2
Los orígenes
2.1. nacimiento de una nueva disciplina métrica
La cibermetría, como cualquier otra disciplina métrica (bibliometría, econometría o biometría, entre algunas otras), se fundamenta en la cuantificación y posterior análisis de una serie de elementos, que constituyen su objeto de investigación. El objetivo de la medición no tiene otro cometido que el de conocer la naturaleza de estos elementos (cómo se crean, se difunden, desaparecen, y cómo se relacionan entre ellos).
Todo este conocimiento permitirá posteriormente predecir, con cierto margen de error, determinados efectos cuando se produzcan una serie de causas, lo que permitirá a su vez el desarrollo de multitud de aplicaciones industriales y servicios asociados.
El objeto clave de investigación en la cibermetría es cierto tipo de información (en concreto la información disponible en red), así como de otros elementos y recursos que permiten que esta información sea creada, difundida, consumida, almacenada o transmitida.
Por tanto, si deseamos rastrear los orígenes de esta incipiente disciplina científica (y sus diferentes aplicaciones comerciales), deberemos retroceder obligatoriamente en el tiempo hasta el momento en el que comenzó a existir información en red. Es decir, al instante en que se creó la red, o incluso antes de ese momento.
En el año 1961, dentro de las actividades de investigación e innovación llevadas a cabo por el Massachusetts Institute of Technology (MIT), se desarrolla un nuevo sistema denominado Compatible Time-Sharing System (CTSS)2, que permitía a distintos usuarios conectarse a un ordenador central (que incorporaba un sistema operativo IBM 7094) mediante terminales remotos por acceso telefónico, así como almacenar ficheros en línea en el disco duro.
De esta forma, los distintos usuarios podían compartir información entre ellos a partir del uso de directorios compartidos y nombres de ficheros con instrucciones (por ejemplo: “para Mike”). Los usuarios podían acceder al CTSS desde cualquier terminal, buscar el fichero creado por otro usuario, acceder a la información e imprimirlo si lo deseaban (Corbató, Merwin y Daley, 1962).
Este sistema, cuyas funcionalidades pueden parecer obvias o incluso risibles hoy día, suponían en su momento un gran avance tecnológico. Además de constituir un evidente precursor del correo electrónico (y otros sistemas posteriores de compartición y recuperación de información electrónica), su funcionamiento se basaba en la existencia de información “en línea”, compartida en red.
Este hecho abre por tanto la puerta a la realización de estudios cuantitativos orientados a medir la cantidad y forma de la información depositada en este formato. Es evidente que en aquellos momentos no existía una consciencia en cuantificar y analizar esta información (al menos no existe constancia de ello) y, dada la poca difusión que tuvo el sistema, no se estima que su uso generara grandes cantidades de información.
Sin embargo, la existencia del sistema CTSS (figura 1) supone en cierta forma la creación de un estado embrionario de “espacio red”, la piedra angular sobre la que gira la cibermetría (y que será tratado posteriormente en mayor profundidad), mucho antes de la invención de la Web (1989), e incluso de internet como red de redes en 1969 (Castells, 2001).
Obviamente, la aparición de internet supone el establecimiento “oficial” de un ciberespacio, constituido tanto por los discos duros de todos los ordenadores conectados a la red como por los canales de comunicación establecidos entre estos. El protocolo TCP/IP permitía la comunicación entre ordenadores mediante el envío de información dividida en diferentes paquetes de datos por los canales más adecuados según cada momento en función del tráfico en la red.
Sin embargo, supondría un error pensar que por el hecho de constituirse internet, la cibermetría, tal y como la conocemos hoy día, había nacido. En aquellos primeros años los esfuerzos de investigación se centraban fundamentalmente en los proveedores de infraestructuras (hardware) y en las aplicaciones y servicios (software); es decir, el interés se centraba en el desarrollo de tecnología.
Pese a que en la mayoría de los abundantes manuales que existen sobre la historia de internet3 se aborda la cuestión de que su invención tuvo unos fines militares en sus inicios (de hecho se desarrolló en el marco del proyecto ARPANET, financiado por el Departamento de Defensa de Estados Unidos), sus verdaderos creadores (informáticos e ingenieros en su mayor parte) siempre manifestaron que fue el espíritu científico el que verdaderamente les impulsó en su tarea; en la sensación de que estaban contribuyendo a la creación de algo realmente revolucionario (Castells, 2001). Por tanto, no es de extrañar que los principales fines de internet durante sus primeras décadas de vida fueran académicos:
- De manera directa para sus creadores, pues internet era un objeto de investigación y experimentación en sí mismo.
- De manera indirecta para el resto de la comunidad científica, que usaba la red para el establecimiento de comunicación informal entre colegas así como la compartición de información de interés científico.
Los cuatro primeros nodos interconectados fueron precisamente cuatro universidades: Universidad de California – Los Ángeles, Universidad de California – Santa Bárbara, Stanford Research Center Institute y Universidad de Utah (Castells, 2001).
Este uso meramente académico vino favorecido en gran parte por la “Política aceptable de uso (AUP)”4, mediante la cual se prohibía la utilización de internet para fines que no fueran de apoyo a la investigación y educación. Sin embargo, debido a la necesidad de soporte económico y a las presiones políticas, la AUP se anuló en 1992 a través de la denominada Scientific and Advanced-Technology Act, retirándose de esta manera la restricción al comercio en la red, lo que supuso definitivamente la creación y difusión masiva de información de todo tipo por internet (coincidiendo prácticamente este hecho con la creación de la World Wide Web (WWW), aunque la privatización del backbone de internet supuso una controversia con el mundo académico (Shah y Kesan, 2007).
Pese a que en el imaginario popular actual los términos “internet” y “web” aparecen prácticamente como sinónimos, nótese la importante diferencia temporal en sus fechas de creación (aproximadamente de 20 años). Es precisamente a partir del nacimiento de la Web en 1989 (Berners-Lee y Fischetti, 2000) y su rápida expansión (tanto en infraestructuras y usuarios como en contenidos) cuando se comienza a plantear seriamente la necesidad de establecer técnicas y procedimientos para cuantificar la información almacenada en red.
Así mismo, la evolución de los navegadores web, desde el pionero World Wide Web (creado por el propio Berners-Lee) hasta la aparición de los primeros navegadores gráficos como Erwise, ViolaWWW y muy especialmente Mosaic5 (que soportaba protocolos como FTP y Gopher), permitió la incorporación de interfaces gráficas a las herramientas de búsqueda de contenidos, enriqueciendo de este modo los servicios de información distribuidos a través de internet.
Sin embargo, tal y como apuntan Faba, Guerrero y Moya (2004), una parte importante de la literatura científica de la época se plantea todas estas necesidades con el mero objetivo de evaluar y normalizar el diseño de sitios web (usabilidad, arquitectura de la información, redacción de contenidos web, etc.), dado el floreciente negocio que iba a suponer (y que realmente supuso) la creación de páginas web durante aquellos primeros años de la era “web”. Por otra parte, las asociaciones y grupos dedicados al estudio, desarrollo y regulación de internet (y especialmente de la Web), centraban sus esfuerzos en establecer estándares para la creación y transmisión de contenidos y en el desarrollo y aplicación de algoritmos de recuperación de información en los incipientes motores de búsqueda de finales del siglo xx.
Precisamente, la aparición durante 1993-1995 de los primeros motores de búsqueda pretendidamente globales (como Lycos, webcrawler, Infoseek, Altavista o Excite)6, y la posibilidad de obtener ciertos indicadores generales a partir de estos (por ejemplo, el número de páginas totales indizadas por el buscador o número de resultados ante una consulta determinada), abren la puerta a la realización de los primeros análisis de naturaleza cuantitativa tal como los entendemos hoy día (figura 2).
La publicación de los ya clásicos artículos de Almind e Ingwersen (publicados entre 1996-1998) marcan un antes y un después dentro del desarrollo de la disciplina. Pese a existir diversos trabajos aislados previos, estos autores se plantean el estudio de la red desde un punto de vista informétrico.
De hecho, Almind deseaba originalmente analizar la tipología, contenidos y características de las páginas web nacionales danesas siguiendo los mismos métodos que seguían los análisis bibliométricos tradicionales (citado por Björneborn e Ingwersen, 2001; 2004), logrando de este modo una serie de hallazgos que resultarían fundamentales para el posterior desarrollo de la cibermetría:
- El análisis de los contenidos web de naturaleza científica revelaban resultados similares a los obtenidos mediante metodologías bibliométricas y cienciométricas.
- Los contenidos web (tanto científicos como de otra naturaleza) podían ser estudiados desde la óptica de la informetría, pues cumplían los principales patrones estadísticos de distribución de la información.
- Y, sobre todo, el espacio online suponía un reflejo (con cierto margen de error) de los acontecimientos que ocurrían offline. Es decir, los contenidos alojados en internet (y especialmente en la Web) se revelaban como un espejo de lo que ocurría en el mundo real.
Las posibilidades que las redes de comunicación presentaban para la cienciometría ya habían sido citadas anteriormente por Bossy (1995), quien indicaba que utilizando internet como instrumento de comunicación se podían descubrir y cuantificar los flujos de información establecidos entre los científicos, así como detectar y medir el grado de colaboración que existía entre ellos.
Otros estudios pioneros en esta línea fueron los aportados por Arnzen (1996) y Larson (1996), aunque ninguno de ellos tuvo el impacto de los trabajos de Almind, quien no pudo continuar con su labor investigadora al fallecer prematuramente en accidente de tráfico.
De forma complementaria y paralela, aparecieron otras áreas de trabajo, no directamente relacionadas con la cuantificación de los contenidos en red, pero sí con el estudio métrico de las estructuras de internet (McMurdo, 1996) así como de su topología, que llevan a la consideración de la red como un grafo (Abraham, 1997), donde la Web es comparada con una red neuronal conformada por nodos (se corresponden con los dominios, servidores y páginas) y conexiones (que se corresponden con los enlaces que se establecen entre los mismos). Igualmente se aplican las teorías del caos a series temporales de datos obtenidos de internet, en concreto a datos de tráfico de red o de datos de caché (Kugiumtzis y Boudourides, 1998).
2.2. Controversia en la comunidad
El desconocimiento de la naturaleza de la propia disciplina (todavía emergente) propicia, a partir de finales del siglo xx, un notable esfuerzo por parte de la comunidad científica en delimitar la cobertura del campo de trabajo así como de aportar una definición y terminología propia y precisa a este incipiente nuevo campo del saber.
Este apartado pretende reflejar de manera sencilla pero rigurosa los principales debates que se sucedieron (y que persisten en la actualidad) en torno a la cobertura y enfoque de la disciplina: ¿es internet el objeto de estudio?, ¿solo abarca el estudio de los contenidos?, ¿desde un punto de vista exclusivamente informétrico?
En los siguientes subapartados intentaremos responder –o al menos clarificar en la medida de lo posible– todas estas cuestiones.
2.2.1. Nomenclatura
Bossy (1995) es pionero al proponer el término “Netometrics” para definir a esta nueva área de trabajo, mientras que Abrahan (1996) utiliza por su parte el término “webometry” (ambos citados por Björneborn e Ingwersen, 2004).
Sin embargo, el verdadero impacto surge, como se ha comentado anteriormente, con el trabajo de Almind e Ingwersen (1996), quienes utilizan el término “internetometrics”, sustituyéndolo por “webometrics” posteriormente (1997), término que se expande rápidamente gracias en parte al impacto y a la cobertura de la prestigiosa revista que publica el artículo (Journal of documentation).
Ese mismo año aparece en España la revista Cybermetrics: international journal of scientometrics, informetrics, and bibliometrics7, publicada por Aguillo desde el Consejo Superior de Investigaciones Científicas (CSIC). Esta publicación es pionera por ser la primera (y prácticamente única) revista científica dedicada exclusivamente a esta disciplina, así como por su propuesta del término “Cybermetrics”.
Pese a esta circunstancia, diversos trabajos monográficos, precisamente españoles y publicados prácticamente a la par (Faba, Guerrero y Moya, 2004; Alonso, Figuerola y Zazo, 2004), coinciden en acuñar el término “Cybermetrics” a Shiri (1998), quien justamente se atribuye este mérito en su propio trabajo, posiblemente sin conocer la existencia de la revista, publicada muy poco tiempo antes.
Otros términos referidos posteriormente han sido los de “web bibliometry” (Chakrabarti et al., 2002), “webology” (publicación periódica editada por Noruzi a partir de 2004)8 y “web science”9, término propuesto por el propio creador de la Web (Berners-Lee et al., 2006), y cuyos objetivos van más allá del estudio informétrico de la WWW, planteando una aproximación holística (tanto desde un punto de vista tecnológico, como de su influencia e impacto en la política, economía y sociedad en general).
Una de las principales dificultades a la hora de decantarse por alguna de las nomenclaturas mostradas anteriormente es que cada una de ellas hace referencia a objetos de investigación y unidades de análisis diferentes. De hecho, el establecimiento y consenso en lo que se refiere a la cobertura de la disciplina ha constituido uno de los principales debates académicos, y probablemente una de las principales causas de su excesiva dispersión y escaso reconocimiento.
2.2.2. Cobertura
Los debates en torno al campo de acción de los estudios cibermétricos se pueden dividir en dos líneas diferentes. Por un lado el estudio de internet frente a la Web y, por otro lado, de los contenidos frente al resto de elementos constitutivos del ciberespacio. Veamos a continuación cada uno de estos debates así como sus implicaciones.
a) Internet frente a la Web
De toda la variedad de términos identificados anteriormente, se distinguen claramente dos líneas generales: la cibermetría y la webometría. El primer término, más amplio, hace referencia al estudio de todos los servicios ofrecidos a través de internet mientras que el segundo, más restringido, hace referencia solo al entorno web, como servicio particular accesible en red.
Estas definiciones vienen marcadas por la propia dificultad en definir y enmarcar el espacio de estudio. Pese a las propuestas terminológicas más o menos acertadas de netometrics o internetometrics, el término que más ha enraizado (sobre todo en España) ha sido el de cibermetría, debido fundamentalmente a la amplia difusión del vocablo “ciberespacio”.
Este término proviene del mundo de la literatura fantástica, de la mano del novelista William Gibson, quien acuña el término en la novela Burning Chrome (1982) y lo populariza con la novela Neuromancer (1984), sin duda influido por el concepto preexistente de “cibernética”10. A partir de entonces la difusión del término trasciende la literatura, generando amplios debates a nivel internacional11, conforme la propia red iba evolucionando y creciendo.
Para Flew (1995), el ciberespacio es un espacio de representación y comunicación, que existe completamente dentro de un espacio informático. No es real pues no puede localizarse espacialmente (espacio de representación), pero es real en sus efectos, pues en él se producen procesos de comunicación, de ahí la necesidad de establecer códigos de utilización (Lessig, 1999):
“Firstly, cyberspace describes the flow of digital data through the network of interconnected computers: it is at once not “real”, since one could not spatially locate it as a tangible object, and clearly ‘real’ in its effects. Secondly, cyberspace is the site of computer-mediated communication (CMC), in which online relationships and alternative forms of online identity were enacted, raising important questions about the social psychology of internet use, the relationship between ‘online’ and ‘offline’ forms of life and interaction, and the relationship between the ‘real’ and the ‘virtual’.” (Flew, 1995).
Bauwens (1994) se expresa de una forma similar al definir el ciberespacio como un espacio de posibilidades de computación interactivas, donde están disponibles los ordenadores y su contenido para los usuarios de cualquier ordenador, donde quiera que se encuentren.
En todas estas definiciones subyace el concepto de red de trabajo conjunta de todos los canales de comunicación y almacenes de información existentes, que conectan usuarios y máquinas12, del que se distinguen claramente las siguientes entidades: máquinas, usuarios, contenidos, almacén de datos y canales de comunicación.
Partiendo del concepto de ciberespacio, y teniendo presente que el aspecto clave de un estudio cibermétrico es el de “medir” la información disponible en internet, independientemente de las herramientas y protocolos de red que se utilicen para su distribución, surgen una serie de definiciones:
- Para Shiri (1998), el término cybermetrics se refiere al análisis, estudio y medición cuantitativa de todas las clases y de todos los medios de información que existen en el ciberespacio, aunque en ningún momento delimita este.
- Para Björneborn (2001), la cibermetría es la disciplina dedicada a la descripción cuantitativa de los contenidos y procesos de comunicación que se producen en el ciberespacio, acotando este como el conjunto de contenidos accesibles en formato electrónico.
Se observa como en esta última definición se parte de un concepto de ciberespacio más restringido que el citado por Bauwens anteriormente, que es apoyada y ampliada posteriormente por Aguillo (2002), para quien el ciberespacio también se entiende de forma general como el conjunto de contenidos disponibles en formato electrónico, aunque lo restringe a aquellos que son realmente “accesibles de forma unitaria”, en este caso a través de la red internet. Efectivamente, un contenido electrónico no tiene por qué estar accesible en red (imaginemos un contenido musical en una cinta antigua de casete magnético).
Björneborn e Ingwersen (2004) proponen posteriormente una nueva definición de cibermetría:
“El estudio de los aspectos cuantitativos de la construcción y uso de recursos de información, estructuras y tecnologías en toda la internet, sobre la base de enfoques bibliométricos e informétricos.”
Esta definición plantea un cambio de concepto respecto a las anteriores, pues ya no se delimita el ciberespacio a los contenidos alojados en este, sino al estudio del ciberespacio mediante técnicas fundamentalmente informétricas. Es decir, se acentúa el “método de análisis” en detrimento del “objeto de análisis”. Por ello, además de los contenidos, la definición introduce los términos de estructuras y tecnologías de todo internet. Esta visión más amplia del ciberespacio (y consiguientemente de la cibermetría) coincide en parte con los campos de actuación propuestos por Shiri (1998): las redes de información, el correo electrónico, la Web y los recursos electrónicos.
Por otra parte, la Web supone indudablemente un espacio importante del ciberespacio, y constituye el objeto de análisis de una gran parte de los estudios cibermétricos. En este sentido, el nombre más extendido a esta subdisciplina dentro de la cibermetría ha sido el término webometrics, propuesto originalmente por Almind e Ingwersen (1997), aunque su difusión en España (webometría) ha sido menos utilizado por razones cacofónicas, prefiriéndose el término general cibermetría.
Björneborn e Ingwersen (2004) y Thelwall, Vaughan y Björneborn (2005) proponen una definición ampliamente aceptada de webometría, basada en su definición de cibermetría:
“El estudio de los aspectos cuantitativos de la construcción y uso de recursos de información, estructuras y tecnologías en la web, sobre la base de enfoques bibliométricos e informétricos.”
Björneborn (2008) perfila posteriormente su definición teniendo en cuenta la popularización de la llamada web social, proponiendo el término “webometrics 2.0”:
“El estudio de los aspectos cuantitativos acerca de cómo los usuarios crean, distribuyen y utilizan los recursos web 2.0, las estructuras y tecnologías, sobre la base de enfoques bibliométricos e informétricos.”
Finalmente Thelwall (2009a) propone una nueva definición:
“El estudio de contenido basado en web fundamentalmente con métodos cuantitativos propios de la investigación en ciencias sociales, utilizando técnicas no específicas de ningún campo de estudio.”
Esta última definición da un paso adelante, y asume más enfoques (no solo más allá del bibliométrico, sino del informétrico), asumiendo el uso de métodos cuantitativos propios de las ciencias sociales. Esto lleva directamente a cuestionar la mayor o menor influencia de la informetría en la disciplina.
b) Contenidos frente a estructura
La definición anterior de Thelwall sobre webometría (extensible a cibermetría) abre un debate acerca del papel de la informetría.
- ¿Supone la cibermetría el estudio de los contenidos científicos accesibles en red, es decir,”cibercienciometría”?
- ¿Supone la cibermetría el estudio de todos los contenidos accesibles en red, es decir,”ciberinformetría”?
- ¿Supone la ciberbetría el estudio de todos los elementos que conforman la red, y no solo de los contenidos?
Björneborn e Ingwersen (2004) ilustran las interrelaciones entre estas y otras disciplinas (ver Figura 3) donde de manera coherente a sus definiciones sitúan a la Informetría como centro del sistema.
Figura 3. Relación entre las disciplinas cuantitativas de la información (I)
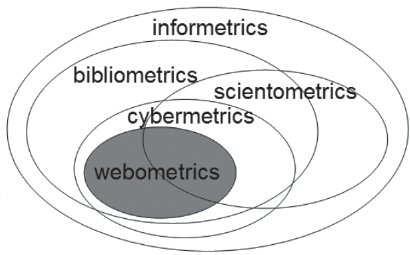
Fuente: Björneborn e Ingwersen (2004)
La justificación del rol jugado por la Informetría, se toma de la definición formal de esta disciplina, realizada por Tague-Sutcliffe (1992):
“El estudio de los aspectos cuantitativos de la información en cualquier forma, no solo registrada o bibliográfica, y en cualquier grupo social, no solo científico”.
Aun así, la aplicación de las leyes informétricas a internet genera debate en la comunidad científica. Por ejemplo, Egge (2000) indica que ésta es posible siempre que se produzcan dos condiciones: que haya una fuente (en la bibliometría lo son las revistas, autores, artículos) y un ítem a medir (en la bibliometría lo son los artículos, citas o referencias, etc.). Por ello, Aguillo (2009a) replantea las relaciones previamente establecidas por Björneborn, reduciendo el área de actuación de la informetría.
En cualquier caso, el gran dinamismo de la Web deja rápidamente obsoletos algunos de estos modelos. Por ejemplo, la aparición de las Altmetrics (que serán mencionadas en el capítulo 3.3.3) impacta directamente en las interrelaciones entre disciplinas, tal y como recientemente apunta Stuart (2014), quien las sitúa en plena intersección entre la Bibliometría, la Cienciometría y la cibermetría, en lo que supone una nueva propuesta de modelo de interrelaciones concéntricas al estilo de Björneborn, y donde la informetría gobierna todas las disciplinas métricas mencionadas anteriormente.
2.2.3. Definición de cibermetría
A partir de las definiciones expuestas en el apartado anterior, referidas al ciberespacio, a la cibermetría y la webometría, en este capítulo se propone una nueva aproximación, terminológica y conceptual, de la disciplina.
En primer lugar, se parte del concepto de “ciberespacio”. Como ha sido expuesto anteriormente, su relación con “cibernética” no resulta adecuada para expresar los objetivos reales de la disciplina, por lo que se opta por denominarlo simplemente “espacio red” (Netspace), en una clara analogía con el concepto de sociedad red (Castells, 1997).
Este espacio red queda compuesto por los siguientes elementos:
- Infraestructura física: ordenadores, servidores, hosts, etc.
- Infraestructura lógica: aplicaciones.
- Infraestructura de comunicación: routers, hubs, etc.
- Servicios: web, correo electrónico, listas de discusión, chat, etc.
- Contenidos: objetos digitales accesibles a través de la red.
- Usuarios (individuales o colectivos): demografía, uso de la información y relaciones sociales.
Con estas premisas se propone definir la cibermetría como:
“El estudio y caracterización del espacio red a partir del análisis de sus elementos constitutivos (especialmente en los aspectos relacionados con su creación, estructura, topología, difusión, interrelaciones, evolución, consumo e impacto) mediante técnicas cuantitativas de investigación social.”
Pese a que la definición propuesta destaca por ampliar la cobertura al análisis de todos los elementos del espacio red (número de servidores, número de usuarios, grado de utilización de un servicio, etc.), es evidente que el análisis métrico de los contenidos en red (especialmente los de naturaleza web) constituye el eje central de la disciplina.
Por esta razón, a partir de ahora –y salvo que se indique lo contrario– los siguientes capítulos (especialmente los dedicados a la tipología de indicadores web) se centrarán en el estudio de este elemento constitutivo (los contenidos), clave para los profesionales de la información.
2.3. Líneas de investigación
Considerando al espacio red como centro de gravedad desde donde pivota toda la disciplina, se propone un esquema de modelización, basado en la identificación de indicadores, perspectivas y áreas de trabajo (figura 4), desde el que se aborda su análisis métrico. Este esquema sirve asimismo como estructura expositiva de los contenidos de este libro.
Figura 4. Esquema de análisis integral de la cibermetría
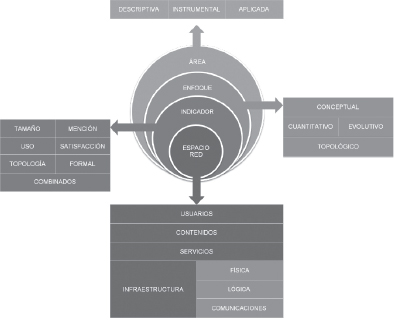
Si consideramos como centro de gravedad al elemento “Contenidos” del espacio red, se propone dividir la cibermetría en las siguientes áreas de trabajo:
Cibermetría descriptiva (descriptive cybermetrics)
Incluye el desarrollo teórico de la propia disciplina (y por consiguiente del espacio red), así como la definición y modelización de indicadores cibermétricos, el estudio de las unidades de medida y su interpretación.
Cibermetría instrumental (instrumental cybermetrics)
Estudio del funcionamiento, cobertura y limitaciones de las fuentes de información cibermétricas (principalmente robots y motores de búsqueda), y de los métodos de extracción, análisis y visualización de información.
Cibermetría aplicada (applied cybermetrics)
Estudio combinado de los indicadores cibermétricos en contextos específicos, tales como entidades, productos o temas, que incluyen condiciones de contorno, académicas, sociales, económicas, políticas, etc.
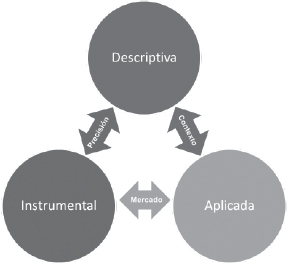
Las interacciones entre estas áreas se muestran de forma gráfica en la figura 5, donde se puede observar cómo la cibermetría descriptiva supone la base conceptual y teórica, mientras que la cibermetría instrumental le aporta precisión (mediante el testeo empírico de los indicadores y niveles de medida teorizados) y la cibermetría aplicada le aporta el contexto e interpretación.
Por otra parte, las interacciones entre la parte instrumental y aplicada se realizan en el marco de la existencia de un mercado profesional de trabajo.
Figura 5. Interrelaciones entre las diferentes líneas de trabajo
Los siguientes capítulos cubren de forma detallada cada una de estas ramas de la disciplina.

{kind=link}