Capítulo II. La traducción automática
Introducción
Este capítulo está dedicado a la traducción automática (TA). La TA es una disciplina de la Lingüística Computacional con una larga tradición y abordable desde diversos puntos de vista (informático, lingüístico, empresarial, etc.). Aquí presentaremos una visión muy general de la disciplina y hablaremos de los aspectos que consideramos que debe conocer una persona neófita en tecnologías lingüísticas, que tiene un conocimiento básico de la existencia de la traducción automática o que esporádicamente la ha utilizado (por ejemplo, cuando ha traducido una página web con el traductor automático que ofrecen algunas páginas de búsqueda).
Objetivos
-
Tomar conciencia de las limitaciones de la TA pero también valorar su utilidad.
-
Conocer los distintos tipos de sistemas de TA y sus metodologías.
Contenido
1. Los mitos de la traducción automática
2. Las limitaciones de los sistemas de TA
2.1. Limitaciones que afectan a la inteligibilidad y la fidelidad
2.2. Limitaciones que afectan a la precisión
2.3. Limitaciones que afectan al estilo
3. Exigencias de la TA
4. Ventajas de la TA
5. Tipos de sistemas de TA
6. La TA y el software de libre distribución
7. Los servicios de traducción web gratuitos
1. Los mitos de la traducción automática
La traducción automática ha sido mitificada. Como siempre ocurre cuando se plantea la posibilidad de automatizar tareas humanas, mucha gente ha pronosticado que las máquinas reemplazarían a las personas y, por tanto, los traductores humanos se convertirían en una especie en extinción. En los inicios de la disciplina (a mediados de los años 50 y comienzos de los 60 del siglo XX) existía entre algunos especialistas en inteligencia artificial estadounidenses el convencimiento de que la tarea de la traducción se podría automatizar, y que existirían sistemas capaces de traducir cualquier texto. Evidentemente, no eran tan ingenuos como para pensar que podrían traducir obras de Shakespeare tal como lo haría un traductor humano, pero sí pensaban que podrían traducir textos técnicos con un buen nivel de calidad. Dado que las máquinas son más baratas de mantener que los traductores humanos y además pueden producir mucho más y en menos tiempo, la TA se perfilaba como una línea de investigación que podía ser aplicada para reducir los costes de traducción de las empresas, los organismos internacionales y los servicios de inteligencia militar.
Los resultados, sin embargo, no fueron tan buenos como se esperaba. En parte porque ni el software ni el hardware estaban todavía lo suficientemente desarrollados como para abordar la simulación de la actividad humana de la traducción, y en parte porque la traducción automática de calidad de cualquier texto implica crear sistemas capaces de reproducir procesos cognitivos tan extremadamente complejos que difícilmente se podrán crear nunca, por mucho que mejoren el software y el hardware. Estos procesos cognitivos requieren de un conocimiento lingüístico completo de las lenguas implicadas, de un conocimiento enciclopédico inabarcable, del sentido común, de mecanismos de inferencia lógica, de estrategias comunicativas, de mecanismos mentales de interpretación de un texto –con todas sus sutilezas: poder de evocación, sobrentendidos...– etc.
El informe del Automatic Language Processing Advisory Committee (ALPAC), de 1966, que versaba sobre las posibilidades de la TA a partir de la evaluación de los resultados de los sistemas existentes, fue demoledor. Recomendaba a los especialistas que no fueran tan optimistas y que se centraran en proyectos menos ambiciosos. El informe obligó a los especialistas a redefinir su disciplina, por lo que a partir de ese momento los teóricos y los desarrolladores de sistemas buscan y fomentan los aspectos beneficiosos de la TA y asumen sus limitaciones. Pero la gente corriente, que no tiene un conocimiento suficiente del tema como para tener en cuenta las limitaciones de los sistemas de TA, traducen textos propios, de cualquier tema, con motores de traducción disponibles en Internet, con la misma creencia ingenua que los resultados serán tan buenos como si el trabajo lo hubiese realizado un traductor humano. Cuando comprueban los resultados, se sienten muy decepcionados, si no es que incluso se ríen, y extienden otro mito, este de tipo totalmente negativo: el mito que la TA es inútil porque las traducciones muchas veces son absurdas.
2. Las limitaciones de los sistemas de TA
Para que los sistemas de TA sean aceptados por la gente corriente (que, en realidad son los usuarios potenciales a los q hay que convencer de su utilidad), es preciso, sin embargo, que se tenga un conocimiento previo de sus limitaciones.
A priori, las limitaciones de un sistema de TA afectan sobre todo a la calidad de la traducción, que se evalúa de acuerdo con los siguientes parámetros:
-
Inteligibilidad
-
Fidelidad
-
Precisión
-
Estilo
2.1. Limitaciones que afectan a la inteligibilidad y la fidelidad
Si un sistema de traducción automática no tiene una representación correcta y fiel del significado de la frase original es más que probable que la traducción no se entienda o sea absurda. Como hemos dicho anteriormente, la comprensión de una frase requiere de un conocimiento muy completo de la lengua origen, de unos mecanismos que procesen la información lingüística y de conocimiento del mundo contenidas en la frase, y una planificación inteligente de cómo se generará la frase en la lengua destino de la manera más adecuada para la situación comunicativa, el contexto del discurso donde se debe insertar, etc. Evidentemente, el procesamiento de todo ello tendría un enorme coste en tiempo y probablemente los recursos de memoria del sistema se colapsarían rápidamente. Pero ante todo, declarar todo el conocimiento lingüístico y del mundo es imposible. Las limitaciones son evidentes cuando comparamos la calidad de las traducciones entre un par de lenguas muy parecidas (catalán-castellano, por ejemplo) con las traducciones entre un par de lenguas muy diferentes (castellano-alemán). La calidad de las segundas es muy inferior.
La traducción automática suele realizarse frase a frase, sin que se tenga en cuenta la frase anterior ni la que viene a continuación (si se hiciera así, aumentaría el coste en memoria y en recursos del sistema). Evidentemente, el sistema tampoco sabe cuál es el hilo argumental del texto. Esto tiene consecuencias no tan sólo para la inteligibilidad sino también para la fidelidad de la traducción del texto original. En (1) se ilustra un problema de fidelidad causado por un error de concordancia pronombre-antecedente.
(1) the patient's leg was broken, so it was examined immediately => *la pierna del paciente estaba rota así que lo examinaron inmediatamente
No examinaron al paciente sino a su pierna.
2.2. Limitaciones que afectan a la precisión
Si, como hemos comentado anteriormente, los sistemas de TA no tienen una buena representación del significado del original, se pierde la expresión precisa en la lengua de llegada. Ahora bien, la precisión en la denominación de conceptos se puede mejorar mediante la consulta automática a bases de datos terminológicas de un dominio específico en el par de lenguas del sistema. No todos los sistemas de TA, sin embargo, permiten que los usuarios incorporen bases de datos terminológicas.
2.3. Limitaciones que afectan al estilo
Los sistemas no pueden tener en cuenta los efectos que la lectura de la traducción produce en el destinatario. No cambian, por ejemplo, los conectores discursivos (conectores como y) para evitar una lectura pesada y reiterativa. Hay que tener en cuenta también que el sistema es incapaz de captar el tono de un texto ni el deseo de su autor de dar énfasis o subrayar datos, opiniones, etc. Dado que es incapaz de captar todos estos aspectos, también lo es de verterlos en la lengua de llegada.
3. Exigencias de la TA
Las limitaciones de los sistemas implican una serie de exigencias para que éstos sean rentables. Comentaremos dos que nos parecen muy importantes.
-
Si el autor sabe que su documento se traducirá automáticamente, lo debería escribir utilizando oraciones cortas, con poca complejidad sintáctica, pocos pronombres, etc. Las empresas e instituciones que utilizan un sistema de TA suelen elaborar unas guías de estilo que los redactores han de seguir. Estas guías de estilo imponen una manera de escribir documentos que evita los aspectos no resueltos por el sistema. Esto supone realizar previamente una evaluación de la calidad lingüística del sistema y un informe de sus carencias y limitaciones.
-
Es necesaria una inversión que va más allá de la traducción en sí. Cualquier traducción realizada automáticamente se debe revisar. Aunque las dos lenguas sean muy parecidas y los sistemas generen traducciones muy aceptables, siempre afloran unos determinados puntos negros que no se habían previsto. Algunos de los fenómenos problemáticos van más allá del limitado conocimiento lingüístico del sistema y tienen un gran impacto en la traducción, a menos que ésta se haya revisado. En (2) presentamos algunos ejemplos de traducciones no revisadas hechas por un sistema de TA catalán-castellano/castellano-catalán.
Se dan también otros problemas más prosaicos, como los originados por palabras en formatos no reconocidos por el sistema (negrita, cursiva, etc.), por la presencia de códigos ocultos (por ejemplo un salto de línea) que distorsionan el análisis sintáctico de la frase original, las faltas ortotipográficas, etc.
Es necesario, por tanto, invertir en la preparación de los originales de manera que no se produzcan estos problemas (preedición) y también hay que invertir en la corrección de las traducciones por parte de un corrector humano (postedición).
4. Ventajas de la TA
Una vez conocidas las limitaciones y las exigencias de los sistemas de TA, es el momento de preguntarnos qué ventajas proporcionan. A continuación presentamos unas cuantas y comentamos algunas situaciones y proyectos que no se hubieran podido realizar sin la intervención de la traducción automática.
-
Los sistemas de TA permiten traducir grandes volúmenes de texto en un tiempo inferior a la traducción humana. Proyectos como la edición de la versión en catalán de El Periódico no serían factibles si no se llevaran a cabo con un sistema de TA. (13) Por otra parte, para organismos internacionales como la Comunidad Europea, que tiene que generar grandes volúmenes de documentos en muchas lenguas en un tiempo relativamente corto, la traducción automática se ha convertido también en una necesidad. Por esta razón la Comunidad financió el proyecto Eurotra, que consistió en la elaboración de un sistema capaz de traducir automáticamente su documentación en las lenguas oficiales de la Unión Europea.
-
La TA abarata costes cuando se trata de traducir periódicamente documentos escritos en un lenguaje controlado. Un documento está escrito en un lenguaje controlado si tiene unas estructuras sintácticas simples y rígidas, no es ambiguo, su léxico es restringido y tiene una fraseología establecida previamente. Algunos ejemplos son los manuales de electrodomésticos o las recetas de cocina. Con una representación no muy profunda del conocimiento lingüístico y del mundo (la estrictamente necesaria para la tarea) se obtienen traducciones de calidad aceptable y los costes de preedición y postedición son asumibles. Un sistema pionero en traducir textos controlados es Taum-Meteo (1971), desarrollado por la Universidad de Montreal, que traduce al francés informes meteorológicos en inglés.
-
La TA es la única opción si se quiere superar las barreras lingüísticas en la comunicación online. Si queremos chatear con alguien de Liverpool, que no conoce nuestra lengua (ni nosotros la suya), o nos tenemos que comunicar por e-mail con clientes árabes en árabe, el uso de una herramienta de TA resuelve los problemas de comunicación en una situación marcada por la inmediatez en el intercambio de información.
-
La TA también es la única opción posible cuando queremos comprender al momento las páginas web que nos presenta un buscador de Internet. A menudo el usuario tan sólo quiere tener una idea aproximada de su contenido, la suficiente como para poder seleccionar las páginas que realmente le interesan. Para ello, el usuario no tiene que esperar a que un traductor le asesore. La TA también es necesaria cuando queremos realizar consultas esporádicas a fuentes escritas en otras lenguas. Buscadores como Google o Altavista disponen de motores de traducción automática que traducen, si el usuario lo desea, las páginas web que ofrecen como resultado de la búsqueda. También están disponibles los portales de empresas como Systran, (14) WorldLingo, (15) InterNostrum (16) o Translendium (17) que ofrecen de forma gratuita la traducción de páginas web y textos cortos (hasta 1000 caracteres generalmente).
-
Es posible construir sistemas de traducción automática a medida. El usuario puede crear sus propios glosarios y diccionarios, y priorizar un sentido en el caso de que una palabra tenga más de una traducción posible según el dominio temático. Por ejemplo, si traducimos al español un texto inglés del dominio de la informática priorizaremos el sentido de la palabra chip que aparece en el glosario de informática por encima del sentido de la misma palabra en el vocabulario general (patata frita). También se pueden fijar registros (formales, no formales), formas verbales (forma de imperativo en la traducción de instrucciones), etc.
5. Tipos de sistemas de TA
Los sistemas de traducción automática se pueden dividir en dos tipos principales: Los sistemas con conocimiento lingüístico y los sistemas sin conocimiento lingüístico. Entre los primeros, tradicionalmente se distinguen los de traducción directa y los de traducción indirecta. Los sistemas de traducción directa traducen directamente a la lengua de llegada cuando disponen de suficiente información. Pueden sustituir las palabras originales por palabras de la lengua de llegada según las equivalencias de diccionarios bilingües y también generar la traducción según reglas sintácticas sencillas que establecen la posición de los constituyentes, las condiciones de concordancia (adjetivo-nombre, sujeto-verbo), la adición de nuevos elementos y otros aspectos gramaticales de la oración final. Estos sistemas son capaces de traducir grandes volúmenes de documentos en poco tiempo debido a que su motor no ejecuta procesos complejos y costosos. De todas maneras, dado que traducen sin haber analizado antes la frase entera, o dicho de otra manera, sin haberla entendido en su totalidad, generan muchas frases de baja calidad. Pero funcionan suficientemente bien si el usuario valora más la rapidez en proporcionar una idea general del contenido que la calidad de la traducción. Si se trata de lenguas muy próximas (catalán-castellano, por ejemplo) los resultados son bastantes espectaculares, considerando los recursos utilizados y la relativa sencillez del algoritmo del motor de traducción.
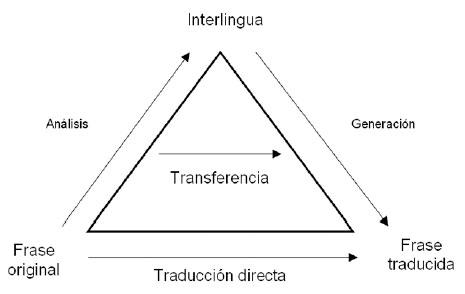
Por su parte, los sistemas de traducción indirecta tienen un módulo de análisis que construye una representación completa de la frase original en forma de árbol sintáctico. Si es posible construir un árbol sintáctico sin problemas podemos decir que el sistema ha entendido la frase, lo que da más garantías de que generará una traducción inteligible y fiel. A partir de esta representación sintáctica se crea una representación abstracta intermedia. La representación intermedia de los sistemas denominados de transfer es un árbol supralingüístico que le servirá de patrón al componente de generación de la oración tal y como se verá en el texto traducido, con todas las formas flexionadas. Decimos que es un árbol supralingüístico porque se crea según el conocimiento del sistema de las dos lenguas implicadas. La intervención del componente de transfer permite simplificar la construcción de sistemas para nuevos pares de lenguas. Por ejemplo, si es necesario construir un sistema alemán-español, el módulo de análisis del alemán será el mismo que el que utiliza el sistema alemán-inglés y el módulo de generación del español será el mismo que el del francés-español. El único componente que será necesario desarrollar será el de transfer entre el alemán y el español. En comparación con los de traducción directa, estos sistemas realizan procesos mucho más complejos y utilizan una información lingüística mucho más elaborada de las dos lenguas implicadas. Los resultados suelen ser mejores que los de la traducción directa.
Finalmente, tenemos los sistemas llamados de interlingua. Estos sistemas también llevan a cabo una representación intermedia, pero que no es de tipo gramatical sino conceptual. Esta representación, que supuestamente es común a todos los pares de lenguas (de ahí el término interlingua), se construye a partir del análisis de la frase original. Desde la representación conceptual, el componente de generación construye la frase en la lengua de llegada aplicando reglas de correspondencia entre el nivel conceptual y el lingüístico.
En la siguiente figura presentamos una representación del triángulo de Vaquois para ilustrar los sistemas de TA con conocimiento lingüístico.
Figura 2.1. Triángulo de Vaquois que representa los diferentes sistemas de TA con conocimiento lingüístico
Otros sistemas que no actúan según su conocimiento lingüístico son los llamados sistemas de TA estadísticos o estocásticos. Actualmente, la investigación en TA se ha centrado en estos sistemas porque los resultados obtenidos, sobretodo cuando se trata de lenguas cercanas, son muy prometedores y los costes en tiempo y dinero para construirlos son menores que los de un motor de traducción con conocimiento lingüístico. Según la TA estadística, la traducción consiste en buscar las palabras de la lengua de llegada que traducen mejor las palabras de la oración original y en encontrar la secuencia de estas palabras que es más adecuada para que sea una oración correcta en la lengua de llegada. Para hacer lo primero se utiliza un modelo de traducción, que indica la probabilidad de que una palabra sea la traducción de una palabra de la lengua de partida. Para hacer lo segundo, se utiliza un modelo de la lengua de llegada, que indica para cada secuencia de palabras de la lengua de llegada la probabilidad de que esta secuencia sea una oración bien formada en esta lengua. Para obtener los dos modelos es necesario disponer de un corpus paralelo [secuencia (una palabra u oración) en la lengua de partida, traducción en la lengua de llegada]. Estos corpus se denominan corpus paralelos. Para que los cálculos de las probabilidades sean significativos los corpus deben ser muy grandes.
6. La TA y el software de libre distribución
Dejando de lado su vertiente académica y de investigación, la TA ha sido promocionada porque puede obtenerse un rendimiento económico. Por esta razón, los sistemas normalmente se han creado para empresas o instituciones que los compran con el objetivo de mejorar su producción y reducir costes. Para los lingüistas, ha sido una puerta de entrada al mundo de la empresa, ya que han participado en proyectos cuyo objetivo es principalmente dar beneficios y han adoptado la mentalidad necesaria para convertir su capital intelectual en una fuente de ingresos.
La TA es también una tarea tan compleja y que implica tanta gente que aporte sus conocimientos, dedicación y esfuerzo que, evidentemente, hay que recuperar esta inversión económica en personal, además de la imprescindible inversión tecnológica. Por eso, hablar de programas de TA y software gratuito y de libre distribución puede parecer ilusorio. Pero no quiere decir que no los haya. Algunos sistemas de libre distribución se han creado con una motivación ética.
Un sistema de TA con esta motivación ética es Traduki (“traductor” en esperanto), un traductor automático de código fuente abierto multiplataforma que se ha construido porque sus desarrolladores consideran que todo el mundo tiene el derecho de expresarse en la lengua que quiera, y es una respuesta a la discriminación de muchas lenguas por no ser “rentables” económicamente. Así, además de traducir en lenguas como el inglés, Traduki incluye también lenguas de uso minoritario como el vasco. Se puede descargar desde http://sourceforge.net/projects/traduki/, pero está todavía en un estadio muy incipiente y su instalación no es demasiado intuitiva.
Más desarrollado está Linguaphile, un sistema similar al Traduki e inspirado por el mismo ideario. Además de lenguas como el inglés, el alemán o el francés, también trata lenguas como el búlgaro, el catalán, el danés, el irlandés y hasta un total de 56 lenguas. Se puede descargar de la página http://linguaphile. sourceforge.net/ y es un programa escrito en Perl, por lo que para utilizarlo se debe disponer de un intérprete de Perl. Las traducciones se dan con el indicador de órdenes, indicando el nombre del fichero que queremos traducir, la lengua de partida y la lengua de llegada. También se puede acceder a una demostración on line de este traductor en http://linguaphile.sourceforge.netcgi-bin/ translator.pl.
La buena voluntad que anima estos proyectos está por encima de la calidad de sus traducciones y, por lo tanto, no hay que tener demasiadas expectativas sobre los resultados que ofrecen.
El SALT, traductor del valenciano al castellano y viceversa, financiado por la Consejería de Cultura de la Generalitat Valenciana, es un ejemplo del interés de algunos organismos políticos por la TA porque la consideran un apoyo a la normalización del uso de una lengua. Se puede descargar de http:// www.cult.gva.es/salt/salt_programes_salt2.htm.
De entre todas las iniciativas de liberalización de la TA hay que destacar el proyecto de creación del motor de traducción del sistema Apertium. (18) El sistema Apertium es un sistema de traducción automática de código abierto para lenguas bastante próximas entre sí. Concretamente, los pares de lenguas que ofrece son el español-catalán, el español-gallego y el español-portugués, entre otros. La primera versión apareció en julio de 2005. Posteriormente se han añadido los pares de lenguas catalán-francés, aranés-catalán e inglés-catalán.
El sistema Apertium se basa en el sistema interNOSTRUM para el castellano-catalán, desarrollado por el grupo Transducens de la Universidad de Alicante, y en el traductor Universia para el castellano-portugués, desarrollado también por la Universidad de Alicante, ambos están disponibles en la red. (19) También se basa en el castellano-gallego desarrollado en el consorcio OpenTrad, (20) en el cual también se ha trabajado en un motor de traducción automática de código libre para el par castellano-vasco.
Además del hecho de tener gratuitamente un traductor automático para los pares de lenguas señalados, de esta iniciativa destacamos, por una parte, la posibilidad de desarrollar a partir de un motor básico motores para otros pares de lenguas o motores mejorados para un par de lenguas ya en funcionamiento, y por otra parte, y no menos importante, la posibilidad de adaptar los recursos del motor de traducción para otras finalidades, algo muy difícil de poder hacer en programas propietarios. Por ejemplo, la lista de todas las formas conjugadas y flexionadas de las palabras contenidas en el léxico del catalán puede utilizarse para elaborar un corrector ortográfico de esta lengua.
La adaptación de recursos de una herramienta de procesado del lenguaje natural para otra herramienta es también una característica de otras iniciativas de código abierto, como el paquete de procesamiento del lenguaje natural FreeLing, (21) desarrollado por el Departamento de Lenguajes y Sistemas Informáticos de la Universidad Politécnica de Cataluña. Por ejemplo, su etiquetador sintáctico y morfológico se puede utilizar para la recuperación de información o para la extracción automática de terminología.
La adaptación de los recursos de la TA a otros usos, el desarrollo libre del software básico y la posibilidad, inherente a la naturaleza del código abierto, de compartir recursos y ejecutarlos sin restricciones de software ni hardware, comporta necesariamente la codificación estándar de los datos lingüísticos. El formato básico es el XML, que tiene además la ventaja de ser muy fácil de procesar sea cual sea la finalidad, ya que los datos están perfectamente estructurados y organizados.
7. Los servicios de traducción web gratuitos
El propietario del módulo de traducción, si lo desea, puede implementar un servicio que permite que otras personas puedan aprovecharlo libremente. Esto es posible mediante un protocolo de comunicación entre la aplicación que solicita la traducción y el programa de traducción que reside en un servidor.
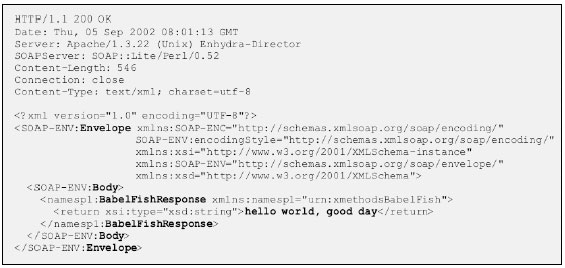
Un protocolo de peticiones y respuestas muy utilizado es el protocolo SOAP (Simple Object Access Protocol), que aprovecha los protocolos HTTP (HyperText Transfer Protocol) de transmisión de las peticiones de acceso a páginas web y de las respuestas de estas páginas. Las peticiones y las respuestas se transmiten en un formato estándar (el XML), como se muestra en las siguientes figuras. Algunos de los servicios de traducción web disponibles gratuitamente son el de interNOSTRUM y el de Babel Fish, que envía la traducción realizada por el motor de TA Systran.
No hemos dicho que estos servicios sean libres. En realidad, es el propietario del programa quien decide qué usuarios tienen la posibilidad de acceder al motor de traducción y si esta accesibilidad es gratuita o no. Excepto si existe la intención declarada de ofrecer el recurso libremente, como en el caso de interNOSTRUM, el acceso gratuito puede ser intermitente y siempre existe la posibilidad de que el propietario decida cerrar el acceso.
Petición al servicio de traducción de Babel Fish para que traduzca la frase alemana “Hallo Welt, Guten Tag”

Conclusiones
La TA no sustituirá a la traducción humana. Tiene unas limitaciones que difícilmente podrán ser superadas. Ahora bien, se debe reconocer que la traducción humana tiene unas limitaciones que la TA no tiene. Un traductor humano no traduce tan rápidamente cantidades ingentes de documentos ni siempre está disponible. Principalmente, la TA es de ayuda cuando hay que traducir muchos documentos en un corto periodo de tiempo. También es útil por su inmediatez, que permite un diálogo multilingüe en línea, la comprensión de páginas web en una lengua desconocida, etc.
Para ampliar conocimientos
La TA es una disciplina con muchísimos aspectos interesantes. Para profundizar, recomendamos la página web del profesor Joseba Abaitua, (22) de la Universidad de Deusto, un gran especialista en TA. Dicha página contiene una recopilación, muy bien organizada, de artículos y libros sobre diversas cuestiones relacionadas con este tema. El lector podrá buscar y escoger los aspectos que más le interesen.
Recomendamos especialmente el apartado dedicado a las publicaciones de John Hutchins (23) para tener una idea completa de la evolución histórica de la traducción automática y de sus posibilidades en el futuro. Entre los artículos de Hutchins, se pueden encontrar descripciones y análisis de los sistemas que están en funcionamiento en la actualidad.
También podéis consultar a las publicaciones del profesor de la Universidad de Alicante Mikel L. Forcada (24) sobre TA y la filosofía que subyace al traductor InterNOSTRUM.
A continuación tenéis unas referencias por si queréis saber más cosas sobre los proyectos de traducción automática de código abierto
Antonio M. Corbí-Bellot, Mikel L. Forcada, Sergio Ortiz-Rojas, Juan Antonio Pérez-Ortiz, Gema Ramírez-Sánchez, Felipe Sánchez-Martínez, Iñaki Alegria, Aingeru Mayor i Kepa Sarasola (2005) An open-source shallow-transfer machine translation engine for the romance languages of Spain, a Proceedings of the European Association for Machine Translation, 10th Annual Conference, Budapest, 2005, p. 79-86.
http://www.dlsi.ua.es/~japerez/pub/pdf/eamt2005.pdf
Carme Armentano-Oller, Antonio M. Corbí-Bellot, Mikel L. Forcada, Mireia Ginestí-Rosell, Boyan Bonev, Sergio Ortiz-Rojas, Juan Antonio Pérez-Ortiz, Gema Ramírez-Sánchez i Felipe Sánchez-Martínez (2005) An open-source shallow-transfer machine translation toolbox: consequences of its release and availability a OSMaTran: Open-Source Machine Translation, A workshop at Machine Translation Summit X, Phuket, Tailàndia. 2005
http://www.dlsi.ua.es/~mlf/docum/armentano05p.pdf
También podéis ampliar vuestros conocimientos sobre los sistemas de traducción automática disponibles en Internet consultando el artículo:
A. Oliver (2007) La traducció automàtica a Internet. Revista Tradumàtica n. 4 http://www.fti.uab.es/tradumatica/revista/num4/articles/07/07art.htm