Capítulo I
Entendiendo el big data
1. La utilidad es la clave
Los avances tecnológicos sucedidos en los primeros años del siglo XXI han dado paso a un importante cambio en el paradigma de la comunicación, permitiendo intercambiar y sustituir todos aquellos agentes que tradicionalmente iniciaban el proceso comunicativo. Así, hoy en día, emisor y receptor desarrollan habilidades y manejan herramientas que les permiten intercambiar sus roles. Internet fue, en su momento, el gran democratizador que ofrecía información a todas las personas y, a su vez, todo el mundo podía compartir información.
Que las personas vieran la utilidad de las redes sociales digitales fue sin duda otro hito importante en la hoja de ruta de la participación social y, poco a poco, la industria de los medios, entendida como tradicional emisor, quiso participar de dicha utilidad. Hoy en día, como usuarios de las nuevas tecnologías, presenciamos cómo el tsunami digital arrasa con hábitos y costumbres, además de proponer nuevas profesiones, términos o maneras de comunicarnos que hace tan solo unos años no hubiéramos imaginado. La hoja de ruta de las nuevas tendencias viene marcada por empresas disruptivas que apuestan por tecnologías ya presentes como la singularidad tecnológica, la realidad aumentada, el cloud computing o el uso de wearables, entre otros.
La industria de la comunicación, concretamente la relacionada con medios audiovisuales más tradicionales como el cine, la televisión o la radio, ha encontrado en el uso de internet la posibilidad de transformar su modelo de negocio, cambiando, por lo tanto, la manera en la que acerca sus productos a la audiencia. Esto ha supuesto un cambio en la mentalidad de todos los agentes que forman parte de la cadena de valor. Viendo estos elementos con cierta perspectiva, nos encontramos en primer lugar con los creadores de contenido, quienes han visto cómo sus historias podrían ser contadas en diferentes plataformas, enriqueciéndose y retroalimentándose. Hablamos, por ejemplo, del transmedia. En segundo lugar, los productores y distribuidores de contenidos también se sitúan en un momento álgido debido, principalmente, a la cantidad de datos que han ido atesorando desde los últimos años, información relativa al consumo pero, también, al consumidor. En esta línea, resalta también la importancia de los destinatarios o los ya mencionados consumidores de dichos productos audiovisuales, quienes son más conscientes que nunca del poder del consumo on demand, algo que les permite decidir cuándo, dónde y qué ver. A esta modalidad de demanda se suma la ya realidad cotidiana del uso de redes sociales a través de las que comunicar, emitir juicios críticos y, básicamente, hacer valer su opinión sobre los productos consumidos. Todas estas acciones en la era de las TIC derivan en la generación de datos. Esto es una información muy variada, son registros procedentes de las audiencias, de los consumos y de los usuarios que demandan sus contenidos a través de formularios en aplicaciones o en webs de canales de televisión o simples puntuaciones y recomendaciones de los espectadores. Asumir que esa información es valiosa, ordenarla y extraer de ella decisiones de negocio para futuras acciones ofrece una ventaja y un valor indudable para todos. Esto es la gestión masiva de datos, también denominada big data, palanca de cambio de nuevas acciones y decisiones. Pero, como repetiremos a lo largo de estas páginas, los datos en sí mismos carecen de valor, la importancia radica en el uso que se haga de ellos.
2. Gestión de datos masivos en la empresa
La revolución industrial que ha supuesto la aparición de TIC disruptivas ha marcado claramente el paso del período en el que usábamos la tecnología como proceso mecánico a entenderlas como un elemento productivo, con su consiguiente impacto tanto a nivel industrial como a nivel individual del usuario en un marco amplísimo de posibilidades. El big data como tendencia surge, pues, cuando la industria se da cuenta de que no puede almacenar ni manejar la información de manera convencional; es por lo tanto un paso lógico en el proceso del uso de las TIC. Comprender las posibilidades del big data en cada industria supone entender las dinámicas internas, así como las fuentes de datos generables de las que podemos disponer y la interacción que podemos realizar en ellas. Pero también es importante entender que todo forma parte de un proceso de negocio, que el uso masivo de los datos ofrece nuevas posibilidades de orientar los negocios. Volvemos a insistir: es fundamental entender que los datos en sí mismos carecen de valor, dado que es precisamente lo que se haga con ellos lo que les va a dar importancia.
Si hacemos una foto de aquellas industrias que establecen en su modelo de negocio una relación con la gestión masiva de datos, quizás el sector aeronáutico sea uno de los que mayor ventaja tiene, seguido de la banca, los seguros, el sector médico o el agrícola. Por citar algunos ejemplos, el sector de la medicina encuentra la utilidad del big data en el cruce de datos anónimos con el propósito de obtener conclusiones más precisas y rápidas sobre hallazgos científicos. Un buen exponente es Research Kit, la plataforma de datos abiertos de Apple. Por otro lado, en cuestiones agrícolas, la startup española Cubenube dispone de gestión cloud de datos agrícolas con idea de minimizar riesgos en las plantaciones. En el caso de la industria del turismo, los destinos turísticos reciben un implacable impulso para convertirse en smart cities, respaldo tanto de la iniciativa privada con clusters como SmartCitiesLab, formado por Telefónica, Intel, Admira o Ficosa, o también desde la esfera pública a través de Segittur, que lidera el proyecto Destinos Turísticos Inteligentes desde el Ministerio de Industria, Energía y Turismo. En España, son los grandes grupos empresariales los que están promoviendo iniciativas innovadoras a partir del uso del big data con idea de tener un rol importante en la transformación tecnológica. En esta línea, el BBVA promueve acciones cloud computing y big data a través de la consultora Beeva y la gestión del talento digital a través del Centro de Innovación. O también desde Bbva Data & Analytics y el análisis de datos. Otro ejemplo es el grupo Telefónica y su espacio de Innovación o incluso de aceleradora de proyectos empresariales digitales, Wayra. En general, podemos deducir la apuesta clara por negocios que relacionen el big data con industrias tanto tradicionales como emergentes.
Para todas estas industrias y empresas, la integración del big data en sus estrategias y procesos está entendida siempre como mejora desde un punto de vista estratégico. Centrándonos en el caso del sector audiovisual, y desde una perspectiva internacional, la empresa de software Netflix se presenta como uno de los más rentables casos de uso del big data y business intelligence. Con una envidiable política de transparencia, ofrece a través de su Netflix Tech Blog1 toda la información posible sobre su funcionamiento interno. Netflix es un canal de video on demand (VOD). Ellos se definen a sí mismos como una aplicación que ofrece sus servicios a través de una conexión a internet; esto permite una serie de acciones bidireccionales entre el canal y el espectador. Para ello, es importante tener categorizada o etiquetada la información. Así, desde 2007, la empresa ha contratado personal (los denominados taggers) destinado a visualizar determinados títulos con idea de identificarlos con etiquetas (tags) y proceder posteriormente a su indexación.
Con idea de entender el proceso de adjudicación de etiquetas, es interesante comprender que el valor de la gestión masiva de datos radica, en primer lugar, en poder encontrar la información que buscamos en un entramado de redes cambiante y volátil; esto es, internet. Las características de la web, tal y como la conocemos hoy, hicieron necesaria la aparición de un sistema organizativo que permitiera la catalogación y búsqueda de información,2 esto es, motores de búsqueda que habitualmente usan los usuarios; quizás sea Google el más conocido y usado, junto con otros desaparecidos o en uso como Yahoo!, Altavista o Lycos. Mención especial merece la WorldWideWeb, la red de redes, el primer buscador que centraba su acción en un motor de búsqueda capturando URL.3 En 2005, el etiquetado de los contenidos realizado por usuarios se gestó en la red social del.icio.us, respaldada por Yahoo! y, actualmente, este etiquetado es la base de las redes sociales con idea de proceder posteriormente a la búsqueda e identificación de datos.
En el caso del buscador más empleado por los usuarios, Google, el motor de búsqueda de datos no se centra en el tagging,4 sino que prioriza webs en función de su popularidad. Para ello, patentó el denominado page rank, un algoritmo vivo que evoluciona, se retroalimenta y se actualiza continuamente. Su base de trabajo establece el criterio de «popularidad» en función del número de webs que enlazan al site, además de otros valores como la calidad de las webs de referencia.5 En este sentido, el resultado es un baremo de 0 a 10 que hace que las páginas web con un page rank más alto aparezcan primeramente en una búsqueda aleatoria.
A partir de aquí, dado que las búsquedas en internet no son privadas, es posible para las empresas intervinientes saber qué tipo de búsquedas se realizan. Más aún, en el caso de identificar los perfiles de usuarios que realizan búsquedas, es posible no solo conocer los gustos de manera personalizada sino intuir posibles nuevas búsquedas a realizar por dicho usuario. Llevado a términos de negocio, los motores de recomendación en función de métricas, algoritmos y predicciones hacen el resto. El objetivo es ofrecer una herramienta de hiperpersonalización. Pongamos, por ejemplo, el sector audiovisual, donde las empresas capaces de gestionar datos y acciones de usuarios a través de las TIC son propensas a ofrecer contenidos audiovisuales hiperpersonalizados e hipersegmentados a través de un canal de televisión, aplicación o dispositivo. Para ello se recaban datos básicos a través de la monitorización en tiempo real del consumo audiovisual. Esto es, qué producto se está visionando y las acciones que se realizan sobre él, ya sea play (visionado), pausa, repetición, avance o parada. Además, pueden obtenerse más datos referentes a la geolocalización, las valoraciones que se hacen, opiniones, etc. Esto es información masiva por cada usuario (big data); la gestión de la misma para detectar la información útil para la empresa y las decisiones estratégicas que se tomen para cumplir los objetivos empresariales, por ejemplo en el caso de Netflix, serán lo que la convierta en una empresa con un negocio que entiende las posibilidades de las TIC. De tal forma que este negocio no ofrece al usuario todo lo que busca o quiere, más bien ofrece al usuario todo aquello en lo que está interesado, dado que eso dicen los datos.
2.1. El ecosistema en línea
En el tiempo que leemos esta página se enviarán 277.000 tuits, se subirán a YouTube setenta y dos horas de vídeo y se harán cuatro millones de búsquedas en internet. Pero no es solo una cuestión de cantidad, sino también de incremento veloz. Una comparativa para tener más perspectiva nos cuenta que en 2013, en un minuto, se enviaron 11,8 millones de comentarios a través de WhatsApp, y en 2015 suman ya 44,4 millones. También, en ese mismo minuto, se ha pasado de publicar 817 post a 1.212 solo dos años después.6 La UIT indica que el grado de penetración de internet se ha multiplicado por siete desde el año 2000. Y actualmente 3.200 millones de personas acceden a internet. En general, la aparición de nuevos dispositivos y aplicaciones, la oferta de tarifas de datos más competitivas en gigas y precio, sumado a un rol activo y social por parte del usuario de las nuevas tecnologías, todo ello, ha propiciado un ecosistema proclive al intercambio de información. De hecho, el 83 % de los usuarios de teléfonos smartphones usa a diario redes sociales desde el móvil y nueve de cada diez internautas habituales disponen de una cuenta activa en las redes sociales más demandadas.7 Ante este panorama, es entendible que en el uso diario de internet se generen grandes volúmenes de datos y metadatos. Podemos concretar, por tanto, que el big data es el término empleado para referirse a toda aquella cantidad ingente de datos que, debido a sus características, no pueden ser siempre procesados por los sistemas informáticos actuales. Como veremos más adelante, puede ser una cuestión de volumen, lo que hará que se necesite trabajar con grandes almacenes de datos físicos (data centers) o en la nube. Pero también podemos valorar características como la escala temporal o velocidad, lo que va a permitir establecer predicciones. En este sentido, muchos algoritmos no están preparados para adaptarse a cambios tan rápidos.
Estos datos masivos pueden ser informaciones volcadas en la red de internet o almacenadas de manera privada en las empresas. Sea como sea, tradicionalmente estos datos estaban disponibles de manera offline, sin conectividad entre ellos. Hablamos aquí de documentos Word, tablas Excel, reclamaciones, encuestas telefónicas o documentos de subscripción, entre otras muchas modalidades de ofrecimiento de datos. Cada uno de estos son documentos que toda empresa realiza con idea de generar o transcribir la información que produce su empresa. Los documentos Word pueden ser guiones cinematográficos o las hojas Excel listados de una base de datos de series televisivas con diferentes campos, en columnas, con datos relativos a fechas, nacionalidad, género o minutos de duración. Es decir, un sinfín de datos organizados de maneras diferentes según cada empresa.
Pero, además, cada persona, como usuario de internet, también genera datos, consciente o inconscientemente. Así, en la actualidad, prácticamente cualquier uso que hagamos de una herramienta digital conlleva el acto de lanzar datos al escenario de internet. Por ello, cada vez que compartimos información estamos generando datos y/u opiniones. Pongamos como ejemplo un acto tan rutinario como enviar un correo electrónico, publicar una actualización en una red social, clicar un «me gusta» en una foto, publicar la puntuación obtenida en un videojuego o aceptar la política de cookies de las páginas web. El hecho de compartir o interactuar con toda esta información supone que se están generando datos y más datos al universo de internet pero, además, estamos vinculando, en la mayoría de los casos, dicha información con un perfil de usuario. Esto es así porque, para casi cualquier acción en la web, debemos previamente identificarnos y esta es una información que se adjunta a los datos que vamos a compartir. Si pensamos en los teléfonos móviles, desde hace unos años han sido reemplazados por smartphones, lo que nos permite interactuar con aplicaciones, descargas, internet, pero, para todo ello, es necesario previamente identificarnos con un usuario, una imagen, un nombre, incluso una cuenta bancaria. Desde ese momento estamos generando una actividad comercial por la que se entiende que, al no pagar por unos datos que el usuario ha ofrecido, el producto resulta ser el mismo usuario. En general, podríamos decir que actualmente los usuarios se han acostumbrado a consumir servicios de manera gratuita. A cambio, podemos entonces hablar de miles y millones de usuarios sin limitación geográfica que diariamente ofrecen sus hábitos de consumo y perfiles personales de manera gratuita al universo de internet. A partir de aquí, es lógico pensar que las empresas puedan recrear sus modelos de negocio al saber exactamente qué piensa su cliente de sus productos o qué apreciación se tiene de su marca. Más aún, dependiendo del grado de penetración de la tecnología, se puede afinar con gran exactitud cuáles son los hábitos de consumo de sus clientes, así como elaborar una radiografía de los mismos a cualquier hora del día; esto es la denominada categorización de perfiles, tremendamente útil para elaborar acciones comerciales como el marketing inbound. Visto con perspectiva y utilidad publicitaria, el big data ofrecería un índice de impacto altísimo, casi sin margen de error, dado que los productos ofrecidos podrían estar hechos a medida. Bajo este abanico de posibilidades, es viable establecer patrones de consumo y predicciones que, en el ámbito del negocio, busquen un fin concreto: tener contento al usuario, ofreciendo, cada vez más, productos a medida.
2.2. Principales características del big data
Si analizamos toda la información que las empresas pueden obtener dentro del abanico llamado big data, encontramos que se dan una serie de características comunes. Estas son las denominadas volumen, variedad, veracidad y velocidad. Son las principales características que definen el big data y es así para cualquier industria o sector con el que lo estemos relacionando. El volumen hace referencia a la gran cantidad de datos disponibles o accesibles. Hay que tener en cuenta que muchos de esos datos no serán útiles porque no tendrán calidad o porque no forman parte de nuestra estrategia; con todo, el volumen de información es enorme, continuo y creciente. En esta línea, las diversas fuentes de información de donde poder obtener datos dan paso a la siguiente característica, la variedad. Podemos obtener datos estructurados y organizados o datos desestructurados, datos provenientes de imágenes, texto, música, cifras, tablas de Excel, transacciones, etcétera. Esta variedad genera valor en el big data, pero también complejidad a la hora de trabajar la información. Por ello, la veracidad como característica, pero también la calidad de los datos como propósito. Sumado a estas acciones, la velocidad en la generación de datos es trepidante y afecta a todos los eslabones en la toma de decisiones: son muchos los datos que se generan por hora, minuto y segundo. Esta velocidad hace que la toma de decisiones deba tomarse también con cierta celeridad, de ahí la complejidad: mucha información cambiante por su magnitud, sobre la que hay que tomar una decisión.
Una vez que comprendemos la cantidad de datos disponibles a través de las nuevas tecnologías, así como el amplio abanico de acciones para obtener dichos datos, el siguiente paso es incorporar la capa de negocio. Es decir, identificar cómo las empresas son capaces de analizar y extraer conclusiones de los datos con la idea de que puedan aplicarlos a su entorno y realizar acciones como predecir comportamientos de los clientes, identificar gustos por grupos de usuarios o segmentación y su posterior aplicación de analítica de marketing. El objetivo estratégico del esfuerzo de obtención de datos consiste en un ejercicio de toma de decisiones, esto es, la denominada inteligencia de negocio o más popularmente denominada por su terminología inglesa: business intelligence. Este ejercicio empresarial heredero de los sistemas de toma de decisiones parte del big data para, conociendo cuantas más posibilidades, identificar la mejor opción de negocio para la empresa. Para ello se trabajan los datos y se realizan consultas, lo que viene a ser cruces de datos con idea de obtener no solo el mejor de los escenarios o decisiones, sino también estrategias o predicciones.
Desde el punto de vista empresarial, el proceso de trabajar con big data y business intelligence comenzaría por identificar una problemática de negocio. A partir de aquí se identificarían las fuentes desde las que se quieren obtener datos, siempre con un objetivo que permita poder aplicar business intelligence, analítica de marketing o estrategia de negocio. En orden cronológico, el proceso se representaría de la siguiente manera.
Figura 1. Flujo de procesos en un entorno big data
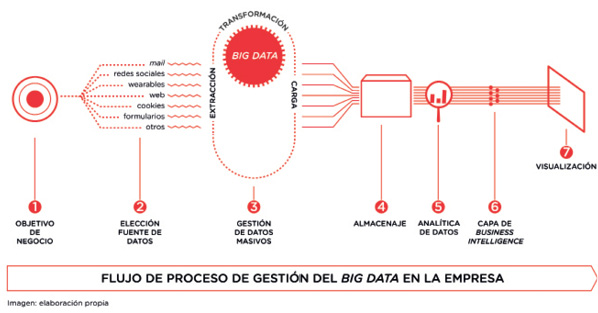
En los siguientes capítulos, vamos a explicar los distintos procesos que organizan un negocio o empresa que gestione datos masivos.
2.3. Elección de fuentes y proceso ETL
Como acabamos de sugerir, son muchos los datos que se pueden obtener tanto del entorno empresarial como del particular. Con idea de poner un poco de orden a la información lograda, las empresas que incorporan esta gestión masiva de datos trabajan siguiendo un proceso ciertamente estandarizado, el denominado ETL, siglas en inglés de los procesos de extract, transform and load que, en castellano, se conocen como extracción, transformación y carga. Este proceso forma parte del objetivo final de la gestión de los datos, que es aplicar business intelligence a la información analizada.
Figura 2. Proceso técnico de extracción de datos, transformación y carga.
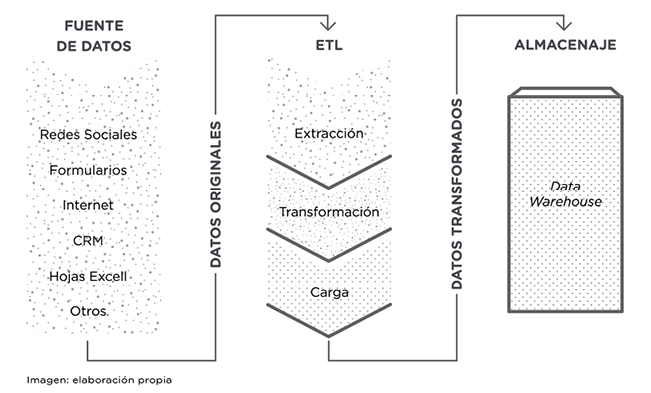
Vayamos en orden: la primera tarea denominada de extracción va a hacer referencia a la recopilación de datos procedentes de diferentes orígenes. Hemos comentado anteriormente que los datos pueden ser generados por individuos, por empresas, por máquinas, etc. Es decir, el tipo de datos o sus fuentes de procedencia son diversos. Por ejemplo: pueden ser datos externos de redes sociales, repositorios (almacenes) operacionales, información procedente del seguimiento de las cookies o internos de los propios informes de la empresa. Pueden ser datos organizados según algún estándar o no. Esto se conoce como datos estructurados, semiestructurados o no estructurados. Los datos estructurados están organizados en un esquema lógico, permitiendo la aplicación de algoritmos para automatizar el proceso; estos son, por ejemplo, las bases de datos. En el caso contrario, las fuentes de datos no estructuradas no siguen ningún orden lógico; son documentos Word, transacciones, el CRM8 o presupuestos.
Siguiendo una catalogación bastante genérica, vamos a distinguir cinco tipos diferentes de fuentes:9
- • Web y medios sociales: datos generados en entorno web y redes sociales. Son básicamente producidos por las personas usuarias de internet.
- • Machine to machine (M2M): dispositivos o sensores que captan información y la retransmiten a otras aplicaciones a través de redes; es el denominado «internet de la cosas». Una acción de este tipo serían los indoor location system,10 las alarmas de las prendas de ropa, los wearables11 o los beacons.12
- • Transacciones: operaciones bancarias, registros telefónicos, etc. Son los intercambios de información.
- • Datos biométricos: referentes a las propias personas y generados por sus propios cuerpos, por lo que son personales e intransferibles. Huellas dactilares, escáner de retina, etc. El empleo de estas biométricas se asocia con temas de privacidad, seguridad e inteligencia. Pero también comienzan a generarse acciones con social media y comercio, como veremos más adelante.
- • Datos generados por las personas en el empleo de las nuevas tecnologías. Esta información es confidencial o privada en la mayoría de los casos; esto supone que, previo a su manejo, deben de ser convertidos en datos anónimos: informes médicos, correos electrónicos, grabaciones de conversaciones o fotografías. Pero también, parte de ella puede tener un acceso público como son los open data, encuestas, valoraciones o recomendaciones.
Como vemos, son muchas las fuentes de las que provienen los datos. El objetivo en la fase de extracción consiste en unificar toda esta información en un formato óptimo para que, posteriormente, sea transformada. Es decir, se busca la integridad de los datos tratando de que, a la hora de trabajar con ellos, se cause el menor de los impactos.
Una vez extraídos los datos, daría comienzo la fase de transformación. Esto se realiza según necesidades de negocio y vendría marcado por la estrategia que se quiera aplicar, los objetivos de la compañía, etc. Dentro de este proceso de transformación se detectan y corrigen inconsistencias mediante algoritmos avanzados de limpieza de datos. Este proceso de trabajo se refiere a la naturaleza intrínseca del big data, recordando las principales características asociadas: su variedad, velocidad, veracidad y, sobre todo, su volumen. Es lógico pensar que esa gran cantidad de información incluye una serie de datos erróneos que deben ser identificados y, posteriormente, corregidos o eliminados con idea de poder pasar a la etapa de carga de información. Básicamente, los errores que nos podemos encontrar son:
- • Errores sintácticos: hacen referencia a información que, escrita de diferente manera, puede ser igualmente válida. El ejemplo habitual de este tipo de errores es el caso de las fechas a la hora de rellenar información en la web. Para una persona, es la misma información 7/7/2015 que 7 de julio de 2015, pero para una máquina puede no ser lo mismo.
- • Errores semánticos: se producen dentro del contenido de los datos. Un ejemplo típico lo encontramos en las redes sociales. Así, en el caso de los hashtag, es interesante pensar que muchas veces los espectadores sociales escriben mal el nombre de un programa o generan su propio hashtag sin saber que hay uno oficial por parte de la cadena de televisión. Para evitar perder una gran cantidad interesante de datos al acotar la búsqueda únicamente a una palabra concreta, se estableció como medida que los programas de televisión susceptibles de generar audiencia optaran por dejar impreso en pantalla el hashtag.
- • Errores por información incompleta: campos de información vacíos. Esto es habitual en formularios en línea con muchos campos; así pues, es normal que se dejen preguntas sin responder. Eso sería un ejemplo de campo vacío.
La presencia de errores, sean del tipo que sean, producen fallos en la estrategia empresarial marcada y, al final, se traduce en unos mayores costos, de ahí la necesidad de sistemas de calidad de los datos. Estos son sistemas que trabajan de manera automatizada, y hay que tener en cuenta que muchos de los errores son humanos, por lo que puede surgir el conflicto.
Para asegurar la calidad de los datos, los expertos indican que supone cumplir una serie de características: completitud, conformidad, consistencia, exactitud, duplicación e integridad. A su vez, estos sistemas de calidad de los datos suelen coincidir en los mismos procesos: perfilado de datos, estandarización, correspondencia, consolidación y limpieza.
Por último, tendríamos un proceso de carga de datos. Aquí intervienen aspectos como valoraciones de a dónde van destinados los datos o el nivel de detalle de la información. Esta gestión se enmarca dentro de la arquitectura de datos y va a definir aspectos como el modelo de integración de datos o dónde van a almacenarse. Las opciones habituales de carga suelen ser dos: por un lado, un gran repositorio de datos denominado genéricamente data warehouse o, como alternativa, el almacenaje en la nube; esto, por ejemplo, puede ser el servicio Sapphire ofrecido por Microsoft que, como ellos mismos lo denominan, es «the site». Como ya hemos insistido, todas las fases tienen como objetivo una decisión de negocio, por lo que la selección de datos debe cumplir esos mismos propósitos. Visualmente, el proceso de identificación de las fuentes de datos y su posterior ETL quedaría completado de la siguiente manera:
Figura 3. Flujo de procesos en un entorno big data

2.4. Perfiles profesionales del big data
Hemos comentado anteriormente que hay sectores más proclives a trabajar con nuevas tecnologías, dado que rápidamente entienden las posibilidades que les ofrecen. Paulatinamente, industrias más alejadas de entornos TIC comienzan a incorporar lógicas de negocio que parten del big data para, posteriormente, incluir decisiones de negocio o análisis. Esto supone que comienza a denotarse una gran demanda de perfiles profesionales que sepan trabajar con datos, pero lo cierto es que apenas hay recursos humanos formados en estas nuevas tecnologías, lo que supone una brecha a la hora de inculcar determinadas nuevas tecnologías o procesos. Esto es, por lo tanto, una oportunidad laboral interesante.
Pasamos, a continuación, a resaltar los principales perfiles profesionales que van a gestionar áreas laborales vinculadas a los datos, así como sus principales funciones. Desde la parte más técnica, identificamos el arquitecto de datos (data architect) con unas competencias profesionales más centradas en las acciones relativas al proceso de almacenaje (data warehousing), extracción y movimiento de datos para su almacenaje en bases de datos. La responsabilidad de este perfil es grande, dado que su gestión relaciona datos, procesos y personas. El objetivo sería la integridad de los datos. La arquitectura de datos se relaciona con las siguientes áreas de acción sobre los datos: data governance, data structure, master data management, metadata, data quality y data security. Todas estas áreas y perfiles son novedosas, y son las propias consultorías y empresas de reclutamiento de personal las que, poco a poco, van definiendo sus competencias profesionales. La consultora Accenture concreta que «la arquitectura de datos describe los procesos, sistemas y organización humana necesarios para almacenar, acceder, mover y organizar los datos».13 Generalmente, este perfil tiene una formación previa en ingeniería de telecomunicaciones, informático o sistemas.
Otro de los perfiles clave a la hora de gestionar los datos es el científico de datos (data scientist), una propuesta multidisciplinar que engloba conocimientos de computación, matemáticas y estadística. Su función es decir cómo se van a hacer las cosas a través de la creación de modelos estadístico-matemáticos, por ejemplo, en el aprendizaje automático que, posteriormente, veremos con más detalle. Nuevamente, son las empresas que demandan estos perfiles las que están definiendo sus particularidades; así pues, para IBM,14 la empresa de tecnología y consultoría, este rol tiene o debería tener una formación multidisciplinar que englobaría ciencias de la computación, matemáticas, estadística, modelado y analítica. Además, se le adjudica cierta visión de negocio, capacidad resolutiva para identificar y resolver, así como habilidades comunicativas que permitan liderar proyectos tecnológicos.
Posiblemente, uno de los perfiles más definidos o conocidos, dada su trayectoria previa al big data, puedan ser los analistas de datos (data analyts). Este perfil realiza funciones de consultas y reporting, empleando para ello herramientas analíticas, y maneja lenguajes de consultas y análisis estadístico con el que obtener métricas aplicadas al negocio. Básicamente, sabe extraer conclusiones de los datos a partir de herramientas de alto nivel. La formación académica del analista de datos es diversa, desde una ingeniería superior, investigación de mercados, sociología, formación empresarial o ciencias de la información. Las habilidades analíticas se obtienen, en muchas ocasiones, a través de formación específica en ámbitos como herramientas de programación, estadística o matemáticas. Esto permite conocer herramientas y lenguajes específicos como Java, Hadoop, SQL, bases de datos o incluso herramientas de business intelligence y visualización como Cliqview, Tableau o MicroStrategy. Indicábamos antes que este rol profesional tenía cierta trayectoria previa dado que la labor analista es aplicable a todos los sectores industriales. Ahora, en la etapa del big data y del business intelligence, lo que cambia no es solo la cantidad de datos a la que tenemos acceso, sino también las nuevas habilidades y metodologías que se generan. Por ello, consultoras en TIC y big data como Beeva15 establecen que el analista de datos debería ser capaz de establecer el producto mínimo viable (PMV), modelización de resultados o capacidad de investigación y conocimiento del negocio.
Además, desde la perspectiva empresarial, las posiciones directivas estratégicas con conocimientos de tecnologías de big data y business intelligence se vuelven claves en entornos de toma de decisiones; son los estrategas de datos (data strategist). Entre sus funciones, destaca la toma de decisiones para optimizar negocios digitales a través de los datos y del análisis, gestión de cuadros de mandos y métricas, además de reporting, análisis de datos y visualización, entre otros. Se espera de este perfil profesional que tenga un sólido conocimiento técnico que pueda combinar con la gestión del negocio. Es decir, volvemos a tener descrito un perfil altamente multidisciplinar, flexible y adaptado a la peculiaridad de la empresa que lo necesita porque es importante recordarlo– una gran carga de su trabajo está relacionada fuertemente con el sector al que pertenece la empresa.
En el mercado laboral se ofertan posiciones para otros tantos perfiles relacionados con los datos, pero, quizás para una primera aproximación que comprende áreas de negocio, estos sean los más recurrentes. A modo de visualizar competencias, podemos considerar la siguiente imagen:
Figura 4. Perfiles profesionales en un entorno de trabajo big data

Junto con estos perfiles y competencias, el negocio de trabajar con el big data en las diferentes industrias ha propiciado, pues, la aparición de nuevos puestos profesionales desconocidos hasta hace apenas unos años, pero también ha reforzado la presencia de roles técnicos como desarrolladores y programadores. Perfiles que, al tratarse de aspectos técnicos y no tanto de negocios, no son ubicados en esta síntesis.
La consultora Gartner, a través de su estudio Predicts 2016: Information Stratey, y de manera pública en su newsroom,16 estimó que para el año 2019 el 90 % de las grandes empresas incluirá a un chief data officer (CDO) en sus plantillas. Esto supone una consolidación importante del potencial valor que tienen los datos en las organizaciones que incluyen negocios digitales. Entre otras, la consultora define que este rol debería asumir retos como las siguientes premisas:17
a) Crear estrategias de gestión de la información basadas en el propio negocio que identifiquen el valor como disciplina.
b) Construir relaciones de confianza con los diferentes roles directivos de la empresa, especialmente el chief information officer (CIO).
c) Formar líderes y compañeros en el papel que juegan los datos y la información en el éxito final del negocio.
d) Establecer líneas de gestión de la información y datos de monetización a partir de métricas establecidas en el negocio.
e) Identificar y cuantificar métricas de información e indicadores de rendimiento que permitan demostrar el éxito del negocio.
f) Adoptar los recursos de información formal y cuantificable para poder compartirlos con la empresa.
Fruto de esta nueva presencia de puestos profesionales y reclutamiento, comienza a verse una interesante apuesta de programas formativos en temas de analítica, gestión de datos (en todas sus posibilidades), business intelligence o visualización de datos. Propuestas de formación y reciclaje de perfiles profesionales tanto en áreas técnicas como estratégicas y de gestión.
3. Usos del big data en los medios
de comunicación
3.1. Social big data
La efectividad del big data cobra fuerza a través de la participación de los usuarios en las redes sociales digitales, especialmente en industrias como la audiovisual al contar con públicos con alta predisposición a opinar y recomendar. Esta tendencia es la denominada social big data y se ha convertido en una fuente de información excelente para los productores y creadores de contenidos.
Si establecemos una línea temporal del proceso de trabajo de un proyecto audiovisual, podemos deducir que usar estrategias big data en cada una de sus partes se convierte en una ventaja para el negocio. Según propone Neira,18 ya en una fase tan temprana como la de desarrollo, los datos de visionado y la monitorización de la actividad en redes sociales pueden establecer próximas líneas narrativas o predisposición por ciertos temas o actores. En la fase de preproducción, producción y postproducción, la interacción con el público a través de las redes y su posterior análisis puede permitir reforzar vínculos con el target correcto, además de generar engagement. Quizás, la etapa de distribución comercial del producto y sus estrategias de marketing y promoción sean las más visibles de todo el proceso. Son las ocasiones en las que el público puede participar de ese entramado de acciones comunicativas generadoras de datos, social big data. En los últimos años, el sector audiovisual encuentra en los proyectos transmedia un camino para desarrollar narrativas que cruzan diversas plataformas y medios. El propio Jenkins, creador del término transmedia, entiende estos proyectos (Jenkins, 2008) desde la convergencia y la cooperación entre industrias mediáticas que incorporan una audiencia cambiante y exploradora. Una cultura participativa donde el espectador puede producir y reelaborar contenidos, dando lugar al concepto de prosumer. Esta tendencia, tan familiar en los hábitos de los actuales consumidores de contenidos en la red, conecta con el social big data en el sentido de que hace posible ordenar toda esa cantidad de acciones que puede acometer el prosumer, convirtiéndolas a su vez en acciones de marketing y estrategias de negocio. Según comenta Linares,19 estas estrategias de marketing procedentes de los datos permiten generar una comunidad fiel, adaptar contenidos según el medio o el dispositivo y lograr diferentes niveles de implicación según el tipo de consumidor de contenido digital.
3.2. La audiencia: targets y usuarios
El uso del big data en el sector audiovisual español es muy reciente y se propaga tímidamente sobre sus industrias en mayor o menor medida. En el caso de la televisión, la gestión de los datos la convierte en una industria llena de posibilidades, aunque a fecha de hoy las iniciativas son muy escasas. Para entender el peso y la presencia de modelos de negocio tradicionales, es interesante echar la vista atrás y analizar desde el punto de vista de la investigación de la audiencia. Así, la industria televisiva encontró en los audímetros, durante muchos años, un gran aliado. Un audímetro es una herramienta similar a un mando a distancia20 en el que cada botón se identifica con un televidente, el cual debe indicar qué y cuándo ve la televisión. Actualmente, el parqué de audímetros es de 4.625, representativos del universo de estudio y repartidos aleatoriamente. Previamente, se realizaron otras acciones como las encuestas telefónicas del Estudio General de Medios (EGM), o las entrevistas sobre el recuerdo de la víspera. En general, estas acciones dependen considerablemente de la opinión y actuación de la audiencia, siendo cuestionada en numerosas ocasiones. Más allá de la dudosa rigurosidad en el procedimiento, la investigación de mercados basada en audímetros plantea un problema de base. Ciertamente, desde el punto de vista cuantitativo, es posible saber cuántos espectadores han apretado un botón que les identifica como audiencia de un determinado programa y canal. Desde el punto de vista cualitativo, esta información es plana, no hay opiniones, feedback o sentimiento.
La empresa internacional Kantar Media analiza y monitoriza, en España, la televisión, la radio e internet a través de los mencionados audímetros, además del análisis estadístico basado en la muestra representativa. Son conscientes de la evolución del consumo televisivo que ellos mismos concretan en su web:
- • El consumo de televisión en directo
- • La grabación y posterior reproducción
- • La televisión a la carta
- • El uso de aplicaciones interactivas
- • La navegación por las guías electrónicas de programación
A partir de aquí, se muestra necesaria la aparición de nuevas tecnologías que sepan integrarse en las diferentes modalidades de consumo. En el caso de la citada empresa Kantar Media, la medición de audiencias por audímetro se realiza mediante el audio, dado que es una información estandarizada para los diferentes países. De esta manera, las huellas digitales del sonido de los diferentes contenidos televisivos emitidos se comparan21 con los ya almacenados y que proceden de los diferentes canales de televisión. Con este proceso se logra identificar el consumo de televisión convencional.
Pero, más aún, actualmente también es fundamental comprender y contabilizar el consumo de contenidos digitales en otras plataformas distintas a la ventana del televisor. Hablamos de dispositivos como los smartphones, las tabletas o los ordenadores. Para ello, la recogida de datos se realiza desde un software instalado que simula estéticamente el uso del mando a distancia de los audímetros, de manera que la operativa es similar a la del manejo del audímetro tradicional. Con idea de cubrir la oferta televisiva existente, la recogida de datos también comprende actuales tendencias de consumo como el video on demand (VOD) o las grabaciones de contenidos en discos duros. Este último, usualmente, es un producto que ofrece un consumo prolongado en el tiempo, por ello hay contenidos que pueden permanecer almacenados en un disco duro desde un mes a un año, para luego desaparecer. En el caso de la empresa de análisis que explicamos, Kantar Media, ofrece un seguimiento de los datos de hasta veintiocho días después de su emisión en VOD o descarga en disco duro. Además, también cubrirían los consumos de canales temáticos a través de un registro de visionado. Si bien es cierto que no queda claro la aplicación de esta información, o el grado de conversión de registros en datos medibles y analizados. En general, podemos considerar que el ejercicio hecho hasta la fecha es básicamente cuantificable.
La huella digital de los usuarios en internet es medida por la empresa comScore, la cual ofrece amplios datos cuantitativos, además de perfiles sociodemográficos o datos sobre visitas cruzadas. Es interesante para los planificadores de medios, principalmente, en su tarea de decidir en qué soporte programar publicidad. La industria audiovisual encuentra en la herramienta Video Metrix un aliado de cara a conocer unos datos más fiables e integrales de la industria del vídeo.22 Por ejemplo, según informa comScore,23 su socio YouTube obtiene información cuantitativa: espectadores únicos, características sociodemográficas y determinadas actitudes respecto de los canales de YouTube.
En 2012, como fruto del uso cotidiano de internet, en España comenzó a valorarse una nueva métrica: el share24 social como contrapunto al share televisivo. Esta nueva medida estaba referida a aquellas métricas que consideraban otras formas de relacionarse con la industria televisiva, principalmente a través de las redes sociales. La empresa Global In Media se centró en reputación en línea, identidad digital y dinamización de comunidades. Por otro lado, la empresa Tuitele se centró en estudiar la audiencia social de la televisión, monitorizando en tiempo real la información presente en la red Twitter. Posteriormente, se dio un paso más en el análisis del share social a través del panel Tuitele Analytics con métricas y análisis con criterios de calidad destinados a las empresas que necesitaban conocer el valor cualitativo de la audiencia. Dos años después, en 2014, Kantar Media compró Data Republic, empresa propietaria de la plataforma de monitorización Tuitele, además de anunciar un acuerdo global con Twitter. Esta alianza empresarial, desde el punto de vista del big data, deja constancia del valor del share social para las marcas pero también para los productores de contenidos.
Kantar Twitter TV Ratings se establece, por tanto, como el primer servicio oficial de medición de Twitter a través de la herramienta Instar Social. La solución ofrece métricas como:
- • Los autores únicos: número de individuos únicos que tuitean sobre programas de televisión.
- • Audiencia única: cuánta gente ha leído los tuits.
- • Impresiones: número de veces que un tuit ha sido servido y, por lo tanto, ha sido visto.
- • Tuits y retuits, antes, durante y después de la emisión del contenido.
- • Media de tuits por minuto.
La gestión de datos procedentes de la medición de audiencia va encaminada a comprender sus posibilidades respecto de los diferentes medios y dispositivos en los que se generen, esto es, la audiencia crossmedia. Así, un año después del anuncio de colaboración estratégica entre Kantar Media y comScore, las empresas han manifestado públicamente su interés de comenzar en España, como país pionero, su nuevo modelo de medición denominado Cross Media Audience Meassurement25 que cruza datos procedentes de diferentes entornos, esto es, la denominada extended TV (consumo de contenidos audiovisuales más allá del televisor), el total video (contenidos televisivos y vídeo nativos digitales) y total view (incluyendo toda la navegación por internet).
El valor y la cantidad de información que podemos obtener a través de la interactuación de los espectadores con las redes sociales hacen conscientes a las cadenas de televisión y a los creadores de contenidos de la necesidad de facilitar esa vía de comunicación. Por ello, resulta habitual el visionado de programas con el hashtag impreso en la pantalla, a modo de mosca. Con este acto están reclamando la participación de un target concreto a través de redes sociales, especialmente se potencia el canal de Twitter gracias a la dinámica de su timeline. El objetivo es conectar con el denominado público social y que, a través de la segunda pantalla, interactúe. A partir de aquí, lo que el canal o productora haga con ese feedback dependerá de la visión de negocio que tenga la empresa. Para ello, en los próximos capítulos vamos a comprender, con un poco más de precisión, qué tipo de datos o información pueden demandar las empresas en función de las posteriores necesidades de negocio. Con este objetivo, vamos a entender las diferentes etapas técnicas y de negocio que cubre una acción con big data y business intelligence.
3.3. Canales y estrategias de obtención de datos
Identificada la problemática empresarial y el objetivo estratégico de todo negocio, la elección de herramientas y fuentes de las que obtener datos es fundamental. Desde las posibilidades que ofrece la red, sumadas a las acciones de marketing y promoción, identificamos que los productos audiovisuales pueden generar estrategias de obtención de datos a través de los diversos canales de comunicación. Entre ellos, destacamos como principales:
- • Página web o site de la empresa, producto o contenido específico
- • Redes sociales
- • Aplicaciones
Como marca o empresa, el hecho de tener una presencia en la red se ha convertido en algo tan importante como tener presencia física. La web permite no ya solo mantener actualizada la información que se quiere generar, tanto desde el punto de vista corporativo como de contenido, sino lograr un feedback con el espectador audiovisual. Y esta es, precisamente, la mejor manera de proceder a la generación de datos que, de otra manera, sería imposible. Desde hace unos años, en el propio desarrollo del site (web) se impone el criterio de responsive web design, término que hace referencia a la capacidad de la página web de tener un diseño adaptable a cualquier dispositivo. Esto supone que cualquier usuario pueda acceder a la información independientemente del dispositivo desde el cual se conecte. De hecho, tal es su importancia que, en abril de 2015, la compañía Google lanzó un comunicado desde su blog26 en el que manifestaba su intención de penalizar a aquellas webs que no fueran responsive; esto se podía traducir en una pérdida de posicionamiento en el famoso buscador, disminuyendo, por lo tanto, la tasa de tráfico orgánico.
De cara a tener una foto global del acceso de los usuarios a las plataformas de consumo en línea y comprender así la generación de datos, vamos a identificar acciones claves que realizan tanto las empresas como los usuarios. Como hemos mencionado, las empresas tienden a ofrecer sus contenidos digitales a través de la web site, consumible tanto desde el ordenador como desde el móvil, a través de un diseño dirigido al dispositivo móvil y a través de la aplicación. Cada uno de estos accesos a los contenidos puede sugerir una tipología de un usuario más o menos dispuesto a interactuar y facilitar datos y opiniones. Quizás el caso más efectivo sería la propia aplicación dado que solo el hecho de proceder a descargarla supone una acción proactiva por parte del usuario/espectador. Con respecto a la web, es ya habitual la política de cookies, por la cual el usuario de una web acepta que la empresa pueda conocer sus hábitos de navegación pudiendo así crear perfiles de usuarios que, si bien son anónimos, sí que ofrecen datos de actividad suficientemente interesante como para plantearse estrategias. Por ejemplo, en el caso de la analítica de marketing, una aplicación habitual del uso de los datos procedentes de las cookies es el real time bidding (RTB), una tendencia que logra su auge precisamente gracias a la gestión de los datos masivos y que consiste en ubicar publicidad en la web en tiempo real (frente a la compra prefijada de espacios); de esta manera, el conocimiento de perfiles permite ofrecer anuncios a usuarios y soportes concretos. Empresas como Google, Facebook o Amazon ya disponen de sus propias plataformas de RTB. Son nuevos modelos englobados en la gestión de datos masivos, concretamente en el data driven marketing, los que permiten gestionar también nuevas maneras de lograr retornos (usualmente conocido como return of investment, ROI). Pongamos, por ejemplo, en el caso de que los precios de fijar las tarifas publicitarias sea por pujas.
Otras empresas encuentran en la propia web su principal fuente de datos. Este es el caso de la empresa de comunicación Unidad Editorial y su cabecera Marca. En este periódico, el descenso de consumo de periódicos en papel supuso establecer una línea estratégica basada en el tráfico generado en su web marca.com y su posterior línea de negocio videos.marca.com. De esta manera, las redes sociales como fuente de datos están integradas en el propio site por cada noticia que se comparte. Con todo, marca.com, desde una perspectiva analítica, puede lograr datos para su posterior gestión procedentes del customer relationship management (CRM, herramienta de negocio orientada al cliente), Orbyt (herramienta de suscripción para consumo de contenidos propios de Unidad Editorial), el propio call center o herramientas de análisis web como Adobe Analytics.27
Las fuentes de datos de las que se va a obtener información cualitativa son aquellas webs o redes sociales donde el espectador puede ejercer algún tipo de actividad que aporte información, no ya solo sus datos personales o perfiles, algo que se entiende implícito, sino sus opiniones y valoraciones. Esto es el ya mencionado espectador social, un consumidor activo que demanda contenidos audiovisuales y que está dispuesto a opinar, criticar, alabar, puntuar o, simplemente, generar debate. Por ello, actualmente las acciones más idóneas para generar big data son las realizadas con perfiles en las redes Twitter, Facebook, la propia web de la cadena o programa, aplicaciones, blogs y, en menor proporción, Pinterest e Instagram, Telegram y WhatsApp, Snapchat o Periscope.
De todas las redes sociales indicadas, que en mayor o menor medida permiten interactuación por parte del espectador social, podemos considerar que hoy en día, gracias a la velocidad del timeline y sus características intrínsecas, es Twitter la principal ventana de participación del espectador social. La inclusión de etiquetas que permite una posterior agrupación de comentarios, así como las referencias a los programas concretos mediante el uso de hashtags, que podemos identificar impresos en la misma pantalla del televisor, sumado a la referencia directa y llamada a la atención a cualquier otro usuario de Twitter, han convertido a dicha red social en la segunda pantalla por excelencia. De hecho, como ellos mismos concluyen a través de un estudio propio,28 el uso de hashtags por parte de las cadenas de televisión tiene también un propósito que coincide con identificar a un share social joven proclive a tuitear y, por lo tanto, un target con tendencia a consumir y usar determinados productos tales como los mismos dispositivos móviles que usa a la hora de interactuar socialmente.
Por otro lado, la red social Facebook permite una comunicación diferente en el sentido de que las opiniones e impresiones quedan fijas y visibles en el timelime, no es efímera y además permite la interactuación con otros usuarios o consumidores del programa o cadena. En el caso de redes sociales como Telegram o WhatsApp, el usuario debe aún ser más proactivo, no ya solo opinar sino contactar a través de un mensaje al número de teléfono que se le ha facilitado; a partir de entonces ya forma parte de la base de datos. De otra manera, los mensajes que se intercambian por estas redes son privados sin posible acceso público.
Las aplicaciones que el usuario puede descargarse desempeñan un papel muy importante dado que, desde su origen, son diseñadas para consumirse en determinados dispositivos asociados a sistemas operativos, abriendo aquí una vía de negocio. También hay que tener en cuenta el hecho de que las productoras de contenidos audiovisuales, conscientes de las posibilidades que la tecnología ofrece y con idea de traspasar la pantalla de televisión, comienzan a generar contenidos transmedia y crossmedia o acciones de gamificación que suponen, en la mayoría de los casos, interactuar con sus propios datos. Según indica Neira,29 las aplicaciones de «segunda pantalla» vinculadas a la cadena, contenidos o programas concretos, permiten monitorizar la actividad en un entorno controlado, convirtiéndose en una herramienta de big data. Por ejemplo, el uso de dichas aplicaciones supone el registro del usuario con la consiguiente entrega de datos personales. O, también, el check-in dado que informa de que el espectador social está viendo el programa y lo hace a través de la publicación en todas las redes sociales asociadas. En este caso, el usuario de la aplicación está contribuyendo al big data con sus hábitos de consumo y comportamiento.
3.4. Dispositivos que interactúan
con los espectadores
Siguiendo con el ejemplo de la audiencia y la televisión, en el caso de que un espectador quiera convertirse en social, vamos a identificar los diferentes dispositivos a través de los cuales puede consumir y manifestarse a propósito de un contenido. Básicamente, nos vamos a referir a los dispositivos que, por su usabilidad y movilidad, son aptos para poder interactuar con ellos a la par que se consume televisión convencional, esto en el caso de pretender extraer datos en línea de manera simultánea a la emisión. Los dispositivos más útiles para lograr la interactuación de los espectadores con los creadores de contenidos son:
- • Ordenadores portátiles
- • Tabletas
- • Teléfonos inteligentes
Para un consumo desde el ordenador como dispositivo, el propio sector audiovisual realiza acciones que generan datos susceptibles de ser recogidos, almacenados y analizados fuera del horario de emisión. Esta información proviene de los blogs, páginas webs o encuestas. Son registros que se sumarían a la proveniente de los audímetros. Pero la dinámica de la audiencia social o la participación en acciones de marketing audiovisual implica en ocasiones la movilidad del espectador, la inmediatez en sus opiniones o la capacidad de fotografiar lo que está viendo. En estos casos, la necesidad de la inmediatez se traduce en el uso de dispositivos que se desplacen con el espectador, esto es, la tableta o el smartphone. Con respecto a la generación de big data, estos dispositivos cumplen una función muy importante, dado que casi para poder usar la totalidad de las marcas que se comercializan es necesario vincularlo a una cuenta de correo electrónico, por lo tanto a un perfil de usuario. Esto, sumado a la información que el propio usuario quiera manifestar a través del canal elegido para ser social: la aplicación del programa televisivo, el site de la productora o su propio perfil en redes sociales.
En general, la aparición de redes sociales de fácil manejo para los usuarios y, además, la utilidad y la motivación por compartir información, han hecho el resto. En el sector audiovisual actual, podemos encontrarnos principalmente con empresas privadas que quieren generar más beneficios a través del uso de estas nuevas herramientas tecnológicas; son los principales grupos mediáticos como Mediaset, Atresmedia o Movistar+, empresas que esperan un ROI medible de sus inversiones en acciones digitales en redes sociales o en áreas del big data. Pero también es interesante entender el posicionamiento de empresas públicas como RTVE que, lejos de buscar un retorno económico de sus acciones, tratan de mejorar como empresa ofreciendo unos contenidos más adecuados a su audiencia, entendiendo que el conocimiento de su audiencia es una oportunidad de mejora.
Sea cual sea el objetivo que se haya planteado la empresa con respecto al ROI: social, económico o, incluso, ecológico, es fundamental contar con el apoyo del big data, dado que nos va a ofrecer nuevas pistas y lógicas para interactuar con las nuevas tecnologías.
Por ello, en el caso de la industria audiovisual, la pretensión es lograr un mayor número de audiencia y espectadores sociales, dado que esta es una buena manera de lograr datos sobre usuarios, perfiles u opiniones. Y así, esta audiencia será susceptible de ser integrada en el proceso denominado big data, porque así estaré definido en la estrategia de negocio.
4. Trabajando con los datos
4.1. Analítica web
Una vez identificados los diferentes canales o dispositivos por los que el espectador se comunica con la cadena, productora o creadores de contenidos, comprendemos las variadas acciones que puede acometer. Y también que, por cada una de estas acciones, se genera información que queda plasmada en una gran cantidad de datos que tienen que organizarse y almacenarse para poder trabajar posteriormente con ellos, lo que ya identificamos como el uso del big data. Como esta información es muy dispar y con muchas características, se procede a organizarla muchas veces a través del uso de palabras clave o etiquetas. De hecho, ya vimos que los mismos usuarios de Twitter etiquetan sus opiniones con el uso de los hashtags. Esta simple acción es tremendamente útil para clasificar la información, pero cuando hablamos de big data hablamos de cantidades tan ingentes de datos que muchos de los cuales no son útiles. Esto, técnicamente –ya lo comentamos también–, puede ser debido a que algunos datos no tienen valor o estén correlacionados, son erróneos, incompletos o duplicados. En general, podemos decir que son datos no válidos. Pero ahora, situándonos en el entorno empresarial y no técnico, desde la toma de decisiones del negocio que ha decidido obtener los datos, también puede ser información no útil. Dicho de otra manera: no aporta nada a la operativa empresarial. Esto se debe a que la toma de datos debe responder a una necesidad de negocio con la idea de tomar decisiones a partir de ellos. Por lo tanto, es interesante reducir la dimensión de los datos con la idea de que tengamos una menor cantidad de información, esto es, entendido como menos atributos. Desde el punto de vista técnico, esta gestión la desarrolla la ingeniería de características. Así, por ejemplo, uno de los objetivos de este trabajo previo con los datos sería la denominada normalización, para evitar la redundancia (repetición de información) en los datos y así poder identificar y evaluar cuáles son importantes y cuáles no. Esta será la información que será analizada y sobre la que se tomarán decisiones. De ahí la importancia del proceso.
Figura 5. Proceso técnico de extracción de datos, transformación y carga
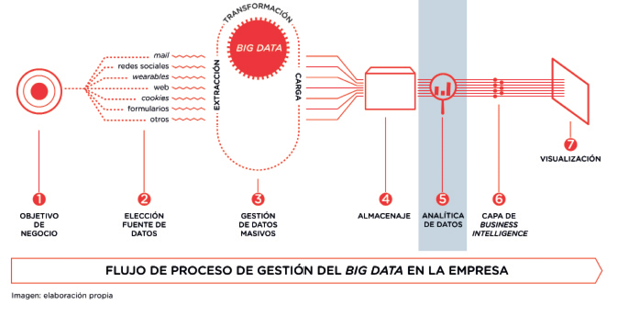
Por lo tanto, la mejor manera de analizar el impacto que tiene el trabajo con datos en las redes sociales o acciones big data es a través del análisis de la información que genera. Esta área de trabajo es la conocida como analítica de datos. Nos ofrece información con idea de convertirse en próximas estrategias a realizar, pero también nos puede hablar de aspectos económicos como el ROI y que veremos, con precisión, más adelante. Implementar un área de analítica de datos supone tomar unas decisiones sobre qué tipo de información necesita la empresa y con qué propósito, esto son los objetivos de negocio. A partir de ellos se establecerán una serie de métricas y de indicadores de rendimiento, y serán la base de trabajo de la analítica.
Las métricas: si algo va a permitir tener datos, es la posibilidad de contrastar cifras. De esta manera podremos medir y, por lo tanto, saber si como negocio hemos mejorado o empeorado. Por lo tanto, las métricas son valores cuantificables y personalizados para cada objetivo de negocio. En el caso de tratar con áreas concretas como puede ser la analítica del site o web, las métricas habituales son el número de usuarios únicos, visitas y páginas vistas. Para los medios televisivos y su monitorización con las redes sociales, las métricas interesantes son el número de interacciones o menciones. En general, estas medidas pueden aplicarse a muchas áreas: rentabilidad, cliente, acciones, productos, etc. Una de las métricas más interesantes de medir es el nivel de engagement, entendido como métrica cualitativa, que ofrece información sobre el grado de proactividad del usuario o espectador. Sea como sea, las métricas deben ir en concordancia con el negocio y con su tamaño. Avinash Kaushik, uno de los más reputados analistas web, propone establecer tres tipos de mediciones: métricas de adquisición, comportamiento y resultados.30 Así, estas serían las tres acciones que cubrirían las decisiones de negocio, experiencia de usuario y rentabilidad.
Biométricas: son técnicas matemáticas y estadísticas para identificar individuos únicos. Con el uso de los wearables31 ha surgido un abanico de posibilidades relacionadas con diferentes industrias. Una primera lectura nos remitiría a industrias como la médica o la seguridad, donde el control de los biorritmos es fundamental. Pensemos en creaciones como las pulseras/relojes inteligentes o sensores creados específicamente para deportistas. En el caso de la industria que referenciamos, la audiovisual, también ha sido capaz de integrar las biométricas; un ejemplo es el caso de algunos realities donde los concursantes portaban sensores que monitorizaban horas de sueño, distancias recorridas, calorías o pulsaciones.
KPI (key performance indicators o indicadores clave de rendimiento) están enfocados al objetivo final del negocio y suelen ir establecidos en porcentaje. Los datos ya analizados, interpretados y relacionados se convierten en los indicadores de negocio, permitiendo así tomar decisiones válidas de mejora (Macía Domene, (2013). Básicamente, esto nos va a ofrecer información respecto al estado de una actividad. Para que realmente sea útil debe cumplir tres características: ser cuantificable, inequívoco y realizable. Suelen ser muy pocos los KPI que se miden y se asocian a unidades de negocio. Así, por ejemplo, enfocados a la analítica de redes sociales de empresas audiovisuales, una propuesta sería medir el tráfico, la actividad o la propia comunidad. Desde una decisión de negocio diferente, otros KPI pueden identificar el país de procedencia de la visita, el tiempo de la visita o el porcentaje de usuarios que realizan compra en una página web. En esta línea de entorno web, establecer unos adecuados KPI acordes con nuestra necesidad estratégica va a permitir implementar dos procesos de mejora del rendimiento:32
- • Interpretar datos estadísticos de tráfico en conceptos y valores entendibles por los diferentes perfiles profesionales.
- • En función del progreso de los datos obtenidos, valorar el cumplimiento de los objetivos y poder tomar decisiones lo más certeras posibles.
Al denominado padre de la publicidad moderna, John Wanamaker, se le adjudica la siguiente frase: «La mitad del dinero que invierto en publicidad se desperdicia, el problema es que no sé qué mitad es». Este vacío de datos es precisamente lo que suple la analítica de datos: saber exactamente qué y cuánto no funciona. En general, tanto las métricas como los KPI tienen como objetivo aprender, corregir y mejorar. Ahora, con la obtención de los datos mencionados, es interesante dar un paso más y aplicar lógicas propias del big data. Por ejemplo, si pensamos en la minería de datos, los patrones de conducta extraídos de la analítica ofrecen información vital para la posterior toma de decisiones. Así, podríamos predecir comportamientos en función de la información que obtenemos de las cookies y que analiza la herramienta.
De manera general, podemos concluir que la mayoría de las empresas audiovisuales que realizan o empiezan a plantearse acciones de big data usan motores de analítica tanto freemium, gratuitas, como premium, de pago. Según la modalidad económica, el acceso a la información se realiza desde un punto de vista cuantitativo, pero también de manera cualitativa con respecto a las herramientas que permite manejar y las métricas que permite emplear. Básicamente, la idea de invertir en uno u otro software de análisis debería ir relacionada con la estrategia aplicada, es decir, con los objetivos con los que se aplica la tecnología a los datos. Pero también con el volumen de datos que se maneja.
Algunas herramientas que están empleando actualmente las empresas audiovisuales son:
Google Analytics,33 perteneciente a Google, ofrece servicios de embudo multicanal que indican el funcionamiento del marketing en los diversos canales que puede tener la empresa o negocio, así como el impacto y grado de conversión. En la línea de las redes sociales, permite también obtener informes sociales en los que se muestra tanto las métricas como el valor monetario de las conversiones, identificar comunidades importantes para la marca, así como el flujo de actividad de los botones sociales, entre otros. También resulta interesante diferenciar y medir el impacto de las campañas de marketing por uso de dispositivo ya que es habitual que, como usuarios, realicemos mismas búsquedas a través de diferentes canales.
Un vistazo a la web de Google Analytics nos puede mostrar el grado de impacto de una campaña en soporte web. De tal manera, a través de la herramienta es posible conocer el número de visitantes activos que tiene el site cada grupo de minutos o incluso segundos. En el caso de esta analítica, una visita tiene una duración de 30 minutos, un tiempo en el que el usuario o visitante activo interactúa con las diferentes acciones que puede realizar dentro de una misma página web: interacción social, transacciones de comercio, etc. Cada una de estas acciones supone volver a activar ese tiempo fijado de 30 minutos. Por el contrario, si el visitante se mantiene inactivo por un tiempo de 30 minutos la cookie _utmb se eliminará de su ordenador y se contabilizará una nueva visita.
Podemos, por tanto, ver que la herramienta ofrece analítica pero también nociones de inteligencia, por ejemplo a través de su analytics intelligence que, gracias a algoritmos, logra identificar alteraciones en patrones de conducta de usuarios.
Adobe Analytics es un conjunto de herramientas de análisis de web y marketing. Engloba a SiteCatalyst, herramienta centrada en comercio electrónico. Ofrece analítica y reporting alertas de acción, informes personalizados, perfiles sociales. Esta herramienta es mayormente empleada por empresas de gran tamaño, es decir, empresas que gestionan grandes volúmenes de datos. Tal y como informa Adobe, entre sus principales acciones destaca:
- • Analítica sobre aplicaciones móviles.
- • Segmentación avanzada de usuarios.
- • Marketing predictivo, intelligence marketing.
- • Analítica de aplicaciones móviles.
Posiblemente, una de sus principales ventajas sea la analítica en tiempo real, lo que va a permitir tomar decisiones en menor tiempo, así como la ya mencionada capacidad de gestionar grandes volúmenes de datos.
IBM Watson Analytics,34 servicio de analítica de grandes volúmenes de datos, basado en el sistema informática de Inteligencia Artificial Watson. Merece la pena conocer con perspectiva el origen de esta herramienta para valorar las posibilidades futuras. En un principio, la herramienta Watson responde a la denominada tecnología cognitiva y está diseñada, como indicábamos, por IBM. La base de trabajo parte de la idea de que las computadoras sean capaces de interpretar el lenguaje natural, el hablado por las personas. Watson aparece en el mercado con recorrido hecho; así, uno de sus méritos asociado al sistema cognitivo con lenguaje programado es la participación televisiva en 2011, en el programa norteamericano de preguntas y respuesta Jeopardy!, en el cual la máquina con inteligencia ganó a los dos concursantes con mayor número de aciertos hasta la fecha. Desde entonces, Watson ha mejorado en velocidad de reacción y está vinculado en múltiples industrias y escenarios como la ciencia médica, procesos I+D+I, educación o incluso gastronomía. Obviamente, también desarrolla su línea de negocio en el ámbito del big data y sus posibilidades relacionadas con industrias de la comunicación. Un buen ejemplo lo encontramos en Audiense, partner oficial de Twitter destinado al social marketing. Esta empresa, ha comenzado a incluir los denominados insights de personalidad empleando para ello la API de IBM. Hasta la fecha, la tecnología asociada al big data permitía lograr la segmentación de perfiles con respecto a datos sociodemográficos, hábitos o patrones. En el caso de los insigths, estos hacen referencia a rasgos de personalidad adjudicados a la audiencia de un producto o marca. Esto permite una catalogación por personalidades o, dicho de otro modo, una segmentación por personalidades, logrando así un impacto muy alto en la creación de estrategias de marketing.
Watson, como herramienta analítica, accede tanto a la información que se le facilite en datasets como a un histórico de dos años de la red social Twitter y al que realiza consultas a través de hashtags. De esta manera, crea análisis estadísticos y predictivos a través de lenguaje natural, además de poder visualizar los datos posteriormente. Como herramienta de analítica de datos, ofrece información en tiempo real además de analítica de contenido. Posibilidades de tratamiento de los datos y herramientas en la nube, análisis predictivo o visualización a través de una interfaz muy sencilla son algunas de sus características junto con la capacidad de trabajar con grandes volúmenes de datos. Pero, quizás, su principal rasgo sea el que explicaba el origen de Watson, el lenguaje natural, dado que las consultas a la herramienta se hacen de esa manera: preguntando a la máquina como si fuera una persona.
Podemos concluir, por tanto, que la analítica de datos va encaminada a extraer información valiosa sobre los usuarios y su comportamiento. Datos que hasta hace apenas unos años era imposible obtener. Como afirma Macía Domene, se tiende a la «integración de todos los datos, tanto online como offline, además del sentimiento del usuario a través de distintas plataformas, navegadores, dispositivos de navegación […] Solo así estaremos en disposición de comprender de forma más global el comportamiento del usuario y la forma en la que las distintas estrategias de promoción influyen sobre sus decisiones de compra».35
4.2. Descubriendo valor en los datos
Hablar de sistematizar el proceso de identificar el valor en los datos es remitirnos a un marco global denominado «proceso de extracción del conocimiento» o, más comúnmente llamado por su terminología en inglés, knowledge discovery in databases (KDD),36 en el que se incluyen acciones como la minería de datos, análisis o aprendizaje automático. El objetivo de este proceso es encontrar valor en los datos que se analizan y, para ello, se realiza un proceso iterativo con grandes volúmenes de datos, el big data, con idea de encontrar un modelo válido (por ejemplo, identificación de un algoritmo útil para detectar la información que queremos) o una conclusión (en el caso de analizar los datos desde la estrategia de negocio). Estas disciplinas relacionadas con el KDD están orientadas al negocio, con objetivos específicos, lo que va a suponer que tendrá que realizarse una preparación nueva de los datos, acorde con la información que queremos descubrir dado que, por ejemplo, en minería, son cuestiones concretas y no tanto generales. Por tanto, dentro del proceso de KDD se preparan los datos, se transforman y cargan para, a partir de aquí, trabajar en entornos de minería de datos para la creación de patrones, visualización e interpretación.
Una vez identificada la problemática de negocio que se quiere resolver o la estrategia que se quiere aplicar, y después de haber preparado los datos, comenzaría un trabajo denominado aprendizaje automático (machine learning). Esto sucede dentro del proceso denominado minería de datos,37 la cual es una disciplina propia de la inteligencia artificial que emula al pensamiento humano. La idea es que las máquinas aprendan determinadas respuestas automáticas ante ciertos escenarios. Para ello se van a entrenar los datos y desarrollar modelos utilizando el algoritmo que ofrezca las mejores prestaciones. Por concretar, el aprendizaje automático partiría de una gran base de datos a partir de la cual se entrenan distintos algoritmos con idea de elaborar un modelo tanto en función de los mismos datos como del negocio. Para ello, se trabaja con modelos paramétricos basados en ecuaciones matemáticas (regresión múltiple, clasificación) o incluso modelos probabilísticos como las redes bayesianas para poder ser capaces de predecir comportamientos o acciones a partir de datos completos o incompletos. Estos modelos se evalúan para confirmar su validez y, en caso de ser idóneos, se aplican a las lógicas de negocio.
El aprendizaje automático va a permitir, desde el punto de vista del negocio:
- • Crear predicciones, fundamentalmente las relativas a qué actuaciones van a hacer los clientes. Es decir, va a permitir tomar acciones sobre clientes.
- • Búsqueda de patrones interesantes.
- • Generación de grupos en los datos para, por ejemplo, segmentar y hacer campañas a medida de nichos. Esta acción es muy útil para el marketing ya que, por ejemplo, de esta segmentación podremos establecer patrones de consumo.
Dependiendo de cómo tengamos de preparada la información en cuanto a las etiquetas que acompañan a los datos, tendremos información previa que puede ser útil para el futuro. De ahí que se generen dos tipos de aprendizaje: el aprendizaje supervisado y el no supervisado. En el caso del primero, hablamos de trabajar con preguntas conocidas y respuestas también conocidas. De manera que, ante un nuevo cliente de la empresa, el modelo ya entrenado podrá deducir lo que va a pasar; son las predicciones. En este tipo de aprendizaje englobaríamos los algoritmos de clasificación, según los cuales, ante la llegada del mencionado cliente (dato + etiqueta), el modelo nos diría con qué grupo se posicionaría frente al resto. Por ejemplo, en el caso de consumidores de productos audiovisuales, identificar al usuario nos va a permitir aplicar aprendizaje supervisado y poder así predecir qué tipo de contenido va a querer consumir. Estamos, pues, segmentando al cliente y prediciendo.
Por otro lado, el aprendizaje no supervisado no trabaja con etiquetas, sino con datos sin categorizar sobre los que buscará patrones o grupos. Es habitual que el proceso comience con aprendizaje no supervisado para, posteriormente, trabajar con el supervisado. Estás técnicas de descubrimiento de valor en los datos son muy empleadas en ámbitos como la analítica de marketing al permitir establecer patrones y segmentar. De hecho, esa es precisamente una de las grandes bondades del trabajo con los datos, encontrar perfiles que permitan segmentar y hacer contenidos a medida, esto a través de la automatización de mecánicas y con empleo de algoritmos entrenados. En este sentido, los modelos next best activity suponen la aplicación de los modelos predictivos38 al marketing. Es la industria de la banca donde más efectividad ha logrado esta operación al poder prevenir la probabilidad de abandono de un cliente o de cometer fraude, pero en marketing también encuentra un escenario de trabajo interesante al identificar la siguiente acción del usuario. Son muchas las empresas que establecen el aprendizaje automático como base de sus acciones. Por ejemplo, Amazon emplea su propio Amazon Machine Learning con el objetivo de crear con facilidad aplicaciones predictivas, como la ya mencionada detección del fraude, la previsión de la demanda o la predicción de clics.39
4.2.1. Monetizar los datos segmentando perfiles
Con respecto a las posibilidades de segmentación del aprendizaje automático, en el caso de la empresa Twitter, precisamente aquí encuentra una vía de monetización a través del impacto cualitativo que ofrece a las marcas vía su timeline. La gestión de la gran base de datos de perfiles de Twitter, a través de algoritmos, logra identificar y segmentar clientes no tanto en cuanto a características sociodemográficas sino a gustos y acciones. Esto, asociado a otras líneas de negocio como los vídeos de Vine o Periscope, convierten a Twitter en un espacio de interés para las marcas.
Trabajar con datos permite definir qué valor podemos extraer de los mismos. En este sentido, uno de los casos más interesantes puede ser trabajar con el concepto de «recomendaciones». Estas se basan en las opiniones de los diferentes usuarios, bien a partir de la comunicación orgánica con sus opiniones trasladadas a los espacios webs y a la vista de futuros usuarios de los mismos productos, o bien a través de las puntuaciones en rankings.
Diferentes sectores se han posicionado ante los clientes a través de las recomendaciones, pero quizás sea la compañía de video on demand Netflix la que ha sabido dar un paso más al generar un nuevo valor en las recomendaciones. Para ello, creó una unidad de negocio destinada a la producción propia. Juntando el big data y la estadística, dieron forma al «círculo de éxito probado».40 Esto era diseñar el producto que más éxito podría tener a partir de las conductas de sus espectadores que identificaban las preferencias por el actor Kevin Spacey, el estilo del director David Fincher o series de éxito y género exitoso como la contrastada House of Cards. Otro aspecto importante a medir en la conducta de los usuarios de Netflix es el comportamiento, una vez que el contenido es pausado, y así identificar si posterior a la parada el contenido sigue siendo visualizado o, de lo contrario, eliminado, es un dato fundamental de cara a posteriores predicciones. Sumado a estas acciones, la página de Netflix ofrece la posibilidad de indicar las preferencias de gusto y perfiles junto a las recomendaciones.41 Para ello, Netflix trabaja con un algoritmo que valora, para las recomendaciones, aspectos como los géneros de las películas y series, el historial de transmisión y recomendaciones previas y las calificaciones del resto de usuarios de la plataforma con gustos similares. Estas recomendaciones ofrecen una horquilla de puntuación de 1 a 5. En el caso de las preferencias, son encuestas que se establecen en las categorías argumento, subgénero, cultura y especial interés, así como su temporalidad de consumo: a menudo, a veces o nunca.
4.3. Business Intelligence
Como venimos diciendo, los datos en sí mismos no aportan valor, es el conocimiento que se extraiga de ellos y las decisiones que de ahí se tomen lo que va a dar utilidad y valor al dato. Esto es precisamente lo que hace el business intelligence: partiendo de información basada en datos, procede a tomar la mejor de las decisiones. Para ello, ya hemos visto que los datos han sido extraídos de diferentes fuentes, se han limpiado y transformado manteniéndose guardados para su posterior aplicación de métricas, visualización y analíticas.
Howard Dresner, investigador y analista durante años de la consultora Gartner, comprendía el business intelligence como aquel «paraguas que engloba conceptos y métodos que ayudan a tomar la mejor decisión de negocios basada en hechos». Por ello, y conociendo ya todas las posibilidades que ofrece el big data, cuando hablamos de business intelligence, tenemos que pensar que sus acciones estratégicas comienzan desde el origen del proceso, desde la elección de las fuentes de las que se desean obtener datos. Esto sería la denominada capa de negocio, y variará dependiendo de los objetivos de cada empresa.
Figura 6. Flujo de procesos en un entorno big data
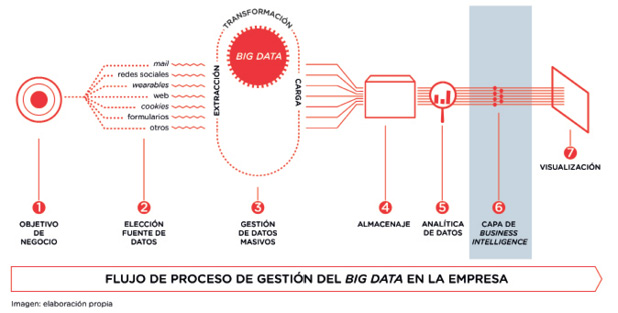
En este nivel, es interesante comprender aspectos puramente de negocios como las métricas, el ROI o el beneficio por cliente. Desglosemos estos conceptos. El ROI, por tanto, justifica la inversión de acciones como el marketing o la propia tecnología big data. En ocasiones, algunos directivos de cadenas no han podido concretar cómo se monetiza la inversión en tecnología con los datos. Pero es fundamental identificar la procedencia del retorno; así pues, muchos de los modelos de negocio de contenidos digitales que existen en la actualidad pueden disponer de tráfico procedente de la página web, que a su vez puede ser consumida a través del ordenador o del móvil o tableta, además de la aplicación. Todos estos consumos por plataforma ofrecen un retorno diferente que define también tanto al usuario como al contenido en sí. Como caso concreto en la industria audiovisual, el ROI referente a las plataformas de pago va enfocado a que el coste de retención de un cliente sea menor al coste de adquisición.
Todas estas acciones están englobadas dentro de la estrategia diseñada acorde con el modelo de negocio. En el caso de las cadenas televisivas privadas pertenecientes al grupo Atresmedia o Mediaset, el modelo de televisión está basado principalmente en la publicidad; en el caso de las cadenas de pago como Movistar + o TotalChannel, el modelo de negocio es por suscripción, mientras que en el caso de la cadena pública TVE, que se nutre de los presupuestos del estado, el concepto de rentabilidad es complejo al incluir el valor social. Estos son tres modelos de gestión televisiva que conviven, y cada uno de ellos establecerá unas métricas diferentes, así como unos KPI también a medida de su modelo de negocio.
A continuación, un entorno de trabajo business intelligence dispone de una capa de soporte a la decisión, que hace referencia al conjunto de actividades que dan soporte al negocio, sin incluir comunicación con el cliente. Estamos hablando del soporte técnico, por ejemplo, la elección de fuentes sobre las que se van a generar los datos masivos, el ya mencionado proceso de ETL (extracción, transformación y carga), generación de plataformas, aplicaciones, ERP, extracción de datos, gestión de plataformas, etc. A partir de aquí, el siguiente paso es el entendimiento de los datos, tanto para perfiles técnicos como para aquellos que van a tomar decisiones de negocio.
4.4. Visualización
Comprendiendo con perspectiva el proceso de la gestión de datos en su totalidad, podemos ya entender que las decisiones que motivan a las empresas a trabajar con big data y aplicar posteriormente análisis y business intelligence son decisiones estratégicas realizadas por perfiles directivos que no necesariamente tienen que tener formación técnica. De ahí que se contemple la generación de gráficos como una manera entendible de dar datos y ofrecer conclusiones. Atrás quedaron ya los densos reportes e informes, estos no eran útiles y la información era estática, era una radiografía concreta de un momento exacto.
Figura 7. Flujo de procesos en un entorno Big data
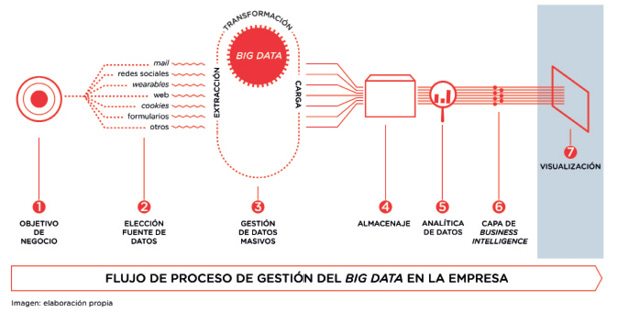
El área de la visualización de datos cobra más fuerza cada día dada su gran contribución al entendimiento de procesos técnicamente complejos. La idea que sustenta la necesidad de la visualización de datos en un entorno big data radica en la propuesta de que, cada vez más, los motores analíticos sean más fáciles de manejar, de manera que los datos sean numéricos, o convertibles en cifras, para que puedan aplicarse, sobre ellos, algoritmos ya creados y entrenados. La visualización de datos surge, entonces, con idea de no necesitar ser un matemático que interprete los datos. De hecho, esto es precisamente lo que ofrece la visualización de datos: hacer entendible, desde un punto de vista empresarial, unos datos trabajados en entornos de matemáticas y estadística.
Esta área de entendimiento de datos hace referencia a todas aquellas posibilidades gráficas de mostrar información y cruces de datos de una manera fácil. Los gráficos generados pueden ser de muchos tipos, diseñados prácticamente a demanda del negocio. Pueden tener, por tanto, entidad propia a través de herramientas personalizadoras de visualización de datos. También pueden estar incluidos en los cuadros de mando, también llamados scorecard, modelos comprensibles que muestran en tiempo real datos masivos y análisis. O, también, pueden incluir mapas de calor, diagramas de dispersión o incluso nubes de palabras que permitan la interactuación con el usuario. Fruto de este gran abanico de posibilidades y su velocidad de implantación, denotamos que las empresas tienden en su mayoría a contratar software de visualización en lugar de desarrollar sus propios entornos y herramientas de business intelligence y visualización. Las razones son varias: herramientas con las últimas actualizaciones, entornos personalizables, sin pérdida de tiempo en desarrollo ni contratación de personal para creación de entorno de business intelligence y visualización. Pero, sobre todo, la principal ventaja de contar con este tipo de plataformas deriva de no tener que contar con una alta estructura de costes, ahorrando dinero y tiempo.
En líneas generales, estas plataformas aplican una capa de inteligencia de negocio para lograr ofrecer claras y sencillas interpretaciones de los datos a partir de unas métricas personalizadas y definidas por el cliente. Estos softwares permiten interactuar en tiempo real con los diferentes datos disponibles y mostrarlos tanto de modo interno en la empresa como a cualquier usuario de internet, dependiendo ya de la estrategia de negocio.
Veamos, a continuación, las principales plataformas de visualización de datos, así como sus aplicaciones en el entorno del negocio.
- • La plataforma Qlikview trabaja con analítica de datos y business intelligence generando visualización a través de cuadros de mando. Entre sus clientes de la industria de los medios de comunicación, se encuentran el Grupo Godó o Fox Internacional Channels. Trabaja en la línea de herramientas de business discovery, una disciplina que frente al business intelligence tradicional, entiende al usuario como creador de contenido a través del acceso de todo el personal a los datos, no solo a las unidades de negocio competentes.
- • Analizando las plataformas de BI y visualización más demandadas en el sector audiovisual, destacamos Tableau, la cual ofrece análisis en la nube, análisis rápido y business intelligence.42
- • Microstrategy es, según la consultora Gartner, el proveedor líder mundial en software para empresas, posicionado ahora también en analítica, business intelligence y visualización. En lo referente al entorno audiovisual, es la plataforma empleada por Netflix para generación de dashboards.
- • Existen en el mercado otras muchas herramientas centradas más en la visualización y no ya tanto en la inteligencia de negocio. Merece una mención especial la startup española CartoDB: un servicio en la nube de visualización de datos en mapas con tecnología open source, SaaS (software as a service),43 aunque para muchos es conocido como el «Instagram de los mapas». En la actualidad trabajan con «Deep insights», una solución por la que cualquier empresa puede profundizar con tal detalle en su información que le permite extraer patrones y, por lo tanto, predicciones. Nuevamente, el uso del big data al servicio de la estrategia pero, en este caso, a través de la imagen.
En general, podemos decir que vivimos unos años de esplendor en la proliferación de software de visualización de datos y generación de infografías, herramientas freemiun y de pago, privadas y open source: Mapbox, ArcGis, Easel.ly, Infogr.am, Visual.ly, Tagxedo, etcétera. Al final, el objetivo es comprender más fácilmente los datos masivos de los que disponemos, para poder tomar las mejores decisiones estratégicas.
La visualización de datos, sumada al razonamiento analítico a partir de ellos, es la disciplina denominada visual analytics. La visualización en sí ayuda a ver los datos más claramente, entendiéndolos sin necesidad de tener perfiles técnicos. Pero es importante que estas visualizaciones cuenten con análisis estadístico, big data, análisis predictivo, ingeniería de datos, acceso a los mismos en tiempo real e incluso conocimientos de diseño a la hora de emplear colores y su correspondiente significado asociado a las culturas. Es decir, comprender que estas aportaciones gráficas tienen infinidad de posibilidades en entornos tecnológicos de datos, no resumiéndose a simples grafismos estáticos sin aporte, sino ofrecer nuevas maneras de contar las cosas. Los recursos presentados a lo largo de este capítulo encuentran un fuerte aliado en la creatividad y hace algunos años presenciábamos iniciativas que jugaban con datos, geolocalización y visualización en proyectos como The Wilderness Downtown44 (Chris Milk, 2010). Procedente de la participación en este proyecto, el creador Aaron Koblin trabaja fascinantes representaciones artísticas y audiovisuales a partir de nuevas tecnologías y datos generados. Son famosas, entre otras muchas, sus visualizaciones a partir del intercambio de datos generados a escala mundial gracias a las nuevas tecnologías.45
Como conclusión, las visualizaciones en entornos de trabajo tecnológicos nos ayudan a entender mejor el mundo y tomar decisiones más rápidas y mejores. Pero también nos ayudan a construir dimensiones nuevas dado que el sector audiovisual es una empresa artística y, como tal, debería poder aprovechar todos los recursos disponibles para contar sus proyectos al mundo.
Bibliografía
Danuloff, Craig (2011). Quality Score in High Resolution. Potato Creek Books.
Fundación Telefónica (2015). La sociedad de la información en España.
Geddes, Brad (2010). Advanced Google AdWords. Sybex.
Herbera, J.; Linares, R.; Neira, E. (2015). Marketing cinematográfico. Barcelona: Editorial UOC.
Han, J.; Kamber, M.; Peu, J. (2011). Data Mining. Concepts and Techniques (The Morgan Kaufmann Series in Data Management Systems). University of Illinois at Urbana-Champaign.
Jenkins, H. (2008). Convergence Culture: La cultura de la convergencia en los medios de comunicación. Paidós Ibérica.
Kaushik, Avinash (2010). Analítica Web 2.0: el arte de analizar resultados y la ciencia de centrarse en el cliente. Gestión 2000.
López M. (2009). SEO Posicionamiento en buscadores. Madrid: Bubok.
Macía Domene, F. (2013). Marketing Online 2.0. Cómo atraer y fidelizar clientes en Internet. Madrid: Anaya Multimedia.
Maciá Domene, F.; Gosende Grela, J. (2012). Técnicas avanzadas en posicionamiento en buscadores. Madrid: Anaya Multimedia.
Mayer-Schönberger, Viktor (2013). Big data, la revolución de los datos masivos. Madrid: Turner Publicaciones.
Neira, Elena (2015). La otra pantalla. Redes sociales, móviles y la nueva televisión. Barcelona: Editorial UOC.
Orense Fuentes, M. (2010). SEO Cómo triunfar en buscadores. Madrid: ESIC Editorial.
VV. AA. (2013). El libro del marketing interactivo y la publicidad digital. Madrid: ESIC.
VV. AA. (2015). Big Data, Beyond the Hype. McGraw Hill Education.
Bibliografía en línea:
Accenture. «Gestión de datos y arquitectura» [en línea].
<www.accenture.com/es-es/service-technology-data-management-architecture-summary.aspx>
Allen, Robert (2016). «What happens online in 60 seconds?» [en línea]. <http://www.smartinsights.com/internet-marketing-statistics/happens-online-60-seconds/>
BBVA (2015). «Data. Todo sobre el ecosistema big data» [en línea].
<http://www.centrodeinnovacionbbva.com/sites/default/files/ispring/innovation-trends/index.html>
BEEVA. «El rol del analista de negocio» [en línea].
<https://www.beeva.com/beeva-view/estrategia-negocio/el-rol-del-analista-de-negocio/>
Domo (2015). «What happens on the internet in one minute» [en línea].
<http://www.likeablesocialmedia.org/what-happens-on-the-internet-in-one-minute-infographic/>
Google. «Analítica web para empresas» [en línea].
<http://www.google.es/intl/es/analytics/>
IBM. «What is Watson Analytics?» [en línea].
<http://www.ibm.com/analytics/watson-analytics/>
IBM. «What is a data scientist?» [en línea].
<www-01.ibm.com/software/data/infosphere/data-scientist/>
The Cocktail-ARENA (2015). «Observatorio de redes, VII oleada» [en línea].
1 Se recomienda la lectura del blog de Netflix relativo a su división técnica en techblog.netflix.com donde, en función de los conocimientos más o menos técnicos del usuario, podemos obtener información interna del funcionamiento de la plataforma con respecto a temas como algoritmos, analítica, data visualización, data pipeline, arquitectura cloud, etc.
2 Orense Fuentes, M. (2010). SEO. Cómo triunfar en buscadores (págs. 23-24). Madrid: ESIC Editorial.
3 Unique resource location.
4 Término referido a la acción de usar etiquetas.
5 Orense Fuentes, M. (2010). SEO. Cómo triunfar en buscadores. Madrid: ESIC Editorial.
6 Domo (2015). «What happens on the internet in one minute» [en línea]. <http://www.likeablesocialmedia.org/what-happens-on-the-internet-in-one-minute-infographic/>Allen, Robert (2016). «What happens online in 60 seconds?» [en línea]. [Fecha de consulta: 10 de marzo de 2016]. <http://www.smartinsights.com/internet-marketing-statistics/happens-online-60-seconds/>
7 The Cocktail-ARENA (2015). «Observatorio de redes, VII oleada» [en línea]. [Fecha de consulta: 10 de marzo de 2016]. <http://www.slideshare.net/TCAnalysis/observatorio-redes-sociales-56195394?ref=http://tcanalysis.com/blog/archive/2015/12/>
8 Modelo de gestión de clientes, del inglés customer relationship management.
9 Disponible en http://www.dataversity.net/not-your-type-big-data-matchmaker-on-five-data-types-you-need-to-explore-today/ [Fecha de consulta: 10 de octubre de 2015].
10 Sistema tecnológico de posicionamiento en interiores.
11 Dispositivo tecnológico que pueden llevar las personas, ya sea sobre el cuerpo o sobre la ropa, etc.
12 Pequeño dispositivo que emite señales en un corto espacio físico vía bluetooth.
13 Accenture. «Gestión de datos y arquitectura» [en línea]. [Fecha de consulta: 15 de diciembre de 2015]. <www.accenture.com/es-es/service-technology-data-management-architecture-summary.aspx>
14 IBM. «What is a data scientist?» [en línea]. [Fecha de consulta: 10 de marzo de 2016]. <www-01.ibm.com/software/data/infosphere/data-scientist/>
15 BEEVA. «El rol del analista de negocio» [en línea]. [Fecha de consulta: 10 de marzo de 2016]. <https://www.beeva.com/beeva-view/estrategia-negocio/el-rol-del-analista-de-negocio/>
16 La consultora Gartner ofrece a sus clientes Predicts 2016: Information Stratey. Además, en el newsroom <http://www.gartner.com/newsroom/id/3190117> puede consultarse un extracto relativo al rol de CDO. Se recomienda, igualmente, la lectura de «First 100 days of a Chief Data Officer» (Primeros 100 días de un CDO) disponible en línea. [Fecha de consulta: 10 de marzo de 2016]. <http://www.gartner.com/smarterwithgartner/first-100-days-of-a-chief-data-officer/?cm_mmc=social-_-rm-_-gart-_-swg>
17 Traducción de la autora.
18 Neira, Elena (2015). La otra pantalla. Redes sociales, móviles y la nueva televisión. Barcelona: Editorial UOC.
19 Linares, Rafael (2015). «Marketing en el cine». En: J. Herbera; R. Linares; E. Neira. Marketing cinematográfico. Barcelona: Editorial UOC.
20 Medición de televisión y vídeo en plataformas y dispositivos [Fecha de consulta: 15 de diciembre de 2015] <http://www.kantarmedia1.es/sections/product/panel-audiencia>
21 Kantar Media. Medición de audiencias. [Fecha de consulta: 15 de diciembre de 2015]. <http://www.kantarmedia1.es/sections/audiences>
22 Análisis de audiencia. Video Metrix. [Fecha de consulta: 15 de octubre de 2015]. <http://www.comscore.com/esl/Productos/Audience-Analytics/Video-Metrix>
23 Información y métricas extraídas de <http://www.kantarmedia1.es/noticias/view/117>
24 Porcentaje de audiencia. Dato estadístico que identifica el número de espectadores de un programa contrastado con la cifra de población que tiene un televisor encendido que sintoniza dicho programa.
25 Extended TV y total video. La nueva medición crossmedia. Participación de comScore en el Seminario AEDEMO 2016. [Consulta: 1 de marzo de 2016]. Información disponible en: http://www.kantarmedia.com/uk/our-solutions/audience-measurement/cross-media/cross-media-audience-measurement-cmam-.
26 «Finding more mobile friendly search results» (Encuentra resultados de búsqueda por móvil de manera más amigable). [Consulta: 4 de enero de 2016]. <http://googlewebmastercentral.blogspot.com.es/2015/02/finding-more-mobile-friendly-search.html>
27 Anteriormente conocido como Adobe Omniture.
28 Información facilitada por Alfonso Calatrava, jefe de Investigación de Twitter España y colaborador de esta publicación.
29 Neira, op. cit.
30 Kaushik, Avinash. Digital Marketing and Measurement Model. [Fecha de consulta: 4 de enero de 2016]. <http://www.kaushik.net/avinash/digital-marketing-and-measurement-model/>
31 Dispositivos llevables en el cuerpo, tales como relojes o pulseras, capaces de acceder a información vital del ser humano y generar big data.
32 Maciá Domene, F.; Gosende Grela, J. (2012). Técnicas avanzadas en posicionamiento en buscadores. Madrid: Anaya Multimedia.
33 Google. «Analítica web para empresas» [en línea]. [Fecha de consulta: 10 de marzo de 2015]. <http://www.google.es/intl/es/analytics/>
34 IBM. «What is Watson Analytics?» [en línea]. [Fecha de consulta: 15 de octubre de 2015]. <http://www.ibm.com/analytics/watson-analytics/>
35 Macía Domene, F. (2013). Marketing Online 2.0. Cómo atraer y fidelizar clientes en Internet. Madrid: Anaya Multimedia.
36 Han, J.; Kamber, M.; Peu, J. (2011). Data Mining. Concepts and Techniques (The Morgan Kaufmann Series in Data Management Systems). University of Illinois at Urbana-Champaign.
37 Siguiendo el estándar de buenas prácticas Cross Industry Standard Process for Data Mining (CRISP-DM).
38 Esto es un algoritmo que, aplicado a una serie de datos, identifica la relación entre una variable y el resto de la información disponible.
39 Preguntas frecuentes sobre Amazon Machine Learning. [Fecha de consulta: 13 de octubre de 2015]. <https://aws.amazon.com/es/machine-learning/faqs/>
40 Término acuñado por The New York Times Company.
41 Calificaciones y recomendaciones de Netflix. [Fecha de consulta: 13 de octubre de 2015]. <https://help.netflix.com/es/node/9898>
42 Un ejemplo ilustrativo de uso de la visualización aplicada a contenidos audiovisuales lo encontramos en Trash-Talking while binge watching. Tableau ofreció la visualización de los datos generados por los usuarios de Twitter a propósito de la temporada 3 de la serie televisiva House of Cards de Netflix. El cuadro de visualización permitía seleccionar el capítulo concreto del que obtener información: una nube de tags, diferentes tuits y retuits, número de interacciones por minuto, etc. Visualización disponible en <http://public.tableau.com/profile/mwallace7569#!/vizhome/Trash-TalkingWhileBingeWatching/HouseofCardsTwitterAnalysis>. Esto ofrece datos muy valiosos sobe el grado de aceptación de la serie, los temas y personajes que más gustan a la audiencia social, así como los momentos que más emoción han suscitado. Una vez más, esto es una información muy útil desde un punto de vista estratégico.
43 En este tipo de servicios, el soporte lógico y los datos se encuentran en una empresa TIC y el cliente accede al servicio vía internet, no teniendo así que proceder al mantenimiento, operativa o soporte del software.
44 Proyecto interactivo llevado a cabo por Google y que integra contenidos como la música, los datos geolocalizados, la visualización de los mismos mostrados a través de Google Chrome, composición realtime y la tecnología HTML5, entre otros.
45 El proyecto New York Talk Exchance parte de los datos generados en tiempo real por los móviles y la red IP (protocolo de internet) y sus comunicaciones con el resto del mundo. Es un proyecto del Senseable City Lab del MIT para el MOMA. [Fecha de consulta: 4 de enero de 2016]. Visualización disponible en <http://www.aaronkoblin.com/project/new-york-talk-exchange/>