca Nacional de España y de las bibliotecas nacionales y regionales de las comunidades autónomas, los sistemas bibliotecarios de titularidad pública adoptaron MARC 21 como formato de descripción en sus sistemas integrados de gestión bibliotecaria. Asimismo, existe un esquema MARCXML, desarrollado por la Library of Congress (2020), orientado al tratamiento de datos MARC en un entorno XML.
BIBFRAME
La Bibliographic Framework Initiative (BIBFRAME) es un nuevo modelo de datos de descripción bibliográfica, destinado a sustituir los estándares MARC. Está articulado mediante el modelo de datos RDF y estructurado según los principios de los datos enlazados (linked data) para que los metadatos bibliotecarios funcionen con más eficacia en los entornos de información actuales. De esta iniciativa, liderada también por la Library of Congress, se han lanzado ya dos versiones, BIBFRAME 1.0 y 2.0, en 2013 y 2016, respectivamente. Pero ambas presentan problemas de diseño, aún en discusión, por lo que no se trata todavía de un modelo estable (Riley, 2017).
El modelo BIBFRAME 2.0 organiza la información catalográfica en tres niveles básicos de abstracción: obra (la esencia conceptual de un recurso), instancia (una realización material e individual de una obra) e ítem (un ejemplar físico o digital de un ejemplar). Y define, en relación con la obra, tres conceptos clave adicionales: agente (persona u organización asociada a una obra), tema (conceptos sobre los que trata una obra) y evento (suceso registrado en una obra). La gran promesa de este modelo es que facilitará la interoperabilidad y la recuperación basada en relaciones semánticas y, por lo tanto, mejorará la integración de los catálogos bibliográficos en el entorno del web.
METS
El esquema METS (Metadata Encoding and Transmission Standard) es un estándar de metadatos destinado a codificar en lenguaje XML metadatos que faciliten la gestión de objetos digitales y su intercambio entre repositorios. Concebido por la Digital Library Federation, este estándar se mantiene como parte de los estándares MARC de la Library of Congress (2017b).
La arquitectura del esquema permite expresar la estructura jerárquica de un objeto en una colección digital, registrar los nombres y las localizaciones de los ficheros que componen tales objetos, y registrar los metadatos asociados a esos objetos. Para satisfacer ese triple propósito, un documento METS se articula en siete secciones: una cabecera declarativa, metadatos descriptivos, metadatos administrativos, una relación de los ficheros que integran el objeto digital, un mapa estructural, vínculos estructurales, y una sección que define comportamientos ejecutables y los asocia a servicios distribuidos.
4.4. Metadatos en los medios sociales
En su Embedded Metadata Manifesto, el Consejo Internacional de Prensa de Telecomunicaciones (IPTC, 2011) define cinco líneas directrices como apoyo a la creación y al almacenamiento de metadatos a fin de que los ficheros transporten datos importantes sobre su contenido siempre que esto sea posible. Según reza el escrito, «los metadatos son esenciales para describir, identificar y rastrear los medios digitales y deben aplicarse a todos los elementos de los medios que se intercambian como ficheros o como flujos de datos».
Es bien sabido, sin embargo, que los metadatos a menudo se ignoran o se eliminan a medida que los ficheros atraviesan las diversas fases de un trabajo. Con el propósito de crear conciencia sobre el valor que se desperdicia con semejante pérdida, el grupo de trabajo de metadatos fotográficos del IPTC analiza regularmente una docena de sitios para comprobar en qué medida conservan y visibilizan los metadatos. El resultado suele ser desigual y revela un respaldo escaso de los metadatos.
El último estudio (IPTC, 2019) muestra dos realidades. Por una parte, las plataformas que preservan los metadatos del contenido publicado o compartido (Behance, Google Fotos, Dropbox, Google Drive, Microsoft OneDrive) no siempre se esmeran por visualizarlos en su interfaz y, cuando lo hacen, muestran solo un conjunto incompleto. Por otra parte, los medios sociales suelen generar, de cada imagen que se publica en ellos, una versión más comprimida y de peor calidad de la que, además, tienden a eliminarse los metadatos. Facebook, Instagram y Twitter, tres de los medios sociales más populares, los destruyen por completo.
Algunas voces alegan que así se evita compartir información privada de manera accidental; ciertamente, es mucho lo que las imágenes personales, si se hacen públicas en Internet, pueden revelar por medio de los metadatos. Desde un punto de vista pragmático, se podría argumentar, además, que la supresión de los metadatos contribuye a rebajar el peso de los ficheros, lo que facilita una transmisión más eficiente por la red. No obstante, también hay opiniones recelosas que ven en la eliminación de metadatos un intento de borrar cualquier vestigio de la propiedad y de los derechos sobre el contenido.
5. Cadena de bloques
En los últimos años, ha cobrado protagonismo una tecnología conocida como cadena de bloques o blockchain. Este concepto se presentó, junto con el del bitcoin, que es hoy la criptodivisa más conocida, en un documento técnico firmado bajo el pseudónimo de Satoshi Nakamoto (2008). La primera cadena de bloques, Bitcoin,6 se lanzó en 2009 como un proyecto de código abierto.
Aunque no se conoce la identidad de Nakamoto, lo cierto es que esta persona ideó un concepto innovador: un sistema de pago de igual a igual (peer-to-peer) que permite a los usuarios transferir de forma directa bienes digitales (denominados tokens), sin más intermediarios que la propia red, cuya función es verificar las transacciones y garantizar que nadie hace trampas.
Una cadena de bloques es entonces una estructura de datos que permite crear un libro de contabilidad digital compartido entre una red de partes independientes. Los registros que se anotan son inalterables, y están entrelazados y cifrados para así garantizar la seguridad y la privacidad de las transacciones (Drescher, 2017).
Aunque esta tecnología es relativamente nueva, combina ciertas técnicas que la humanidad viene utilizando desde hace mucho tiempo. Las criptomonedas, por ejemplo, son la fusión de dos conceptos antiguos: la criptografía y el dinero. Asimismo, la noción del token reproduce la vieja práctica de pagar con vales de compra. El sistema incorpora además el concepto de hash o huella digital, una función que certifica la autenticidad de la información mediante un valor resumen, igual que haría una firma digital. Y en última instancia, la estructura de datos sustenta libros de contabilidad similares a los que la sociedad ha usado durante siglos para llevar cuentas financieras. Estos modelos preexistentes se integran en una base de datos distribuida, y esa nueva estructura –la cadena de bloques– constituye hoy una tecnología innovadora (Laurence, 2019).
5.1. Estructura y funcionamiento
Una cadena de bloques es un registro de transacciones articulado en una red de igual a igual, sin una autoridad central que gestione el flujo de datos y vele por el cumplimiento de las reglas. Los ordenadores que componen la red, denominados nodos completos, se encuentran dispersos en diversas ubicaciones, alojan un registro completo de todas las operaciones anotadas y se ocupan de mantener la integridad de los datos. El registro de transacciones no se almacena entonces en un único ordenador, sino en muchos terminales interconectados que mantienen copias individuales de la estructura de datos. Y para que cada participante pueda administrar el libro de cuentas de forma segura se utilizan técnicas de cifrado.
Esta descentralización de la base de datos es un aspecto clave para evitar que la red se corrompa, pero no es el único. También se emplea una criptomoneda, una moneda digital producida y administrada por cada cadena de bloques como incentivo para mantener la integridad del sistema (Drescher, 2017). Cada criptodivisa funciona de manera distinta en su respectiva red, pero es siempre el software con el que se paga por el funcionamiento del hardware. Así como el hardware lo forman los nodos que custodian los datos de la red, el software es el protocolo de la cadena de bloques (Laurence, 2019). Algunos de los protocolos más conocidos son Bitcoin, EOS, Ethereum, Ripple y Stellar.
Proceso de una transacción
Una transacción es cualquier operación que agrega información a la cadena de bloques. En términos generales, es un registro de datos verificado por todos los miembros integrantes de la red distribuida, que proporciona una prueba prácticamente inquebrantable de operaciones comerciales, tales como acuerdos contractuales o financieros.
Las transacciones se llevan a cabo desde monederos electrónicos o wallets, ficheros cifrados que funcionan de manera similar a una cuenta bancaria. Disponen de una clave pública y otra privada. La clave pública es una cadena alfanumérica que equivale a un número de cuenta y que el destinatario de la transacción debe facilitar al emisor. La privada, en cambio, se emplea para autorizar operaciones desde el monedero de cada usuario.
Cada transacción se envía a la red a través de un nodo, se transmite después al resto de nodos para su verificación y, una vez aprobada, se combina con otras transacciones para conformar un bloque. Cuando ese bloque se anexa a la cadena como un nuevo eslabón, la cadena se replica en todos los nodos de forma permanente e inalterable, y la transacción se considera finalmente completada.
Minería y consenso
Cada bloque se genera mediante un proceso de minería que lo entrelaza con otros bloques mediante valores hash que forman una especie de «cadena matemática». Los mineros, en este contexto, son ordenadores de gran potencia que dedican un enorme esfuerzo informático a verificar las transacciones para luego registrarlas en el libro mayor, a cambio de una recompensa en la criptomoneda en la que opera el sistema. ¿De dónde sale ese dinero? Cuando un usuario utiliza la cadena de bloques, debe pagar una comisión a la red y, según la cantidad abonada, los procesos de verificación se ejecutarán de forma más o menos rápida.
Dado que la estructura de datos permite anexar nuevas entradas, conviene asegurarse de que solo se agreguen transacciones válidas y autorizadas. Cada nuevo registro requiere, pues, una validación. El cumplimiento de las reglas se basa en un algoritmo de consenso (figura 4).
Figura 4. En una cadena de bloques la confianza la establece el algoritmo de consenso
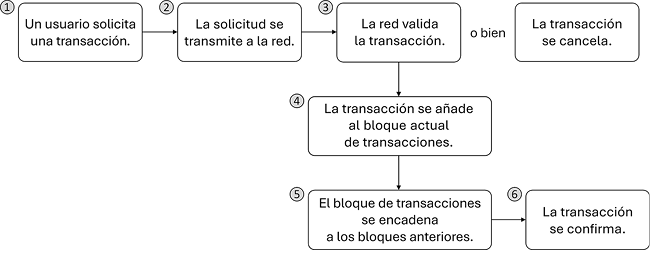
Fuente: Jorge Franganillo
Las entradas confirmadas se registran en la cadena de bloques y se transmiten a todos los nodos de la red, lo que permite que cada nodo disponga siempre de la información actualizada, igual que cuando varias personas trabajan de forma simultánea en un documento compartido en la nube.
Cada cadena de bloques usa su propio algoritmo para validar las entradas que se agregan a su red. Bitcoin, por ejemplo, opera bajo el supuesto de que un atacante malintencionado podría corromper el historial de operaciones para robar tokens. Para evitarlo, usa un modelo robusto de consenso denominado prueba de trabajo o sistema PoW (del inglés proof-of-work), que obliga al minero a resolver un complejo problema matemático. Cuando el minero considera resuelto el problema, publica la solución para que el resto de la comunidad la verifique y la dé por correcta. Habrá consenso si al menos el 51 % de los demás mineros validan la veracidad del bloque. Y así es como este protocolo controla, limita y valida la creación de unidades monetarias, verifica la validez de las transacciones y evita el doble gasto de fondos (Antonopoulos, 2017; Dhillon, Metcalf y Hopper, 2021).
Otras cadenas de bloques generan confianza basándose en una prueba de participación o sistema PoS (del inglés proof-of-stake). Este protocolo exige a los propietarios de los nodos completos que depositen ciertos fondos que perderán si se les sorprende defraudando la red (Drescher, 2017; Laurence, 2019). Si un participante tiene interés en el buen funcionamiento de la red que otorga valor a una determinada criptomoneda, estará dispuesto a congelar buena parte de sus fondos, por lo que será razonable que se responsabilice de proteger al sistema de posibles ataques.
Estructura de un bloque
Un bloque válido, una vez ha pasado por el consenso de la red, lo suelen integrar varios elementos:
• Huella (hash): una cadena alfanumérica construida mediante una función criptográfica que identifica el bloque y su contenido, y que permite detectar cualquier intento de modificación.
• Información: conjunto de datos sobre la transacción, cuya naturaleza depende del tipo de aplicación que se haya construido sobre ella.
• Sello de tiempo: marca cronológica que determina el momento exacto en el que el bloque ha sido validado por la red.
• Huella del bloque anterior: huella que referencia el bloque precedente y crea un vínculo inmutable entre los bloques secuenciales de la cadena.
Estos elementos se disponen de forma que puedan verificarse públicamente, y así es como se impide la alteración o falsificación de los datos de las transacciones.
5.2. Aplicaciones
Según se ha visto, la cadena de bloques se caracteriza por la descentralización, la autenticación mediante huellas digitales, la inmutabilidad y el consenso. Estos rasgos aportan seguridad al intercambio de datos o activos digitales y permiten afrontar un problema antiguo con una solución nueva.
La mayoría de las aplicaciones actuales de la cadena de bloques giran en torno a transacciones rápidas de dinero u otras formas de valor. Sin embargo, las posibilidades de esta tecnología han estimulado la imaginación de empresarios, gobiernos y formaciones políticas de todo el mundo, y ya hay proyectos interesados en explotar, de esta y de otras maneras igualmente novedosas, las virtudes de esta tecnología.
Entre las iniciativas más prometedoras que se están explorando con respaldo oficial, gubernamental, hay sistemas de registro de propiedades, aplicaciones de validación de la identidad digital y sistemas de seguridad para viajes internacionales. Países como el Reino Unido, Japón, Singapur y los Emiratos Árabes Unidos lo ven como una forma de reducir costes, crear nuevos instrumentos financieros y mantener registros limpios (Laurence, 2019).
La noción de reserva de valor que han aportado las criptodivisas se ha trasladado también a objetos orientados al coleccionismo, lo que ha dado un giro al valor que se concede a las obras de arte digitales. Mediante los denominados vales no fungibles, también conocidos como NTF (non-fungible tokens), el valor que antes se condecía a bienes tangibles, como el oro, los sellos o las obras de arte físicas, se extiende ahora a bienes intangibles. Basados en protocolos de cadenas de bloques y en criptodivisas, los NFT son la versión digital de los activos tangibles a los que se les confiere un valor. Tal es su auge que ya son numerosas las obras de arte digitales que se subastan o se venden por grandes sumas de dinero (figura 5).
Figura 5. La plataforma OpenSea subasta obras digitales en formato NFT a cambio de ether, la criptomoneda de Ethereum
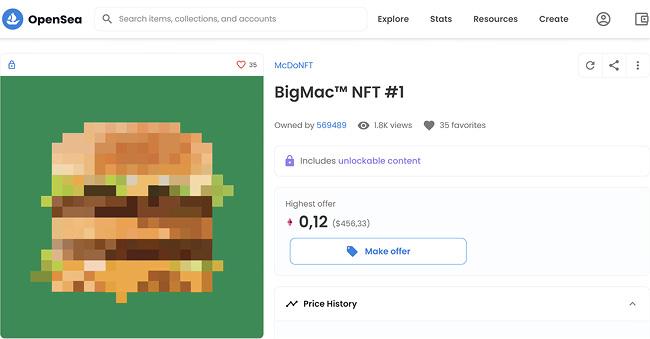
Fuente: captura de pantalla de opensea.io
Aunque estos activos digitales puedan compartirse en Internet, lo característico de los NFT es que certifican quién es el propietario único de la obra original. He aquí, pues, la razón por la que están ganando terreno: extienden la noción de valor que hasta hace poco se atribuía a los metales preciosos, a la filatelia y al coleccionismo de arte tangible. Ese valor, no obstante, es puramente cultural; para que algo resulte valioso, basta que suficientes personas crean que lo es. Paralelamente, y pese a lo que afirman algunas voces, los NFT no son indestructibles: su valor y su existencia dependen de la fiabilidad y la futura permanencia de la red que hoy garantiza su autenticidad.
5. El término abierto, en OAIS, implica que la norma ISO 14721:2012 y las posteriores normas relacionadas se desarrollan en foros abiertos. No implica que el acceso al archivo sea necesariamente abierto. Un archivo regido por el modelo OAIS puede ser de acceso restringido.
6. Escrita con mayúscula (Bitcoin), esta denominación se refiere al protocolo de red que se comenta aquí. En cambio, bitcoin, con minúscula, es propiamente la criptodivisa.