FUNDAMENTOS DE LA BÚSQUEDA Y RECUPERACIÓN DE INFORMACIÓN
El primer paso para poder satisfacer de forma adecuada una necesidad informacional pasa necesariamente por entender en qué consisten y cuáles son los fundamentos del proceso de búsqueda y recuperación de información.
Para lograr este objetivo, a continuación intentaremos ofrecer una definición de este proceso y veremos cómo funcionan los sistemas que ayudan a las personas a buscar y recuperar la información que necesitan para poder resolver sus problemas o satisfacer sus necesidades informacionales.
Concepto de búsqueda y recuperación de la información
Técnicamente hablando, podemos definir el proceso de búsqueda y recuperación de información de la siguiente manera:
-
Es un proceso articulado y, en muchas ocasiones, retroalimentado;
-
que se inicia cuando una persona tiene un problema que quiere resolver mediante la obtención de cierta información;
-
que termina cuando la persona resuelve este problema con la información obtenida;
-
y que se implementa a través de la identificación y localización de los documentos que contienen esta información que es pertinente para satisfacer la necesidad de información de la persona.
Para poder acabar de entender esta definición, es necesario explicar algunos de los elementos y variables que intervienen en este proceso:
-
el usuario,
-
la necesidad de información,
-
la consulta,
-
los documentos,
-
la retroalimentación,
-
y las nociones de silencio y de ruido.
Empecemos con la figura del usuario. Por usuario podemos entender cualquier persona que tiene un problema en cualquier faceta de su vida (laboral, académica o personal) y que necesita una cantidad determinada de información para poder resolver ese problema.
Cualquiera de nosotros a lo largo del día, cuando buscamos en Internet la dirección de un restaurante para ir a cenar o cuando buscamos un libro en el catálogo de la biblioteca de nuestro barrio, somos claros ejemplos de usuarios.
Abordemos ahora la noción de necesidad de información. La necesidad de información se corresponde con el problema que tiene una persona (el usuario) y que se puede resolver con la obtención de la información adecuada.
Estrictamente hablando, una necesidad de información no es más que una clase especial de estado mental, de disposición neuronal en el cerebro, que actúa de guía en la conducta informacional del usuario. Siguiendo con los mismos ejemplos, no saber dónde está el restaurante al que tenemos que ir a cenar o no saber si el libro que estamos buscando se encuentra o no en la biblioteca de nuestro barrio son dos ejemplos de necesidad de información.
La consulta, en cambio, se puede identificar como la expresión o representación (oral o escrita) de una necesidad de información.
Los enunciados “¿Dónde está el restaurante al que tenemos que ir a cenar esta noche?” y “¿El libro que estamos buscando se encuentra en la biblioteca de nuestro barrio?” son ejemplos de consultas. Como veremos más adelante, relacionado con la noción de consulta aparece la noción de ecuación de búsqueda. Una ecuación de búsqueda es la traducción de la consulta al lenguaje de interrogación (lenguaje artificial que utilizamos para poder interaccionar con un tipo especial de sistemas de búsqueda y recuperación de información), la expresión de la consulta en este lenguaje artificial.
Pasemos ahora a ver qué es un documento. En términos generales, podemos afirmar que los documentos siempre se han visto involucrados en la actividad intelectual del ser humano. Desde el principio de la historia del pensamiento, el hombre ha utilizado una serie de objetos o materiales en los que poder plasmar y almacenar lo que pensaba o lo sentía. Las pinturas rupestres, las tablillas de arcilla mesopotámicas, los muros de los edificios sagrados egipcios, los papiros, los pergaminos o, posteriormente, el papel han sido claros ejemplos de este tipo de objetos o materiales. En la actualidad, con el desarrollo de las tecnologías de la información y la comunicación, se está apostando cada vez más por los formatos electrónicos para recoger nuestra producción intelectual. Para referirnos a todo este tipo de objetos o materiales utilizamos normalmente el término “documento”. O, dicho de otra manera, podemos identificar como documento todo soporte donde se represente algún tipo de información. En este sentido, podemos incluir bajo el concepto de documento una hoja de papel escrito, un libro, una fotografía, una cinta de vídeo, un DVD, un archivo creado con un procesador de textos, una base de datos o una página web.
Otra variable que debemos tener en cuenta en el proceso de búsqueda y recuperación de información es la retroalimentación. Este proceso no acostumbra a ser lineal, no acostumbra a tener un principio y un final claramente definidos. Lo que habitualmente suele pasar es que la satisfacción de una necesidad de información se alcanza cuando se repite varias veces el mismo proceso de búsqueda y recuperación. En este caso, cada vez que volvemos a repetir el proceso de búsqueda y recuperación tenemos en cuenta los resultados obtenidos con anterioridad y refinamos el propio proceso.
Así, por ejemplo, si tenemos la necesidad de indagar sobre la relación que existe entre la economía de un país y su red pública de educación, seguramente, en primer lugar, haremos una búsqueda en Internet. Si en esta búsqueda encontramos la referencia de un libro que habla sobre esta relación entre economía y educación, aprovecharemos para poner en marcha un segundo proceso de búsqueda en el catálogo de la biblioteca del barrio para ver si encuentran este libro. En definitiva, el proceso de búsqueda y recuperación de información puede considerarse como circular, retroalimentándose y refinándose a partir de los resultados obtenidos en cada búsqueda.
Para acabar de completar la definición del proceso de búsqueda y recuperación de información tenemos que introducir dos conceptos muy importantes: el de silencio y el de ruido.
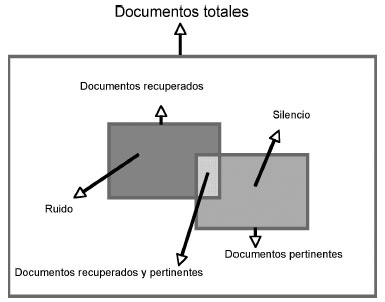
El proceso ideal de búsqueda y recuperación es aquel en el cual el silencio y el ruido son nulos o iguales a cero. Como puede verse en la figura 1, cuando hacemos una búsqueda se pueden distinguir diferentes grupos de documentos. Por una parte tendríamos los documentos totales susceptibles de ser recuperados, los documentos que dentro del total son pertinentes (sirven) para poder satisfacer la necesidad de información, y los documentos que acabamos recuperando con el proceso de búsqueda y recuperación.
El silencio sería el conjunto de documentos que son pertinentes (sirven) para poder satisfacer la necesidad de información pero que no hemos recuperado con nuestro proceso de búsqueda y recuperación. En cierta manera, el silencio = documentos pertinentes - documentos recuperados.
Así, por ejemplo, si hacemos una búsqueda en Internet con Google y este buscador no nos recupera un documento importante para poder satisfacer nuestra necesidad de información, este documento se puede considerar como un ejemplo de silencio.
El ruido, en cambio, estaría formado por los documentos que hemos recuperado con nuestro proceso de búsqueda y recuperación pero que no son pertinentes (no sirven) para poder satisfacer nuestra necesidad de información. En cierta manera, el ruido = documentos recuperados - documentos pertinentes.
Si hacemos una búsqueda con Google sobre el pintor holandés Van Gogh y nos recupera la página oficial del grupo musical vasco La Oreja de Van Gogh, esta página (este documento) se puede considerar como ejemplo de ruido.
Sistemas para la localización de información
Una vez que hemos visto cómo se puede entender el proceso de la búsqueda y recuperación de información, podemos abordar los sistemas para la localización de información.
En la mayoría de las ocasiones, cuando una persona tiene un problema o una necesidad de información no acostumbra a resolver o satisfacer esta necesidad de una forma autónoma sino que suele utilizar un sistema que le pueda ayudar a localizar la información que necesita dentro de un conjunto de documentos (un fondo documental).
Así, por ejemplo, si quiero indagar sobre la relación que existe entre la economía de un país y su red pública de educación, seguramente, utilizaré un buscador (como Google) para tratar de encontrar información en Internet o utilizaré el catálogo de una biblioteca para ver si encuentro información relacionada con este tema. Este buscador y el catálogo de la biblioteca se pueden considerar como ejemplos de sistemas para la localización de información.
Este sistema para la localización de información dentro de un fondo documental acostumbra a funcionar de la misma manera. Cada uno de los documentos que forman parte de este fondo se analiza para ver sobre qué temas tratan. Esta operación recibe el nombre técnico de indización.
Este análisis o indización se puede realizar de dos formas diferentes. Por un lado, se puede realizar de forma intelectual. En este caso, es una persona la que realiza este análisis interaccionando con el documento (leyéndolo, escuchándolo o visualizándolo) y decidiendo sobre qué temas trata. Por otro, este análisis se puede hacer de forma atomizada utilizando una herramienta informática. En este caso, la herramienta informática extrae los términos representativos del documento a partir de la frecuencia con la que aparecen y la localización de las palabras que forman parte de su texto.
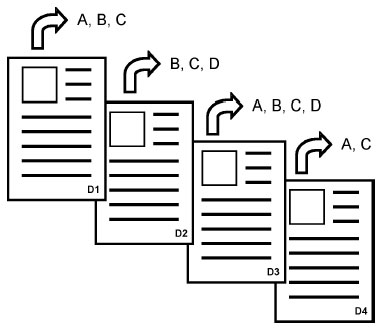
Como se muestra en la figura 2, si el fondo documental administrado por el sistema de localización está formado por cuatro documentos (D1, D2, D3 y D4), el resultado de la indización es la extracción, para cada uno de los cuatro documentos, de los términos (A, B, C o D) que representan sus contenidos. En este sentido, el documento D1 trata sobre los temas A, B y C; el documento D2 sobre los temas B, C y D; el documento D3 sobre los temas A, B, C y D; y el documento D4 sobre los temas A y C.
La indización se puede considerar como la parte común del funcionamiento de todos los sistemas de localización de información. Sin embargo, utilizando como criterio las operaciones que, además de la indización, completan estos sistemas que facilitan la localización, podemos distinguir dos tipos diferentes de sistemas: los sistemas de navegación y los sistemas de interrogación.
Sistemas de navegación
Los sistemas de navegación, una vez finalizada la operación de la indización, lo que hacen es construir una clasificación a partir de los términos extraídos. En muchas ocasiones se trata de una clasificación jerárquica, que incluye categorías más generales que agrupan categorías más específicas. Y, a partir de esta clasificación, lo que hacen es agrupar los documentos bajo cada una de las categorías que forman parte de esta clasificación.
Una vez que han hecho la distribución de los documentos bajo esta clasificación, para facilitar la localización al usuarios acostumbran a hacer una representación de la clasificación y de sus categorías de forma hipertextual (utilizando enlaces), de manera que, si el usuario busca información sobre el tema de una de las categorías de la clasificación, sólo tiene que hacer clic sobre la categoría y le aparecerán todos los documentos que tratan sobre este tema. Estos sistemas basados en una representación hipertextual de una clasificación se utilizan mucho para facilitar la localización de información en Internet y reciben el nombre técnico de directorios.
En la figura 3 mostramos un ejemplo de directorio: el directorio de Google. Como se puede comprobar, la clasificación está formada por catorce categorías principales (Artes y cultura, Ciencia y tecnología, etc.) de las que cuelgan varias subcategorías o categorías secundarías. Si un usuario necesita información sobre universidades, sólo tiene que apretar la categoría “Universidades” y le aparecerán documentos que tratan sobre este tema.
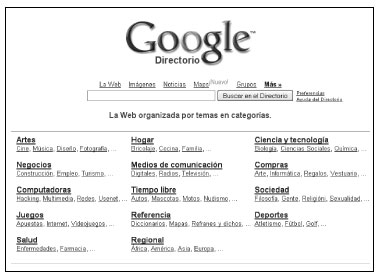
Es importante destacar que para intentar localizar información con este tipo de sistemas es necesario utilizar la técnica de la navegación (o exploración) (browsing, en inglés). En este caso, normalmente se escoge una categoría principal y se va haciendo clic sobre las categorías más específicas que cuelgan de ésta hasta llegar a la categoría que se corresponde con la necesidad de información del usuario y que alberga los documentos que pueden satisfacerla. Como se puede comprobar, se trata de un tipo de sistemas que requieren un importante esfuerzo intelectual por parte del usuario al obligarle a escoger categorías generales y específicas.
Tenemos que subrayar también que cada sistema utiliza sus propias categorías y sus propios niveles y estructuras jerárquicas. Están especialmente recomendados si el usuario busca información introductoria sobre un tema general que pertenece claramente a una de las categorías. Se utilizan sobre todo para gestionar colecciones documentales en las que las fuentes son muy estables (no cambian con el tiempo) y comparten patrones estructurales (se encuentran organizadas de la misma manera).
Sistemas de interrogación
Los sistemas de interrogación, en cambio, una vez finalizada la operación de la indización, lo que hacen es construir un documento a partir de los términos extraídos.
En este documento aparecen ordenados alfabéticamente los términos utilizados y, para cada uno de los términos, se presenta la relación de los documentos que han sido indizados con ese término. Este documento recibe el nombre técnico de índice (o índice inverso).
En la tabla 1 podemos observar cómo sería el índice derivado del sistema de interrogación. En la columna de la izquierda aparecen los términos utilizados en la indización: A, B, C y D. En la columna de la derecha aparecen los documentos indizados con cada uno de los términos. Así, por ejemplo, el término A ha sido utilizado para describir los documentos D1, D3 y D4; el B para representar los documentos D1, D2 y D3; el C para describir los documentos D1, D2, D3 y D4; y el D para representar los documentos D2 y D3.

Este índice inverso facilita enormemente la búsqueda y recuperación de información. Imaginemos que un usuario quiere localizar los documentos que tratan sobre el tema A. El sistema, para intentar ofrecer la información necesaria para satisfacer esta necesidad, no tendrá que abordar cada uno de los documentos y decidir si tratan o no el tema A. Esta estrategia consumiría un tiempo que quizás el usuario no tiene y, además, se tendría que repetir para cada demanda del usuario. Sino que, de una manera muy eficiente, irá directamente al índice inverso y, casi de forma instantánea, le podrá comunicar al usuario que los documentos D1, D3 y D4 son los que tratan sobre tema A.
Esta técnica de localización recibe el nombre técnico de interrogación (o recuperación). El usuario propone los temas sobre los que necesita información y el sistema le ofrece automáticamente aquellos documentos que indica el índice inverso. Esta técnica, al igual que la de los sistemas de navegación, exige un importante esfuerzo intelectual por parte del usuario al obligarle a proponer los temas sobre los que necesita información.
Los sistemas de interrogación, a diferencia de los de navegación, son especialmente útiles para localizar información que no pertenece claramente a una categoría concreta y se utilizan para gestionar fuentes de información dinámicas (que cambian con el tiempo) y poco estructuradas. Los sistemas de localización que utilizan una base de datos o los que utilizan los buscadores en Internet podrían ser ejemplos de sistemas de interrogación.