1
Turing encuentra a Darwin
Si alguna vez nos encontramos con criaturas de un planeta similar a la Tierra, tal vez no podremos predecir a priori si tendrán alas, tentáculos, piel verde, cabezas o colas bifurcadas. Pero podemos predecir que, cualquiera que sea su aspecto, es muy probable que se basen en proteínas en agua, bajo la supervisión de ácidos nucleicos.
Isaac Asimov
El azar no excluye lo inevitable.
Christian de Duve
La máquina universal
Es un día cualquiera de 1945 en Bletchley Park, un pueblo de Inglaterra a una hora de tren de Londres. De una mansión de ladrillo rojo vemos salir por la puerta a un hombre joven que se detiene a saludar a algunos compañeros que hablan en la entrada del edificio. Después, baja las escaleras y se aleja, dejando atrás el lugar en el que había compartido uno de los desafíos intelectuales más difíciles de la segunda guerra mundial: romper los códigos secretos mediante los que los nazis ocultaban sus operaciones en el campo de batalla y que habían logrado crear gracias a la máquina que la inteligencia alemana había bautizado como Enigma (figura 1.1). Como ocurre con muchos otros ejemplos de códigos cifrados, Enigma fue diseñada para esconder la naturaleza de los mensajes que debían ser enviados de forma segura, pero en este caso sus diseñadores habían conseguido un nivel de complejidad extraordinario, dado que mediante un mecanismo muy sofisticado lograban que el número de posibles formas de codificar los mensajes (y por tanto la clave secreta para descifrarlos) fuera casi astronómico. Era imposible probar todas las combinaciones, así que el frente de ataque debía ser distinto. El hombre que se aleja de la mansión lo consiguió empleando para ello otra máquina, construida en Bletchley Park. Nuestro protagonista diseñó, junto con un grupo excepcional de colaboradores, un sistema de análisis sistemático de los mensajes que obtenía el servicio de espionaje. Su aproximación tuvo éxito y muchos historiadores consideran que el triunfo de los expertos de Bletchley Park acortó la duración del conflicto entre dos y cuatro años. Este matemático genial es Alan Turing, quien en 1935 había publicado con tan sólo veintitrés años de edad un artículo fundamental que establecía las bases de la teoría de la computación. Es un trabajo enormemente abstracto, pero desde su adolescencia Turing sentía inclinación por las capacidades de los sistemas mecánicos para llevar a cabo cálculos y operaciones lógicas, y durante su estancia en aquel centro de espionaje contribuyó al desarrollo de los primeros dispositivos electrónicos capaces de ser programados.
Terminada la guerra, Winston Churchill ordenó que las máquinas y toda la documentación existente relacionada con este episodio fueran destruidas. Sobre lo que había tenido lugar en aquel edificio cayó el secreto, un secreto que nadie podía revelar sin ser acusado de alta traición. Así fue hasta 1974, cuando se hizo público el papel desempeñado por el contraespionaje británico. Desgraciadamente, los homenajes y reconocimientos llegaban tarde para Turing, que pocos años después de su trabajo en Bletchley fue juzgado por «conducta indecente» (era homosexual, un crimen en la Inglaterra de entonces), lo que le llevó al final a suicidarse en 1954, tan sólo unos días antes de cumplir cuarenta y dos años. Muchos científicos e historiadores de la ciencia coinciden en que la pérdida de Turing tuvo seguramente un enorme impacto en el desarrollo de la ciencia del siglo XX. Particularmente porque Turing había llevado a cabo pasos decididos y muy innovadores hacia el desarrollo de una teoría matemática de la biología y en especial del papel de la computación y la información en sistemas vivos. No hay que olvidar que en los últimos años de su vida, Turing formuló la primera teoría acerca de cómo se organizan los embriones, la posibilidad de crear un ordenador inspirado en el cerebro y también planteó un test capaz de determinar si una máquina puede ser considerada inteligente.

Figura 1.1. La máquina de cifrado Enigma empleada por los nazis durante la segunda guerra mundial y que Alan Turing contribuyó decisivamente a descifrar, lo que fue clave para la victoria aliada (imagen de 1943, de los archivos federales alemanes).
El trabajo que lo hizo famoso antes de su implicación en el descifrado de Enigma se publicó en 1936 y se titulaba «Los números computables, con una aplicación al Entscheidungsproblem». El artículo estableció los fundamentos matemáticos de la computación, introduciendo para ello un concepto abstracto pero enormemente poderoso: una máquina capaz de llevar a cabo cualquier computación y que hoy conocemos como «máquina de Turing». La máquina (véase la figura 1.2, arriba) incluye en su definición dos componentes esenciales: (a) una cinta muy larga en la que se pueden leer símbolos escritos, así como espacios en blanco y (b) un dispositivo lector que puede identificar estos símbolos, modificarlos y cambiar su estado interno en función de lo que ha leído. Esta descripción parece muy alejada de lo que denominaríamos «ordenador» tal y como lo conocemos en la actualidad. El ordenador con el que escribo estas líneas es una máquina compleja, sin cintas ni cabezales lectores. Aun así, puede demostrarse que la máquina de Turing es una buena representación de las operaciones que puede llevar a cabo cualquier ordenador y puede de hecho simular las operaciones de cualquier ordenador imaginable. Dicho de otra forma: detrás de toda máquina que computa tenemos una máquina de Turing que la describe a la perfección. Aunque nunca diseñaríamos un ordenador siguiendo el esquema original, el modelo nos sirve para pensar acerca de la computación, sus límites y hacerlo de manera completamente general, llevando así a cabo una abstracción completa que nos permite aplicar la idea fuera del mundo de las máquinas. Esta idea de una máquina universal capaz de mecanizar cualquier tipo de computación tiene un curioso antecedente en la obra del mallorquín Ramon Llull (1232-1315), quien, en plena Edad Media, exploró un problema no menos ambicioso: crear una máquina lógica capaz de probar la verdad o falsedad de cualquier postulado. Empleando conjuntos de símbolos y palabras, Llull confiaba en poder introducir preguntas en su máquina, compuesta por una serie de discos (véase la figura 1.2, abajo) que podían girar y dar lugar a múltiples combinaciones, que a su vez servirían de base para encontrar respuestas lógicas. Este sueño de un cálculo automatizado define en cierto modo las raíces del intento de mecanizar el pensamiento. De lo que sí podemos estar seguros, gracias a las contribuciones de Turing y del también matemático Kurt Gödel, es de que lo que Llull pretendía —más allá de cómo hacerlo mecánicamente— es imposible.
El trabajo de Turing es contemporáneo de la época de los primeros ordenadores programables y un poco anterior al surgimiento de uno de los campos más importantes de la biología: la genética molecular, que condujo al descifrado del código genético a mediados del siglo XX. El desarrollo de los primeros ordenadores y de la tecnología que cambiaría totalmente nuestra sociedad y la forma de comunicarnos fue paralelo, con muchas intersecciones, al de la biología molecular, que transformaría a su vez nuestra visión de lo vivo y de nuestro papel en la biosfera. Nos hemos detenido a hablar de Turing precisamente porque la idea de su máquina plantea un esquema completamente universal para definir el concepto mismo de computación. Un ordenador, el cerebro, una célula y quién sabe qué otras estructuras vivas procesan información. Si tuviéramos que decir de qué manera lo hacen, observando cada ejemplo por separado, no podríamos encontrar una ley general. La idea de Turing nos lo permite, y su máquina universal nos servirá para preguntarnos sobre la naturaleza del código de la vida y sobre algunas cuestiones muy relevantes: ¿es este código único o se trata de un accidente congelado?, ¿es un código óptimo en algún sentido?, ¿cabe esperar que la vida en otra parte del cosmos emplee un código similar?, ¿podemos crear nuevos códigos biológicos?
El triunfo de la información
La vida en nuestro planeta, y tal vez en otros, es posible porque nuestro universo (al menos lo que podemos ver de él) está dominado por unas leyes físicas que rigen el comportamiento de unos pocos elementos que hacen arder el interior de las estrellas, y que se transforman a lo largo de miles de millones de años en otros elementos más pesados, entre éstos todos aquellos que sirven de bloques básicos para construir los organismos vivos. El carbono, el oxígeno, el fósforo o el nitrógeno son el resultado de violentos procesos de creación y destrucción, que llevan en último término a la muerte de las estrellas. A medida que el combustible de una estrella se va consumiendo mediante reacciones nucleares, se acumulan átomos de mayor complejidad que son entonces utilizados a su vez como combustible de otras reacciones. Pero tarde o temprano el equilibrio entre la gravedad (que tiende a colapsar la estrella sobre sí misma) y las reacciones nucleares (que la hacen expandirse) se rompe, y se produce una explosión que crea a su vez nuevos elementos de mayor complejidad. Como veremos más adelante, este ciclo de nacimiento y muerte de las estrellas es imprescindible para que surja la vida.

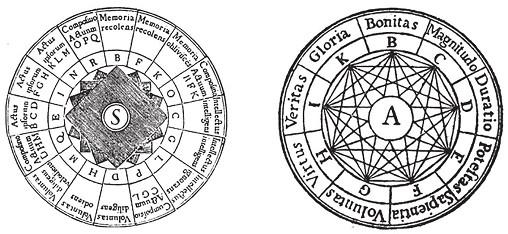
Figura 1.2. Máquinas que computan. La propuesta original de Turing (arriba, reconstruida por Mike Davey, https://simple.wikipedia.org/wiki/Turing_machine) es una máquina que lee y escribe sobre una cinta (idealmente infinita). A medida que lleva a cabo este proceso de lectura y escritura, su estado interno también cambia. En la imagen de abajo vemos dos ejemplos de los diagramas que Ramon Llull empleaba para ilustrar su idea de determinar de forma lógica la falsedad o veracidad de un postulado.
Si analizamos la abundancia de elementos químicos de un cuerpo humano, comprobamos que posee una composición universal que todos compartimos, junto con una buena cantidad de agua. Pero parece evidente que un recipiente que contuviera las cantidades adecuadas de cada ingrediente tiene muy poco que ver con ninguno de nosotros. De algún modo, la vida no es una simple combinación de elementos químicos. Algunos científicos han señalado, acertadamente, que la vida es en realidad un estado de la materia. Y un estado enormemente especial. Por una parte, requiere una constante actividad: una célula necesita para sobrevivir disponer de recursos externos que pueda captar y emplear como material básico de construcción y reparación, de forma que su membrana, su núcleo o el armazón que le da forma se puedan mantener a lo largo del tiempo. Todo ello precisa (como en una máquina que lleva a cabo una tarea) aporte de energía y de materia. Ambas serán transformadas en otros tipos de energía y materia gracias al metabolismo, que actúa como sistema de generación de energía, así como de sistema transformador de moléculas de un tipo en moléculas de otro tipo, que pueden ser de gran tamaño. En todas las escalas posibles, el flujo de energía y materia permite crear estructuras complejas, en contra de lo que esperaríamos en sistemas físicos que tienden de manera espontánea a la homogeneidad y el desorden.
El estudio de cómo fluyen y se transforman la materia y la energía ha dominado buena parte de la física y la química, mucho antes de que estas disciplinas estuvieran siquiera definidas. Desde un principio, quedó claro que ciertos procesos tienen lugar de forma espontánea y que el estado final era siempre el mismo. Por ejemplo, si dejamos caer unas gotas de tinta dentro de un vaso de agua, sabemos que la tinta se expandirá con el paso del tiempo hasta quedar uniformemente distribuida por todo el volumen. Decimos entonces que hemos alcanzado un estado de equilibrio. En cambio, en una célula encontraremos muchos ejemplos de procesos que evitan alcanzar un estado semejante. El caso más claro nos lo da la presencia de gradientes: las membranas biológicas permiten que la concentración de ciertas moléculas o sales sea distinta de la que hay en el medio exterior. La capacidad de crear diferencias permite definir un ambiente interno que separa al individuo del mundo en el que vive. Es por lo tanto parte esencial de su identidad. Además, una vez que se han creado diferencias, es posible emplearlas para llevar a cabo procesos activos de intercambio, que pueden ser un simple flujo de moléculas o la base para propagar un impulso nervioso. A un nivel mucho mayor, nuestro cuerpo se mantiene y renueva constantemente gracias a que ingerimos alimentos y agua de nuestro entorno que transformamos en moléculas que mantienen nuestros tejidos y órganos en funcionamiento. Esta renovación es tan profunda que la gran mayoría de los átomos que forman nuestro cuerpo en este momento ya no son los mismos que poseíamos hace apenas unos años. Literalmente podemos afirmar que vivir tiene mucho que ver con la vieja expresión de «renovarse o morir».
Para que todo funcione correctamente, parece razonable que exista una combinación de un sistema de separación entre lo propio y lo ajeno (el interior del organismo y el medio externo) junto con mecanismos activos de flujo de energía. En nuestro mundo, este par de propiedades corresponderían a una membrana cerrada y un sistema que mantenga reacciones, aunque simples, que podemos denominar «metabolismo». El primer componente es fácilmente obtenible: muchos lípidos forman esferas perfectas cuando se encuentran en un medio acuoso. Es muy posible que las formas de vida que puedan existir en otros planetas deban seguir esta restricción estructural y funcional, en buena medida impuesta por la física de los sistemas alejados del equilibrio. En este sentido, sospecho que nadie encontrará nada interesante —desde el punto de vista de la vida— en nubes de gas en el espacio que posean propiedades de organización. Aquí la ciencia ficción ha adelantado algunas posibilidades tan sugerentes como seguramente equivocadas. El astrofísico británico Fred Hoyle, por ejemplo, propuso en su novela La nube negra (1957) la idea de una nube de gas interestelar que se acerca a la Tierra y pone en peligro su supervivencia porque puede bloquear la luz del Sol. Pero cuando nos alcanza, la nube demuestra poseer una inteligencia muy superior a la de la humanidad, una especie de supermente de enormes capacidades. Si bien podemos imaginar una nube de gas como las que ya han sido estudiadas por los radioastrónomos, y admitir que pueden poseer una gran riqueza en su composición molecular, la existencia de una organización estable que pueda identificarse con un organismo vivo, y aún más con un sistema capaz de comunicarse, parece difícil de sostener. Volveremos a este problema algo más adelante, pero baste señalar aquí que la posesión de una estructura bien delimitada, que nos defina como objetos vivos confinados en un espacio finito, es importante por muchos motivos. Muy especialmente porque estamos sujetos a la evolución y porque la materia viva puede persistir sólo a través de la evolución.
Cuando nos detenemos a estudiar los sistemas vivos, debemos reconocer dos elementos centrales (y relacionados entre sí) que escapan al discurso habitual de las teorías físicas basadas en la comprensión de la materia y la energía: su capacidad para reproducirse y el papel central que desempeña la información. El primer elemento es un atributo clave de la vida, y aunque la materia y la energía son condiciones necesarias, no son suficientes para comprender el origen del fenómeno de la replicación. Las amebas se reproducen dividiéndose; las plantas, a través de semillas o fragmentos de individuos, y nosotros a través de un proceso complejo que requiere, entre otras cosas, buscar una pareja, compartir el material genético, desarrollar durante nueve meses un nuevo individuo compuesto de miles de millones de células a partir de una sola célula inicial y unas cuantas cosas extraordinarias adicionales. La vida parece intrínsecamente ligada al hecho de que, tarde o temprano, los organismos vivos acaban dando lugar a más organismos.
El segundo aspecto es más sutil pero no menos importante: más que cualquier otra cosa, la vida maneja, almacena y procesa información. Esta información la adquieren las amebas, las hormigas o los cerebros complejos, y el resultado de esta adquisición siempre da lugar a algún tipo de respuesta o de lo que ahora llamaríamos una computación. Como señaló el físico John Hopfield, si algo distingue a un sistema biológico de un sistema físico es precisamente esta capacidad de computar. Una piedra es un objeto en equilibrio, incapaz de responder de manera activa a los cambios del ambiente, mientras que una bacteria posee receptores que le permiten detectar la temperatura o la humedad externas y responder a éstas en formas diversas. Un ambiente seco puede provocar una respuesta que detiene la actividad celular y hacer que las células se conviertan en esporas. El programa genético desempeña el papel del software que le permite a la célula actuar como un pequeño pero potente ordenador. Un medio rico en recursos puede hacer que el microorganismo active sistemas metabólicos especiales o mecanismos de movimiento que le permitan acercarse a la fuente de recursos.
Esta capacidad de procesar información es el resultado de las interacciones entre una molécula de excepcional importancia, el ADN (el ácido desoxirribonucleico), y una multitud de nanomáquinas —las proteínas— que son codificadas por éste. El descubrimiento de la estructura e importancia del ADN es uno de los mayores logros de la biología del siglo XX. Pero mucho antes de que Francis Crick y James Watson, basándose en los resultados experimentales de Rosalind Franklin, propusieran la estructura en doble hélice del ADN, hubo intensos debates acerca de cuál podría ser el sustrato físico de la herencia. Se sabía que de algún modo los caracteres que definían las propiedades de un individuo debían estar determinados o verse influidos por alguna característica de las moléculas almacenadas en el interior de las células, pero los candidatos no estaban claros. Algunos pensaban que la «información genética» debía hallarse en las proteínas y otros sospechaban del material que se encontraba en el núcleo celular.
Aunque el concepto de «gen» estaba en el aire, dado que era evidente que se podían transmitir de generación en generación caracteres discretos y bien definidos, la naturaleza del gen estaba lejos de ser obvia. En el interior de este último se hallan los cromosomas, unas estructuras complejas que aparecen de forma regular en cada ciclo celular, formadas (como sabemos ahora) por cadenas de ADN enormemente compactadas. Estas estructuras compactas aparecen vistas al microscopio como hilos más o menos similares. Resultaba extraño entonces, como señalaba el genetista William Bateson, que «las partículas de cromatina, indistinguibles una de otra [...] puedan por su naturaleza conferir las propiedades de la vida». Y aquí reside de hecho el punto clave del problema: ¿cómo es posible que una enorme cantidad de atributos y caracteres distintos se almacenen en simples moléculas? Con el paso del tiempo, varios experimentos elegantes demostraron que los «genes» estaban constituidos por un tipo de estructura molecular denominado ácido nucleico, pero antes de llegar a esta constatación, un científico conocido por su labor en el nacimiento de una nueva física dio un argumento premonitorio de lo que cabía esperar.
Cristales desordenados
Erwin Schrödinger es uno de los gigantes intelectuales que construyeron el edificio original de la mecánica cuántica, una teoría que, junto con la relatividad, cambiaría para siempre la física y nuestra visión del universo. A Schrödinger le debemos una pieza esencial de esta teoría: la ecuación que lleva su nombre y que nos permite describir la naturaleza de los fenómenos cuánticos en términos de ondas. Merece la pena mencionar que, aunque esta ecuación lo llevó a los altares de la física (de los que no ha bajado), nunca le gustaron las extrañas implicaciones y paradojas de la disciplina que ayudó a crear, hasta el punto de llegar a decir que «no me gusta, y lamento haber tenido nada que ver con ella». Pero Schrödinger también dedicó esfuerzos notables a distintos aspectos de la filosofía de la ciencia y a tratar de llevar el método científico y la forma de abordar los problemas de la física al territorio de la biología. En 1944 publicó un breve libro titulado ¿Qué es la vida?* en el que resumía unas conferencias acerca de este tema, entonces nebuloso. El libro es interesante desde la perspectiva histórica, dado que nos ofrece una visión singular, basada en gran medida en la física, de la biología anterior a la revolución de los años cincuenta. La sugerencia más interesante y (a posteriori) sorprendentemente acertada, es la de que, cualquiera que sea su soporte molecular exacto, la información genética debe hallarse en lo que Schrödinger denominó «un cristal aperiódico». Sin conocer la que sería la imagen de marca de la revolución de la biología —la doble hélice—, este físico comprendió antes que nadie que un sistema capaz de reproducir de forma regular algún tipo de información debía poseer una organización que le permitiera preservarla de manera reproducible. Un cristal o un sistema similar podría proporcionar esta característica.
Los cristales convencionales, como los cubos de distintos tamaños que forman la sal de mesa, son a nivel microscópico redes regulares basadas en la repetición de una estructura básica. En el caso de la sal empleamos dos tipos de átomo, cloro y sodio, que combinados dan lugar de forma espontánea a una malla cúbica que se va repitiendo, como vemos en la figura 1.3. Esta estructura la podemos observar a simple vista, con lo que de hecho podemos decir que un efecto cuántico (la unión de sodio y cloro mediante unos enlaces específicos) acaba dando lugar a una estructura macroscópica: el cristal, que para nosotros es pequeño pero para los átomos que lo forman es gigantesco. Los cristales son el paradigma del orden y podríamos pensar que, de alguna manera, tienen cierta capacidad de «autocopiarse», ya que una vez que se crea una semilla sobre la que el cristal pueda crecer, lo hará de forma predecible siguiendo el esquema regular que le permiten sus enlaces químicos. ¿Podríamos imaginar un planeta en el que una forma de vida existiera basándose en un mecanismo de este tipo? Una química tan simple da lugar a estructuras simples que carecen del potencial de adaptación de un sistema vivo tal y como lo conocemos. Cualquier sistema que crezca simplemente añadiendo más materia de forma estable y rígida no podrá producir ninguna innovación. Sin diversidad de estructuras, no es posible almacenar información y aún menos reaccionar de forma flexible a los cambios externos.
Un cristal sería demasiado simple y predecible, así que de algún modo en la base molecular de las células debería ser posible incluir la información compleja y diversa dentro de una estructura periódica. El hallazgo de Watson y Crick confirma de manera espectacular la predicción de Schrödinger: la molécula es una cadena totalmente regular que hace el papel del «cristal» y de hecho la evidencia de la doble hélice provino del estudio cristalográfico de preparados de ADN que permitían observar su periodicidad. Pero esta cadena doble puede crearse mediante combinaciones virtualmente infinitas de secuencias de cuatro nucleótidos: los bloques básicos que definen el alfabeto de la vida. Estas letras son A, G, C, T, que indican los nombres de los cuatro tipos de nucleótidos: adenina, guanina, citosina y timina. Las secuencias resultantes de combinar el alfabeto del ADN han permitido establecer las raíces de la evolución de los sistemas vivos, estudiar la variabilidad de nuestra especie y cómo hemos cambiado a lo largo de millones de años. Estos bloques básicos aparecen combinados en pares A-T y G-C a lo largo de las cadenas (véase la figura 1.4) y este apareamiento nos lleva de forma automática a la base molecular de la herencia: tenemos dos cadenas complementarias que se entrelazan dentro de la doble hélice. Si las separamos, tendremos dos cadenas «hijas» a partir de las cuales se puede replicar cada cadena complementaria de nuevo, con lo que habremos generado dos copias de la cadena inicial. Pocas veces en la historia de la ciencia se ha producido una idea tan elegante y poderosa. Watson y Crick no discutieron esta idea clave en detalle en el artículo (de una sola página) que en 1962 los llevó a obtener el Premio Nobel de Medicina y Fisiología. Pero al final del texto, dejaron claro que conocían muy bien el alcance del hallazgo: «No se nos ha pasado por alto que el emparejamiento específico que hemos postulado sugiere inmediatamente un posible mecanismo de copia del ADN».

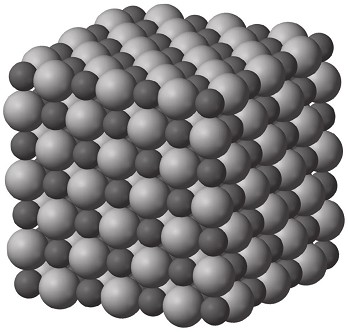
Figura 1.3. Orden natural. Los cristales de sal (arriba) son estructuras que se forman de manera espontánea cuando dejamos que una disolución de cloruro sódico (sal de cocina) se evapore hasta dejar sólo los átomos de sodio y cloro, que se ordenan formando una malla con simetría cúbica (abajo) en la que indicamos de forma ideal la posición de los dos tipos de átomos.
De un plumazo, el modelo de Watson y Crick explicaba la naturaleza de la información genética y de qué modo se heredaba. La elegancia de esta solución llevó al mismo Watson a señalar que una estructura así «por fuerza debía existir». Y lo cierto es que este esquema simple ha sido adoptado por todos y cada uno de los sistemas vivos que conocemos, desde las bacterias que habitan las chimeneas en ebullición de los fondos marinos o los líquenes que sobreviven en las montañas más altas del planeta, hasta los seres humanos, que comparten con todos ellos un origen común. También ha terminado formando parte de las majaderías que algunos políticos suelen decir, como «llevamos la honestidad en el ADN». Cómo pueda estar escrita la honestidad en la doble hélice es un verdadero misterio, aunque intuyo que quien emplea estas palabras no tiene ni idea de qué es el ADN y por ese mismo motivo hace una afirmación muy poco honesta. En cualquier caso, el ADN constituye la base molecular por la que la vida es capaz de propagar la información y explorar —mediante mutaciones— el espacio de posibilidades que le ofrece la combinatoria. Esta capacidad de combinación es tan elevada que escapa por completo a nuestra imaginación.
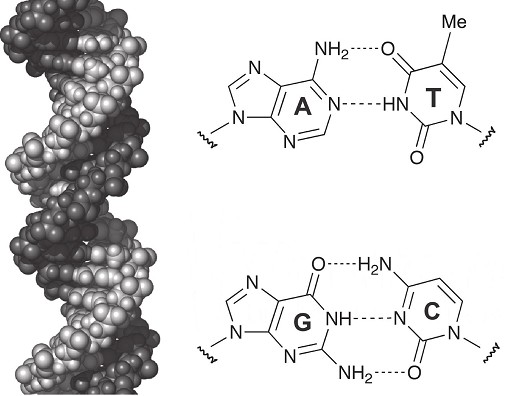
Figura 1.4. La base molecular de la herencia. El ADN (derecha) es la molécula empleada por nuestras células para empaquetar la información genética. Esta doble hélice está formada por dos cadenas complementarias construidas a partir de un alfabeto de cuatro «letras» (A, T, G, C) que forman pares A-T y G-C. Dado que podemos crear cualquier secuencia de letras, la cadena regular incluye en su interior un mensaje con, virtualmente, infinitas posibilidades.
Tal y como señala el biólogo Richard Dawkins, nuestra simple existencia (la de cada uno de nosotros) es el resultado de una lotería de naturaleza astronómica. Nuestro genoma, esta combinación particular de letras ordenadas en una secuencia única, es una singularidad entre un número de posibilidades muy superior al número de los átomos que existen en el universo. Otras secuencias, nos dice Dawkins, hubieran permitido tener a «científicos más grandes que Newton y poetas más grandes que Keats». Así es. La naturaleza del código y su potencial también definen un cosmos de posibles seres humanos del que tan sólo observamos una diminuta isla de individuos afortunados. Pero bajo la superficie de esta aparente aleatoriedad, de esta sobreabundancia de posibilidades, existe algo único: el código que ahora mismo emplean nuestras células es un código singular, uno entre millones.
El código perfecto
En prácticamente todos los aspectos de nuestra vida diaria participan elementos relacionados con una de las mayores revoluciones de la historia: la que produjo los ordenadores y los programas informáticos. Nuestros electrodomésticos, relojes, automóviles y ordenadores funcionan gracias a aquella revolución. Nuestra capacidad para acceder a redes de información y comunicarnos con grupos sociales extensos, para consultar bibliotecas o bases de datos virtuales de dimensiones insospechadas o guiar una sonda robótica de la que nos separan millones de kilómetros de distancia es en gran medida nuestro triunfo final sobre la información. A mediados del siglo XX la convergencia entre diversos resultados matemáticos de enorme importancia y la necesidad de mejorar la predicción de la trayectoria de proyectiles en el campo de batalla llevó al desarrollo de los primeros ordenadores, que permitieron superar nuestra limitada capacidad de hacer cálculos largos y complejos. Somos falibles y somos lentos. Y la necesidad de vencer al enemigo en tiempo de guerra favorece el empleo de recursos extraordinarios que hacen posible —a veces— alcanzar soluciones extraordinarias.
A medida que la nueva tecnología iba adquiriendo forma, la biología molecular empezaba también a desarrollarse. Muchos términos empleados en la segunda proceden de hecho de la primera, como las palabras «código», «traslación», «transcripción» o «codificación/decodificación». Y a medida que se desarrollaba nuestro conocimiento de los mecanismos moleculares de la vida, fueron surgiendo con claridad los procesos mediante los cuales la información contenida en el ADN se «lee» y da lugar a las funciones necesarias para mantener las células activas. El ADN actúa como el software celular, y cada gen puede entenderse como una secuencia que posee un comienzo (codificado mediante cierta secuencia) y un final (la secuencia de terminación). Estas cadenas son leídas y se generan otras cadenas de ácido ribonucleico o ARN. Este ARN es también una cadena, mucho más corta, que emplea un alfabeto distinto: A, G, C y U (uracilo) y en la que tan sólo cambia una letra. Esta molécula, menos estable que el ADN, puede dar lugar a su vez a una proteína pero puede también controlar la actividad (o «expresión») del propio ADN. En la figura 1.5 vemos una ilustración esquemática del denominado proceso de «transcripción», por el que se lee la cadena de ADN y se sintetiza un ARN. Para llevar a cabo este proceso se necesita una molécula «lectora» que se conoce como ARN polimerasa. Esta molécula es capaz de detectar determinadas secuencias que marcan un punto de inicio en la cadena de ADN y, en ese caso, de unirse a la doble hélice, iniciando así el proceso de creación de un ARN cuya secuencia está determinada por la secuencia de ADN leída. A medida que la polimerasa va leyendo la secuencia, se desplaza a lo largo de la cadena y se van conectando entre sí las letras del ARN (empleando los materiales del medio celular) hasta que se llega a otra secuencia que indica que la lectura debe terminar. Aquí la polimerasa se desprende. El ARN se ha sintetizado siguiendo un proceso simple que tal vez ya nos sea familiar: la polimerasa no deja de ser una máquina lectora molecular que identifica caracteres en una cinta (el ADN) y lleva a cabo su lectura a la vez que traduce el código inicial (AGCT) a otra cinta de salida en un código ligeramente distinto (AGCU). Una vez terminado el proceso, la máquina se detiene y entra en un estado en el que puede repetir el proceso. De hecho, esta detención puede entenderse como el punto final del programa ejecutado. Ahora nos falta un paso adicional, ejecutado de nuevo por una máquina enorme y compleja denominada ribosoma.
El ribosoma es uno de los grandes protagonistas de nuestra historia y una de las piezas que ocupan el interior celular de forma muy visible. El ribosoma «lee» ahora las cadenas de ARN y crea un nuevo tipo de cadena, esta vez formada por letras pertenecientes a un nuevo alfabeto. Este alfabeto tiene 20 símbolos: los aminoácidos. El ribosoma es nuestra máquina de Turing molecular. Los 20 aminoácidos deben ser ahora codificados a partir del código de cuatro letras, y no se tardó mucho en comprender que esta codificación requería que el ribosoma leyera secuencias de tres letras del ARN (los llamados «codones», como AAA, AGC o GUG) y las interpretara adecuadamente como aminoácidos distintos. El esquema de lectura está resumido en el diagrama de la figura 1.6 (arriba), en el que tenemos (a la manera de Llull) de dentro afuera las tres letras de cada cadena de tres letras y en la parte externa el aminoácido concreto que codifica cada codón. En algunos casos, como ocurre con los codones UAA, UAG y UGA, no se codifica un aminoácido. En lugar de ello, nos encontramos con una instrucción de parada (STOP) que detiene el proceso de creación de la proteína. Este esquema es compartido por la inmensa mayoría de especies vivas existentes, o como dijo el gran Jacques Monod: «Lo que vale para la bacteria vale para el elefante». Pero aquí nos preguntamos por algo aún más fundamental: de todas las posibles formas en que podríamos haber dibujado este esquema, ¿por qué precisamente ésta?
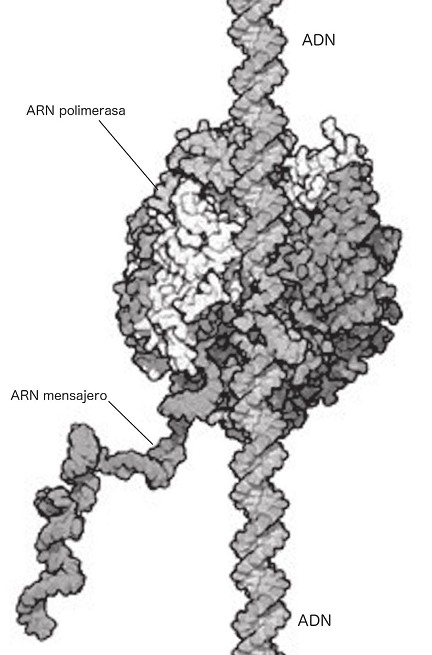
Figura 1.5. Transcripción del ADN. La molécula de ADN es «leída» por una molécula especial, la ARN polimerasa, que identifica un lugar de «comienzo» y un lugar de «fin» que delimitan la secuencia de un gen. Esta molécula es una nanomáquina que, a medida que va leyendo la secuencia de ADN, va sintetizando (transcribiendo) una nueva molécula de ARN, que será a su vez leída por los ribosomas para crear proteínas (dibujo de David Goodsell).
Un problema muy importante, que ya fue percibido por los pioneros del código genético, es el de reducir los errores que pueden surgir cuando, debido a una mutación, una letra de nuestro alfabeto es modificada. En la figura 1.6 vemos por ejemplo que el aminoácido leucina se obtiene para los codones CUU, CUC, CUG y CUA. La última letra puede por lo tanto modificarse sin que cambie el resultado. Pero si es la letra central la que cambia, por ejemplo, si en lugar de UGA tenemos UCA, entonces también se produce un error en el aminoácido resultante, que ahora es serina. Dado que las mutaciones son fuente constante de cambio en el código genético, así como en cualquier proceso de lectura y escritura, sus efectos pueden ser más o menos importantes dependiendo del impacto que tienen en el resultado final.
Y aquí reside la clave de la respuesta que buscamos. Aunque una mutación puede cambiar el aminoácido resultante, las propiedades químicas del aminoácido «equivocado» (por ejemplo su afinidad con el agua) pueden ser bastante similares a las del «correcto», de modo que el efecto sea poco importante. Empleando un potente programa informático y teniendo en cuenta lo que sabemos de la química de los distintos aminoácidos que emplean nuestras proteínas, los bioinformáticos Stephen Freeland y Laurence Hurst decidieron abordar el problema generando millones de posibles discos de combinación (algo que a Llull le hubiera sido muy útil) y midiendo para cada uno de ellos el grado de error cometido cuando alteramos los codones cambiando una letra al azar. En la figura 1.6 (abajo) vemos el resultado de esta investigación, que demuestra que, salvo un caso, el código genético tal y como lo conocemos es el mejor de todos. La gráfica nos muestra la frecuencia de códigos (eje vertical) que presentan cierto grado de error (eje horizontal). Vemos que la gran mayoría ocupan un dominio intermedio con errores altos y la flecha señala el lugar que ocupa el código de la vida tal y como la conocemos en nuestro planeta. La posición de esta solución nos dice que nuestro código ocupa un lugar privilegiado, inequívocamente distinguible y claramente optimizado por la evolución. Muy pronto, durante las primeras fases de la emergencia de vida sobre la biosfera, las máquinas moleculares y su diseño de construcción fueron seleccionadas para leer cintas que no podemos ver a simple vista, pero que Alan Turing ya imaginó —sin saberlo— décadas antes del descifrado de la piedra Rosetta celular. Tal vez hubo otros códigos al principio que coexistieron con el ganador, pero los organismos que los portaban estarían con toda seguridad en una situación de inferioridad. Sin poder reducir eficientemente el impacto de las mutaciones inevitables, su descendencia se vería menos capaz de afrontar los cambios medioambientales y evolucionar. Hace unos 4000 millones de años, de entre una inmensidad de posibilidades, una fuerza de enorme poder —la selección natural— extrajo la solución ganadora. Y aquí sigue.
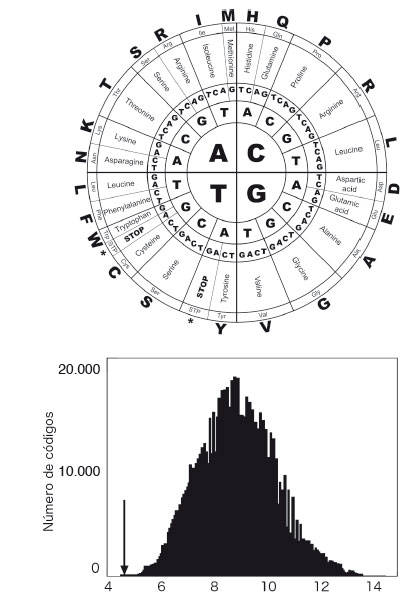
Figura 1.6. El código genético codifica, para cada trío de letras (un codón) del ARN (A, C, G, U), un aminoácido. Esto puede describirse mediante las combinaciones posibles de sus cuatro letras que permiten los tres discos de la figura superior. Cada codón codifica un aminoácido (indicado en el círculo externo) o bien una señal de inicio o de parada. El código podría ser cualquiera, pero es el mejor entre un millón. Un estudio de millones de posibles códigos (variantes del de la figura anterior) permite determinar el error cometido en cada uno de ellos. En la figura de abajo vemos que el error cometido por el código natural (flecha) demuestra que es un óptimo.