Capítulo I
La traducción asistida por ordenador
1. Introducción
La informática se ha introducido plenamente en todos los sectores productivos y actividades
profesionales. La traducción no es una excepción y desde hace ya años el proceso de
traducción se lleva a cabo casi siempre utilizando un ordenador. Muy a menudo el uso
del ordenador se limita a aplicaciones ofimáticas estándar, especialmente procesadores
de textos. Las consultas a fuentes de información habituales en la traducción (diccionarios
generales y terminológicos, enciclopedias, etc.) se hace ya también de forma generalizada
a través de un ordenador, ya sea mediante la consulta de recursos instalados en la
máquina o mediante la consulta a sitios webs específicos. El ordenador se ha convertido
también el medio principal de comunicación entre el traductor y sus clientes, especialmente
mediante el correo electrónico. Pero relevar al ordenador a ser un simple sustituto
de una máquina de escribir, un diccionario y un servicio de correos eficiente es menospreciar
sus enormes posibilidades.
Los programas de traducción asistida por ordenador engloban una serie de aplicaciones informáticas especialmente diseñadas para asistir
de manera eficiente al traductor durante su trabajo.
En un sentido amplio, los sistemas de traducción asistida engloban todas las aplicaciones
informáticas diseñadas para tareas específicas del proceso de traducción.
En un sentido más específico, generalmente se habla de sistemas de traducción asistida
cuando nos referimos a los programas que ayudan a traducir a partir de consultas a
una o varias memorias de traducción y, de manera opcional, a uno o más glosarios terminológicos.
Tanta importancia tiene el concepto de memoria de traducción que a menudo se ha denominado
a los sistemas de traducción asistida como memorias de traducción o bien sistemas de gestión de memorias de traducción.
Lippmann (1971) hacía una descripción pionera del concepto de traducción asistida
por ordenador:
«Computer-aided translation (CAT) is a storage and retrieval operation carried out
on line with a computer during the time in which a translation is produced. A system
of dictionary access and updating routines, text-processing facilities, and on-line
utilities is designed to telescope the delay between the initiation of a translation
and its finished print out. The system does not attempt to simulate the human translator
by producing an autonomous translation via programmed algorithms; rather, it serves
as an extension of the capabilities of the user, who is able to call on the resources
of the computer as needed in the process of translation and get an immediate response.
Under the system described, users communicate over ordinary telephone lines with the
computer by means of remote terminals. In employing the system, the user can switch
back and forth as many times as required among human translation, direct dictionary
look up, editing, printing, and system interrogation, and thereby achieve rapid interaction
toward the desired goal, a finished translation.»
Así, uno de los objetivos principales de un sistema de traducción asistida es poner
al alcance del traductor de manera automática y rápida todos los recursos que le puedan
resultar de utilidad. Para hacer su tarea un traductor habitualmente consulta diccionarios
generales, terminológicos y enciclopédicos. Estos diccionarios pueden estar en papel
y pueden constituir varios volúmenes. Esto hace que la consulta manual de estos recursos
pueda resultar muy costosa en términos de tiempo. Un recurso muy interesante, pero
a la vez difícil de gestionar de manera manual, son los ejemplos de traducciones anteriores,
ya sean realizadas por el mismo traductor como por otro profesional. A menudo, cuando
se traduce una determinada oración, se tiene la sensación de que ya haberla traducido
anteriormente. El hecho de disponer de un registro de traducciones accesible de manera
fácil y rápida puede suponer un ahorro de tiempo considerable. Los sistemas de traducción
asistida, como veremos más adelante, nos dan un acceso automático e inmediato a todos
estos recursos.
El proceso de traducción con un sistema de traducción asistida se divide de manera
genérica en los siguientes pasos:
-
Tratamiento de formato: el sistema de traducción asistida nos permitirá crear proyectos de traducción a
partir de archivos en diferentes formatos. De este modo, con una única herramienta
podemos traducir archivos en diferentes formatos sin la necesidad de disponer de un
gran conjunto de herramientas específicas.
-
Segmentación: la traducción del texto original se lleva a cabo en pequeñas unidades. Estas unidades
se denominan segmentos y, en general, se puede asimilar un segmento a una única oración (como veremos más
adelante, no siempre coincide un segmento con una oración). La finalidad de esta división
en segmentos o segmentación es básicamente la consulta a memorias de traducción. La probabilidad de encontrar
una unidad similar a la unidad que estamos traduciendo es inversamente proporcional
al tamaño de esta unidad. Por lo tanto, es más probable encontrar una oración similar
en la memoria que un párrafo entero.
-
Asignación de recursos: una vez creado el proyecto de traducción y con el fin de de sacar provecho de todas
las posibilidades de la herramienta de traducción asistida, es imprescindible asignarle
una serie de recursos, principalmente glosarios terminológicos y memorias de traducción.
-
Traducción: este paso se realiza también segmento a segmento y la herramienta muestra la información
relevante (coincidencias exactas y parciales en las memorias de traducción, entradas
de los glosarios presentes en el segmento a traducir, etc.) de una manera clara.
-
Creación de recursos a medida que se va traduciendo: durante la traducción de un proyecto es un buen momento para crear nuevos recursos.
Las memorias de traducción se crean de manera totalmente automática durante la traducción.
Mientras vamos traduciendo, podemos incluir nuevas entradas en los glosarios terminológicos.
De esta manera, nos ahorraremos nuevas consultas en el futuro.
-
Revisión dentro de la herramienta de traducción asistida: estas herramientas disponen de diferentes funciones para asegurar la calidad de
la traducción, desde correctores ortográficos y gramaticales hasta la comprobación
de etiquetas y marcas de formato. Es importante hacer una primera revisión del texto
dentro de la herramienta de traducción asistida antes de la creación de los documentos
finales.
-
Creación de los documentos traducidos: de igual manera que la herramienta es capaz de tratar varios formatos para introducirlos
en un proyecto de traducción, también es capaz de generar los documentos traducidos
en el mismo formato original y manteniendo en un buen grado la maquetación del archivo.
-
Revisión de los documentos traducidos en su formato original: es muy importante hacer una última revisión de la traducción una vez exportada a
su formato original.
2. Componentes básicos de un sistema de traducción asistida
2.1. Entorno de trabajo
Entendemos por entorno de trabajo de un sistema de traducción asistida su interfaz
gráfica. Uno de los aspectos más importantes del entorno de trabajo es la disposición
de la información en la pantalla. La mayoría de aspectos de esta disposición son personalizables,
pero se pueden distinguir algunos grupos generales. La primera distinción se puede
hacer entre:
1) Programas que disponen de una interfaz de trabajo propia. En este grupo podemos clasificar un gran número de herramientas de traducción asistida:
OmegaT, Virtaal, SDL, Déjà Vu, WordFast Professional, etc. En la figura 1 podemos observar la interfaz gráfica de Virtaal.
Figura 1.

Interfaz gráfica de la aplicación Virtaal
2) Programas que se integran en otro programa. Generalmente un procesador de textos, como Anaphraseus (figura 2), WordFast Classic y Trados WorkBench. El primero se halla en el paquete OpenOffice
y los otros dos, en la aplicación Microsoft Word.
Figura 2.
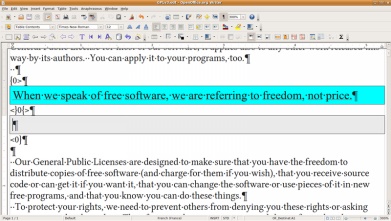
La aplicación Anaphraseus, integrada en OpenOffice
Dentro del primer grupo –es decir, de los programas que disponen de una interfaz propia–,
podemos distinguir diferentes subgrupos atendiendo a la disposición de los segmentos
originales y traducidos. Así, podemos encontrar los siguientes subgrupos:
a) Segmento traducido bajo el original. Tal como ocurre, por ejemplo, en OmegaT. Muy a menudo, en esta disposición, los
segmentos no activos solo se muestran en un idioma (generalmente el original si el
segmento no está traducido y la traducción en caso de haberse traducido). El segmento
que estamos traduciendo se muestra en las dos versiones. En la figura 3 podemos ver la interfaz de OmegaT:
Figura 3.
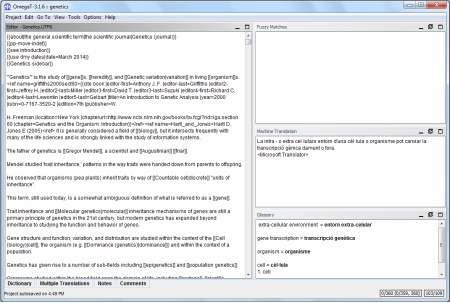
Interfaz de OmegaT
b) Disposición en dos columnas: donde generalmente la izquierda corresponde al original y la derecha, a la traducción.
En la figura 4 podemos ver la interfaz de Déjà Vu X2:
Figura 4.
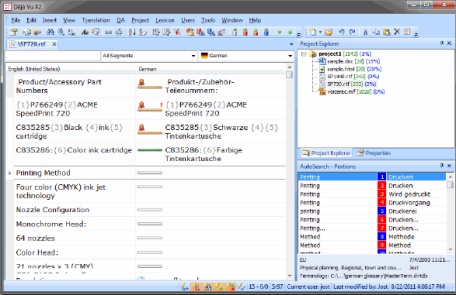
Interfaz de Déjà Vu X2
Además de la disposición del segmento original y el traducido, también es muy importante
la disposición de las ventanas de consulta a memorias de traducción y bases de datos
terminológicas. En general, la posición y tamaño de estas pantallas es totalmente
configurable. El usuario puede modificar el tamaño y la posición de estas ventanas
para ajustarlas a sus necesidades y preferencias.
2.2. Consulta a memorias de traducción
El sistema de traducción asistida debe permitir hacer consultas a una o más memorias
de traducción. El objetivo de la consulta es encontrar segmentos de la memoria que
sean iguales o similares al segmento que estamos traduciendo. Si encuentra un segmento
igual estamos hablando de una coincidencia exacta (exact match) y si el segmento es similar, hablamos de coincidencia parcial (fuzzy match).
Esta búsqueda de segmentos similares se hace tanto con los almacenados en la memoria
de traducción como con los traducidos anteriormente dentro del mismo proyecto. En
este caso hablamos de repeticiones internas.
El usuario puede ajustar la similitud mínima que debe tener un segmento para que aparezca
como coincidencia parcial. El sistema mostrará todas las coincidencias que tengan
una similitud igual o superior a la mínima establecida por el usuario, y en orden
descendente de similitud (es decir, empezando por la más parecida). Los sistemas de
traducción asistida, además, mostrarán en colores las diferencias entre el segmento
que estamos traduciendo y lo que aparece en la memoria (figura 5). Algunos sistemas, además, intentarán combinar fragmentos más pequeños presentes
en la memoria para hacer una propuesta de traducción a partir de las traducciones
de estos segmentos.
Figura 5.

Coincidencias parciales en OmegaT
En el capítulo siguiente, dedicado íntegramente a las memorias de traducción, veremos
con mayor detalle todos estos aspectos y muchos otros, como el concepto de indexación
de las memorias para una búsqueda rápida.
2.3. Consulta a glosarios y diccionarios
El sistema de traducción asistida también debe ser capaz de hacer consultas a glosarios
y diccionarios terminológicos. En este caso, cada segmento que estamos traduciendo
puede tener más de una entrada del glosario y se mostrarán todos los resultados. La
principal dificultad para la búsqueda en glosarios es hacer que sea capaz de encontrar
las entradas de manera independiente a la forma morfológica en la que se encuentre
el segmento original. Es decir, debe ser capaz de encontrar la entrada allergic reaction tanto si el texto se encuentra en singular como en plural (allergic reactions). Para lenguas morfológicamente más ricas, como por ejemplo el español, la tarea
se complica, ya que a veces el plural implica pluralizar todos los elementos (reacción alérgica >reacciones alérgicas) y, en otros casos, solo uno (letra de cambio > letras de cambio). En lenguas con una morfología mucho más rica todavía, el término puede aparecer
en el segmento en muchísimas formas (механическое напряжение, механического напряжения,
механические напряжения, механических напряжений, etc.) y todas deberían mostrar la
entrada correspondiente del glosario. Las diferentes herramientas de traducción asistida
pueden tener más o menos habilidad a la hora de tratar las variantes morfológicas
de los términos. En el capítulo 3, dedicado a las bases de datos terminológicas, profundizaremos
en este tema. En la figura 6 podemos ver la pantalla de terminología de OmegaT.
Figura 6.

Pantalla de terminología de la herramienta OmegaT
Algunas herramientas de traducción asistida también permiten la consulta automática
de diccionarios generales. Esta funcionalidad no es tan interesante para un traductor
profesional pero en ciertos casos puede resultar de utilidad. Como la consulta es
totalmente automática, si se dispone de esta funcionalidad y de un diccionario adecuado,
puede ser una buena idea activar esta opción en nuestros proyectos. En el caso de
OmegaT (figura 7), y dado que la información que aparece es muy extensa, si hacemos doble clic en
una determinada palabra, OmegaT muestra directamente la información asociada a esa
palabra.
Figura 7.

Consulta automática a un diccionario en OmegaT
2.4. Combinación de traducción asistida y traducción automática
Muchos sistemas de traducción asistida permiten hacer consultas a sistemas de traducción
automática (figura 8), por lo que además de presentar los resultados provenientes de una memoria de traducción
presentan también el resultado de traducir el segmento con un sistema de traducción
automática. Esta consulta a sistemas de traducción automática puede llegar a ser muy
productiva para algunos pares de lenguas, ya que buena parte de las propuestas pueden
aprovecharse haciendo algunos cambios mínimos. Esto suele suceder para pares de lenguas
suficientemente cercanas (catalán-español, español-francés, etc.). Si se utiliza esta
opción hay que tener mucho cuidado, ya que, por las prisas, tendremos tendencia a
aceptar como totalmente buenas algunas propuestas de traducción que no son del todo
correctas.
El capítulo 4 de este libro lo dedicaremos en su totalidad a la traducción automática
y volveremos a hablar con más detalle de esta combinación. En la figura 8 podemos observar la pantalla de Traducción automática de OmegaT en funcionamiento.
Figura 8.
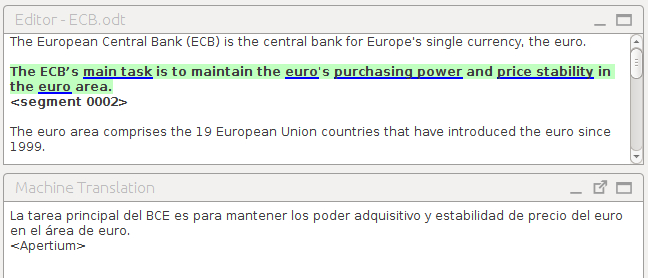
Traducción automática en OmegaT
2.5. Tratamiento de formatos
Los sistemas de traducción asistida deben ser capaces de tratar un conjunto variado
de formatos de archivo. Así, deben ser capaces de importar archivos generados por
procesadores de texto (Word, OpenOffice-LibreOffice), html, archivos propios de lenguajes
de programación, etc. El proceso de importación consistirá en seleccionar y mostrar
solo el texto que hay que traducir y ocultar el correspondiente a las marcas de formato.
Una vez traducido y revisado el proyecto, el sistema debe ser capaz de exportar la
traducción –es decir, crear los archivos traducidos que deben estar en el mismo formato
que el original.
Así, la herramienta de traducción asistida nos permitirá trabajar en un mismo entorno
con diversos formatos que requieren programas de edición específicos. En la tabla 1 ofrecemos algunos ejemplos de herramientas y formatos que pueden tratarse:
Tabla 1. Formatos tratados por diversos sistemas de traducción asistida
|
Herramienta
|
Formatos
|
|
OmegaT
|
Plain text, HTML, XHTML, StarOffice, OpenOffice.org, OpenDocument (ODF), MS Office
Open XML, Help & Manual, HTML Help Compiler (HCC), LaTeX, DokuWiki, QuarkXPress CopyFlow
Gold, DocBook, Android Resource, Java Properties, Typo3 LocManager, Mozilla DTD, Windows
RC, WiX, ResX, INI files, XLIFF, PO, SubRip Subtitles, SVG Images.
|
|
Open Language Tools
|
XLIFF, HTML, XHTML, XML, DocBook SGML, ASCII, StarOffice, OpenOffice, ODF, PO, .properties,
.java (ResourceBundle), .msg, .tmsg (catgets).
|
|
SDL Trados
|
Cuatro entornos de traducción: TagEditor, MSWord Interface, SDLX y SDL Trados Studio
2011. Cuenta además con filtros para traduir con TagEditor: Word, Excel, PowerPoint,
OpenOffice, InDesign, QuarkXPress, PageMaker, Interleaf, Framemaker, HTML, SGML, XML,
SVG, etc., e incluye SDL MultiTerm para la gestión terminológica, así como el Project
Management Dashboard para el seguimiento y la realización de tareas automatizadas.
|
|
Virtaal
|
XLIFF, PO y MO, TMX, TBX, Wordfast TM, Qt.ts, y muchos otros disponibles con Translate
Toolkit.
|
|
WordFast Classic
|
MS Word, Excel, PowerPoint (para Windows y Mac), así como documentos marcados.
|
El capítulo 5 de este libro lo dedicaremos íntegramente a aspectos técnicos relacionados
con el tratamiento de formatos.
3. El proceso de traducción con un sistema de traducción asistida
En este capítulo explicaremos el proceso genérico de traducción de un documento, o
proyecto de traducción, con un sistema de traducción asistida. Aprovecharemos en este
capítulo para hablar en profundidad algunos aspectos que no quedan recogidos en otros
capítulos: la segmentación, el formato SRX, el formato XLIFF para el intercambio de
proyectos de traducción y localización, y algunos aspectos relacionados con los correctores
ortográficos y gramaticales.
3.1. Tratamiento del formato
En nuestro proyecto de traducción deberemos tratar uno o más ficheros que estarán
en uno o más formatos informáticos. En la mayoría de los casos, la herramienta de
traducción asistida será capaz de tratar los formatos requeridos sin problemas, así
que este paso suele ser totalmente transparente para el traductor y lo lleva a cabo
sin más preocupaciones.
Sin embargo, en algunas ocasiones la herramienta de traducción asistida no será compatible
con el formato del archivo que tenemos que traducir. Un caso habitual es el tratamiento
del formato doc de Microsoft Word: no todas las herramientas de traducción asistida
pueden importarlo (OmegaT, por ejemplo, no es compatible). Hay que recordar que se
trata de un formato propietario y que, además, las herramientas compatibles con doc
suelen requerir que tengas Microsoft Word instalado en el sistema, una condición que
no se da siempre. En casos como estos, la solución es sencilla y funciona en la mayoría
de ocasiones: transformar el archivo doc en un archivo compatible (como el formato
ODF, empleado para LibreOffice y OpenOffice, y considerado como estándar por la ISO,
o bien el formato docx, de Microsoft). La conversión suele funcionar sin problemas.
Una vez finalizado el proceso de traducción, podrá hacerse la conversión inversa sin
mayores inconvenientes.
En otros casos más complejos, es posible que no exista un formato intermedio disponible
para nuestra herramienta de traducción asistida. En muchos de estos casos, la solución
pasará por la utilización del formato XLIFF (se describe en el apartado 3.3 de este
mismo capítulo). Muy probablemente existirá algún programa que pueda transformar el
formato en cuestión en este formato estándar, el XLIFF, que es compatible con la gran
mayoría de herramientas de traducción asistida.
3.2. Segmentación: el formato SRX
El proceso de segmentación consiste en dividir el texto de entrada en unidades de
un tamaño adecuado para presentarlas, una tras otra, al traductor. Las consultas a
los diferentes recursos, como por ejemplo las memorias de traducción, se harán en
estas unidades de texto. No conviene que estas unidades sean demasiado largas (por
ejemplo, un párrafo entero) porque la probabilidad de encontrar fragmentos iguales
o similares en la memoria de traducción es menor si el fragmento es largo. Tampoco
conviene que las unidades sean demasiado cortas (por ejemplo, una o dos palabras),
ya que la unidad y la coherencia del texto se romperían y haría imposible la traducción.
Así, la longitud ideal suele ser algo parecido a una frase u oración. A cada una de
estas unidades se les denomina segmento y al proceso de creación, segmentación. Ahora bien, las herramientas de traducción asistida no suelen incorporar demasiado
conocimiento lingüístico y por este motivo la segmentación se lleva a cabo a partir
de elementos textuales como signos de puntuación, presencia de caracteres en mayúsculas,
etc. Lo primero que se nos ocurre es segmentar por puntos (.), pero no siempre funciona,
tal como puede verse en el ejemplo siguiente:
El Sr. Martínez vendrá con el A.V.E. de las 15.30 h. Después se reunirá con el Dr.
Pérez en nuestro despacho de la Av. Diagonal.
Como podemos observar, una segmentación basada únicamente en puntos (.) produciría
una gran cantidad de segmentos, a saber:
El Sr.
Martínez vendrá con el A.
V.
E.
de las 15.
30 h.
Después se reunirá con el Dr.
Pérez en nuestro despacho de la Av.
Diagonal.
Las reglas de segmentación se suelen definir mediante expresiones regulares que definen
puntos de posibles cortes de segmentos y especifican si se debe producir el corte
o no.
Una
expresión regular (
regex) es una secuencia de caracteres que forma un patrón de búsqueda, principalmente utilizada
para la búsqueda de patrones de cadenas de caracteres u operaciones de sustituciones
(«Expresión regular»,
Wikipedia[])
Existe un lenguaje XML estándar para la definición de reglas de segmentación: el formato
SRX (Segmentation Rule eXchange). A continuación, mostramos un SRX muy simple, que solo define un par de reglas:
<?xml version="1.0" encoding="UTF-8"?>
<srx xmlns="http://www.lisa.org/srx20"
xmlns:okpsrx="http://okapi.sf.net/srx-extensions"
version="2.0">
<body>
<languagerules>
<languagerule languagerulename="default">
<rule break="no">
<beforebreak>([A-Z]\.){2,}</beforebreak>
<afterbreak>\s</afterbreak>
</rule>
<rule break="yes">
<beforebreak>\.</beforebreak>
<afterbreak>\s</afterbreak>
</rule>
</languagerule>
</languagerules>
</body>La primera de las reglas especifica que un conjunto de dos o más letras mayúsculas
seguidas de un punto y seguidas de un espacio corresponden a un punto donde no se
producirá un corte:
<rule break="no">
<beforebreak>([A-Z]\.){2,}</beforebreak>
<afterbreak>\s</afterbreak>
</rule>En cambio, esta segunda regla especifica que un punto seguido de un espacio sí constituye
un punto de corte:
<rule break="yes">
<beforebreak>\.</beforebreak>
<afterbreak>\s</afterbreak>
</rule>
Con ambas reglas, la segmentación se haría de la siguiente manera:
El Sr.
Martínez vendrá con el A.V.E. de las 15.30 h.
Después se reunirá con el Dr.
Pérez en nuestro despacho de la Av.
Diagonal.
Para segmentar correctamente el texto, deberíamos incorporar algunas reglas como estas:
<rule break="no">
<beforebreak>\b(Sr|Dr|Av)\.</beforebreak>
<afterbreak>\s</afterbreak>
</rule>
<rule break="yes">
<beforebreak>\bh\.</beforebreak>
<afterbreak>[A-Z]+</afterbreak>
</rule>
De este modo, conseguiremos un texto segmentado correctamente. Conviene tener en cuenta
que el orden de las reglas es significativo: si una regla ha producido un corte de
segmento, una regla posterior no lo deshará.
Ratel, una de las herramientas que se distribuye con el paquete
Okapi[] permite editar de manera fácil reglas de segmentación y probarlas sobre fragmentos
de texto (figura 9).
Figura 9.
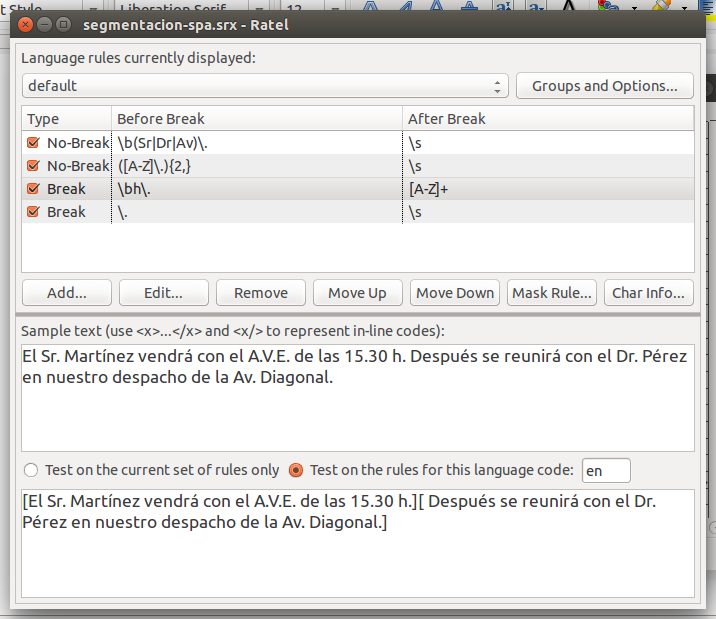
Ratel de Okapi: herramienta para la edición de reglas SRX
Afortunadamente, ya existen conjuntos de reglas para diferentes lenguas y el traductor
deberá intervenir muy poco sobre estas. Solo deberá añadir o eliminar alguna regla
en casos especiales.
La importancia del formato SRX radica en que permite un intercambio rápido de las
reglas. Para un mayor aprovechamiento de las memorias de traducción, conviene que
las reglas de segmentación que utilizamos para crear un proyecto sean las mismas que
las reglas que se utilizaron para crear el proyecto que ha generado la memoria de
traducción que queremos utilizar. De este modo, la probabilidad de encontrar segmentos
coincidentes aumentará significativamente.
3.3. Formatos de proyectos de traducción: el formato XLIFF
Cada herramienta de traducción asistida tiene un formato propio para almacenar los
proyectos de traducción. Algunas herramientas almacenan los proyectos como bases de
datos, donde en una determinada tabla guardan los segmentos a traducir y los segmentos
traducidos, la memoria de traducción ya indexada en otra tabla, etc. Otros formatos
incluyen también una estructura de carpetas y subcarpetas, donde en cada carpeta se
almacena cierta información (en una, los documentos traducidos; en otra, las memorias
de traducción; en otra, las bases de datos terminológicas, etc.).
Esta multiplicidad de formatos dificulta que un traductor con una determinada herramienta
pueda traducir proyectos de traducción creados con otra herramienta. Existe un formato
estándar para el intercambio de proyectos de traducción o localización: el XLIFF (XML Localisation Interchange File Format), basado también en XML. A continuación podemos ver un fragmento de un proyecto de
traducción en formato XLIFF:
<?xml version="1.0" encoding="UTF-8"?>
<xliff version="1.2" xmlns="urn: oasis: names: tc: xliff:
document:1.2" xmlns:okp="okapi-framework:xliff-extensions">
<body>
<trans-unit id="1" restype="x-text:p">
<source xml:lang="en">Only free resources available online
have been used.</source>
<target xml:lang="es">Únicamente se han utilizado recursos
libres disponibles en Internet.</target>
</trans-unit>
</body>
</xliff>
Como podemos observar, se trata de un proyecto de traducción que solo tiene un segmento
en inglés que ya está traducido al español. Si el proyecto estuviera sin traducir,
el segmento correspondiente al target estaría vacío o bien tendría copiado el segmento original.
La mayoría de herramientas de traducción asistida pueden traducir documentos XLIFF,
aunque no todas las herramientas son capaces de crear estos archivos. Pueden crearse
fácilmente proyectos de traducción en formato XLIFF con la herramienta
Rainbow, de
Okapi Tools[]. El
Translate Toolkit[] también proporciona herramientas para crear proyectos de traducción en este formato.
3.4. Asignación de recursos a un proyecto de traducción
Una vez creado un proyecto, hay que dotarlo de los recursos de consulta disponibles,
sobre todo memorias de traducción y bases de datos terminológicas. Traducir con un
sistema de traducción asistida sin recursos sirve de poco, aunque no es del todo inútil.
Normalmente, cuando empezamos a utilizar sistemas de traducción asistida, no disponemos
de recursos de consulta. En este caso, el sistema solo será capaz de ayudarnos si
dentro del proyecto hay alguna repetición, lo que se conoce como repeticiones internas. Además, una vez terminado el proyecto, ya habremos generado nuestra primera memoria
de traducción. Si además aprovechamos para ir recopilando la terminología a medida
que la encontramos en el texto, también iremos confeccionando nuestra primera base
de datos terminológica que podremos utilizar en proyectos futuros (figura 10).
Figura 10.
Pantalla de introducción de términos en OmegaT. Los nuevos términos se introducen
a medida que se realiza la traducción.
3.5. Traducción
Tras crear el proyecto y asignar los diferentes recursos, ya podemos empezar a traducir.
Como hemos comentado antes, es un buen momento para ampliar nuestras bases de datos
terminológicas. Las traducciones que hacemos se almacenarán automáticamente en una
memoria de traducción.
3.6. Revisión dentro de la herramienta de traducción asistida
Mientras vamos traduciendo, dispondremos de varias ayudas adicionales, como correctores
ortográficos y gramaticales. Una vez finalizado el proyecto, podemos llevar a cabo
diversas revisiones:
-
Una nueva corrección ortográfica y gramatical automática.
-
Una relectura a fondo de todo el proyecto.
-
Verificaciones automáticas de consistencia terminológica. Algunas herramientas permiten
verificar si los términos empleados en el proyecto coinciden con el contenido en las
bases de datos terminológicas asignadas.
-
Verificación automática de consistencia de etiquetas para asegurar que los documentos
finales aparecerán correctamente en su formato original.
La ventaja de efectuar la revisión dentro del sistema de traducción asistida es que
todos los cambios que hagamos se verán reflejados en las memorias de traducción generadas
en el proyecto. En cambio, es posible pasar por alto algún aspecto relacionado con
el formato final de los documentos.
3.7. Creación de los documentos traducidos
Una vez hechas las revisiones dentro de la herramienta de traducción asistida, ya
podremos generar los documentos finales. Estos programas son capaces de generar documentos
traducidos que mantienen el formato de los documentos originales.
Un caso especial son los proyectos que hemos creado en formato XLIFF con alguna herramienta
específica y los hemos traducido con alguna herramienta de traducción asistida. Por
ejemplo, creamos un proyecto en formato XLIFF con Rainbow, de Okapi Tools, y lo traducimos
con OmegaT. En este caso, cuando finalizamos el proyecto con OmegaT y creamos el fichero
traducido, obtendremos un XLIFF traducido que se tendrá que convertir en el formato
correspondiente al original utilizando de nuevo Rainbow.
3.8. Revisión en formato final
Es importante llevar a cabo una segunda revisión con los documentos traducidos en
el formato final. Además de detectar algún error que hubiese pasado inadvertido, podremos
ver si el formato plantea algún problema. Tan solo habrá que tener en cuenta un inconveniente:
los cambios que hagamos no se verán reflejados en las memorias de traducción generadas
en el proyecto. Si el error fuese grave, puede ser una buena idea entrar de nuevo
en el proyecto y efectuar la corrección pertinente para asegurarnos de que los cambios
aparezcan también en las memorias de traducción.
3.9. Gestión de los recursos generados
Durante la traducción se habrán generado dos recursos importantes: una memoria de
traducción y una base de datos terminológica. Tras finalizar el proyecto, es importante
gestionar correctamente estos recursos. La idea básica es conservarlos en un lugar
accesible y saber qué recursos podemos ulitilizar para cada nuevo proyecto. Según
la herramienta empleada, esta gestión de los recursos puede hacerse de una manera
diferenciada.
4. Los sistemas de traducción asistida
Hay una gran cantidad de herramientas de traducción asistida en el mercado. Muchas
aplicaciones, como por ejemplo OmegaT, son herramientas de software libre y se pueden
utilizar de manera libre y gratuita. Muchas otras, en cambio, son herramientas propietarias
que requieren la adquisición de algún tipo de licencia. Para obtener información actualizada
sobre las herramientas de traducción asistida existentes, recomiendo consultar dos
enlaces:
-
La página de Wikibooks dedicada a
CAT-Tools[].
-
5. Conclusiones
En este capítulo hemos presentado las principales funcionalidades de los sistemas
de traducción asistida por ordenador y hemos detallado las fases del proceso cuando
se utilizan este tipo de herramientas. En los próximos capítulos profundizaremos en
los principales recursos asociados a las herramientas de traducción asistida: las
memorias de traducción y las bases de datos terminológicas.
En el anexo de este mismo capítulo encontraremos información sobre herramientas de
traducción asistida en línea y comentarios sobre las ventajas e inconvenientes del
uso de este tipo de herramientas. También hay una ampliación del apartado referido
a las expresiones regulares para mejorar el uso del formato SRX a la hora de crear
reglas de segmentación. Por último, presentaremos un corrector gramatical libre, LanguageTool,
que puede integrarse en algunas herramientas de traducción asistida.
6. Anexo. Para ampliar conocimientos
6.1. Herramientas de traducción asistida en línea
Hasta hace relativamente poco, las herramientas informáticas de traducción asistida
por ordenador se instalaban en el ordenador del traductor y se ejecutaban desde este
mismo ordenador. En los últimos años, han aparecido algunas herramientas de traducción
asistida que funcionan remotamente en un servidor al que accedemos mediante un navegador
web.
Estas herramientas ofrecen la ventaja de que no requieren ningún tipo de instalación
y que tanto la herramienta como los archivos de trabajo están disponibles en línea
desde cualquier ordenador. Estas herramientas generalmente permiten un trabajo colaborativo
de una manera muy sencilla, simplemente compartiendo el proyecto de traducción entre
varias personas. De esta manera, todos los traductores pueden trabajar sobre el mismo
proyecto, añadir comentarios, hacer revisiones de partes realizadas por otro, etc.
El único inconveniente destacable es que, para usarlas, es imprescindible disponer
de una conexión a Internet y, si por algún motivo, la conexión falla, no podemos continuar
trabajando en el proyecto. Entre estas herramientas podemos destacar dos, ambas de
uso gratuito:
El uso de estas herramientas es bastante sencillo y no requieren de ninguna instalación,
por lo que son una buena solución en aquellos casos que no disponemos de una herramienta
instalada o en los casos que tengamos que colaborar con personas que no disponen de
ninguna herramienta.
Existen otras herramientas pensadas para agencias de traducción que permiten hacer
una gestión integral del proyecto vía web, desde su creación, hasta la traducción
y revisión de los archivos, incluida la selección de los colaboradores y la asignación
de tareas. Entre estas herramientas podemos destacar dos:
-
-
Memsource[], una herramienta propietaria de pago que tiene una versión limitada de uso gratuito
para traductores.
6.2. SRX y las expresiones regulares
Las reglas de segmentación en formato SRX se expresan mediante expresiones regulares,
lo que permite una gran flexibilidad en la definición de las reglas. Se puede consultar
la sintaxis de las expresiones regulares en las
especificaciones del formato SRX[].
6.3. El corrector gramatical LanguageTool
Un corrector ortográfico es capaz de detectar las palabras mal escritas en una lengua
comparándolas con las entradas de un diccionario de palabras existentes en la lengua
en el que figuran todas sus formas flexionadas.
Por ejemplo, cualquier corrector ortográfico del español es capaz de encontrar los
errores de la siguiente oración:
Cualquier corrector ortogafico del español puede detectar los erores de esta oracion:
En cambio, un corrector estrictamente ortográfico no encontrará el siguiente error:
Se a hecho un gran esfuerzo en el diseño de este corrector.
Ya que a debería escribirse con h al tratarse de una forma del verbo haber. Sin embargo, al ser a una palabra correcta en la lengua (aunque no en este contexto), el corrector ortográfico
no lo marca como error.
Los correctores gramaticales van más allá y permiten encontrar construcciones gramaticales
incorrectas. Por ejemplo, el corrector LanguageTool trataría el ejemplo anterior de
la siguiente manera (figura 11):
Figura 11.
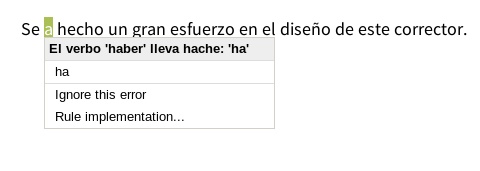
Error gramatical detectado por LanguageTool
Vemos que este corrector ha podido detectar que, en este caso, a debería escribirse con h, ya que corresponde a una forma del verbo haber.
La regla de LanguageTool que permite esta detección es la siguiente:
<rule id="A_PARTICIPIO" name="a + participio">
<pattern>
<token><exception inflected="yes" regexp="yes">
ol[oe]r|sab[e]r|gust(o|ar)|aroma|pest. +</exception>
</token>
<marker>
<token>a</token>
</marker>
<token postag="V[ASM]P00SM" postag_regexp="yes"/>
</pattern>
<message>El verbo 'haber' lleva hache:
<suggestion>ha</suggestion>
</message>
<short>El verbo «haber» lleva hache.</short>
<example correction="ha" type="incorrect">El atleta
<marker>a</marker> corrido de forma espectacular.
</example>
<example type="correct">El atleta <marker>ha</marker>
corrido de forma espectacular.
</example>
<example type="correct">Este bacalao huele
<marker>a</marker> pescado fresco.
</example>
</rule>No entraremos en detalles de implementación. Nos fijaremos solo en el hecho de que
la regla define un patrón (pattern) que en este caso consta de tres palabras (tokens). La primera define que, si el patrón se cumple, será una excepción a la regla (y
define palabras como oler, saber, gustar, aroma, peste, etc.). La segunda se refiere a la propia a mientras que la tercera corresponde a un verbo en participio que se define mediante
las etiquetas morfosintácticas. Si nos fijamos en los ejemplos que se dan al final
de la regla, entenderemos mejor la estructura.
A continuación, podemos observar la frase del ejemplo etiquetada por el etiquetador
de español integrado en LanguageTool:
<S> Se[se/P0000000,se/P03CN000,se/PP3CN000,]
a[a/NCFS000,a/SPS00,] hecho[hecho/NCMS000,hacer/VMP00SM,]
un[uno/DI0MS0,] gran[gran/AQ0CS0,] esfuerzo[esfuerzo/
NCMS000, esforzar/VMIP1S0,] en[en/SPS00,] el[el/DA0MS0,]
diseño[diseño/NCMS000,diseñar/VMIP1S0,] de[de/SPS00,]
este[este/DD0MS0,] corrector [corrector/AQ0MS0,corrector/
NCMS000,</S>,]
El corrector gramatical es capaz de etiquetar el texto que analiza (es decir, darle
a las palabras las etiquetas que expresan sus categorías gramaticales y algunas subcategorizaciones),
aunque no es capaz de desambiguar y asigna todas las etiquetas posibles.
LanguageTool[] es un corrector gramatical de código abierto que está disponible para más de veinte
lenguas, entre ellas el español, el catalán y el inglés. Los usuarios avanzados pueden
modificar las reglas o crear otras nuevas, de forma que el corrector mejora con el
paso del tiempo.
LanguageTool puede funcionar como una aplicación independiente y se integra perfectamente
en LibreOffice y OpenOffice, también se puede instalar como extensión de Firefox.
También es posible instalar LanguageTool en la herramienta de traducción asistida
OmegaT.
Bibliografía
Lippmann, E. O. (1971). «An approach to Computer-Aided Translation». En: IEE Transactions on Engineering Writing and Speech. (vol. EWS-14, n.º 1, febrero de 1971).